
Explore our expert-made templates & start with the right one for you.
ETL Pipelines for Kafka Data: Choosing the Right Approach
-
 Eran Levy
Eran Levy
- Streaming Data
- March 4, 2022
If you’re working with streaming data, odds are you’re using Kafka – either in its open-source distribution or as a managed service via Confluent or AWS. The stream processing platform, originally developed at LinkedIn and available under the Apache license, has become pretty much standard issue for event-based data, spanning diverse use cases from sensors to application logs to clicks on online advertisements.
However, making that data useful means setting up some kind of extract-transform-load (ETL) pipeline to manage the data you’re bringing in from Kafka and to enable data scientists and analysts to query the data and extract insights. This article covers the basics of ETL for Kafka streams, and gives an overview of three basic approaches to building this type of pipeline.
Why do you need to ETL your Kafka data?
While Kafka functionality goes beyond traditional message brokers such as RabbitMQ (you can read our comparison between the two here), it is still essentially a stream processor that sends unstructured event data from A to B. This means that data in Kafka is unstructured and not optimized for reading, which in turn means that trying to run an SQL query on raw Kafka data will not end well.
Learn more: Apache Kafka Architecture: What You Need to Know
Hence the need for ETL: we must extract the data from Kafka or a staging environment, transform the raw JSON into structured data that can be easily queried, and then load the data into our database or analytics tool of choice.
Examples of Kafka ETL Scenarios
- Joining multiple streams: Companies might want to combine two different streams based on a common field. A typical example is in the retail space, where store data and employee data are often captured in two different event streams. An manager may want to review the most recent order and identify who was the last employee to work on it. Here’s what this join would look like in SQLake, Upsolver’s newest offering; note that in this example the refined data is written into Snowflake for further analysis:
- App analytics: Kafka is often used to capture user behavior in web or mobile apps (in the form of events such as page views, button clicks, bounces, and so on). This data is captured in real time but exploratory analysis is often done afterwards by business users – for example, the marketing team might want to understand which campaigns are suffering from a high rate of cart abandonment. This type of analysis would be done outside of Kafka and require transforming the raw event data into tables that can be queried, grouped, and aggregated with SQL.
- AI model training: Machine data can be used by data scientists to train AI models, such as for early fault detection in manufacturing. In these cases, sensor data might be piped through Kafka, and then later fed into a predictive model. In between these two stages, the schema-less streaming data would need to be converted into a database table or CSV file that data scientists can work with.
Learn more about Apache Kafka use cases.
What to expect from your ETL pipeline
ETL pipelines for Apache Kafka are uniquely challenging in that in addition to the basic task of transforming the data, we need to account for the unique characteristics of event stream data. Additionally, Kafka will often capture the type of data that lends itself to exploratory analysis – such as application logs, clickstream data, and sensor data, which are frequently used in data science initiatives. This creates another set of requirements as we often are unsure what exactly we will be doing with the data initially, or which parts of the data we will need and which we can discard.
With that in mind, you should look out for the following capabilities when building out your ETL flows:
- Read only new data: Kafka only caches the last few minutes’ worth of data in-memory, which means attempting to read ‘cold’ data from Kafka causes significant production issues – hence we need to ensure our pipeline is only processing new data.
- Replay without disrupting production: while we are only reading new data, we might still need to be able to ‘replay’ the events exactly as they were recorded (for example, to join with additional data or clean up data errors). In these cases we would like to have a copy of the raw data that we can easily ETL into our analytics tools without disrupting Kafka production.
- Support large amount of target outputs for the data: because Kafka supports such a broad range of business processes and use cases, we will want to maintain a similar level of flexibility when it comes to analyzing the data: developers might want to use Elasticsearch and Kibana, while data analysts might prefer working with tools such as Amazon Athena and Tableau.
The three paradigms for Kafka ETL
Now that we’ve defined the requirements, let’s look at the three most common approaches when it comes to building an ETL pipeline for Kafka data.
Conventional approach: Kafka to database, ETL on ingest

This is the traditional way to do ETL – data is transformed on ingest and outputted with new structure and schema to a database or data warehouse. In this case we’re treating Kafka as simply another data source, just as we would other organizational systems of record.
Pros: The main advantage of this type of pipeline is that we end up with structured data in a relational database – which is a very good place to be since databases are familiar and comfortable to work with. If your throughput in Kafka is fairly low this is probably the way to go.
Cons: Problems with this approach begin to appear as scale increases. Once you’re processing more than a few hundreds of events per second, you are likely to encounter scaling issues, including:
- Latency due to batch processing
- High costs of constantly writing new records to database storage, particularly in databases such as Amazon Redshift where storage and compute are closely coupled
- Loss of historical data due to the need to impose schema on write
Data lake approach: store raw event streams, ETL on output
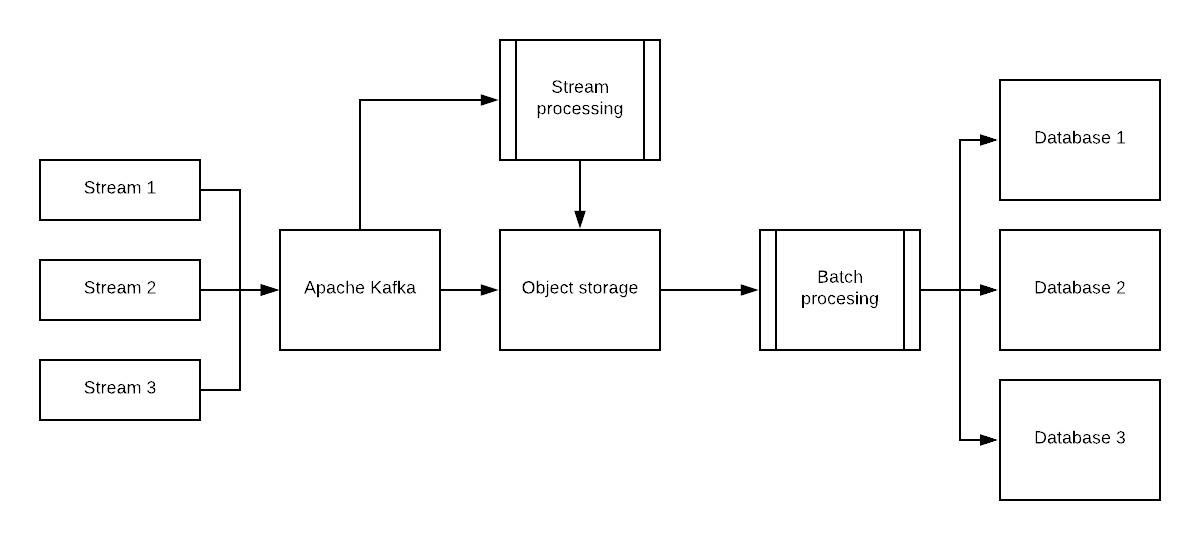
In this approach we are foregoing schema-on-write and storing the raw Kafka data in object storage (such as Amazon S3), while performing batch and stream ETL on read and per use case using tools such as Upsolver or Spark Streaming.
Pros:
- Inexpensive, infinitely scalable storage
- Historical data is readily available for replay purposes
- Ability to support a broad range of use cases, including real-time
Cons:
- Data lake architectures are often complex and require data engineers to orchestrate many moving parts. You can circumvent this issue by using a self-service streaming data platform.
ETL in Kafka
A third option is to transform the data while it is stored in your Kafka cluster, either by writing code or using something like KSQL, and then run your analytics queries directly in Kafka or output the transformed data to a separate storage layer.
We’ve covered the topic of reading data directly from Kafka in a previous article on this topic, and you can read the details there if you’re interested. In a nutshell, this can be a good fit for use cases that require looking at smaller chunks of data, such as real-time monitoring. However, at higher scales and larger timeframes, if you keep all your data in Kafka you’ll encounter the same issues, and more severe issues, as you would using a relational database in terms of storage costs and performance.
Batch or Stream ETL for Kafka?
Batch ETL is the traditional approach to ETL, in which data is extracted from a source system on a schedule, transformed, and then loaded into a repository. Streaming ETL is a newer approach in which data is extracted from a source system in real time as it is generated, transformed, and then loaded into a repository.
Streaming ETL is often used for applications that require real-time data, such as fraud detection, streaming analytics, and real-time payment processing.
Kafka data is by definition streaming and ephemeral, but it can still be stored and processed in batches. However, for use cases that require fresh data, it’s usually unacceptable to “wait” for the next ETL batch to happen and so the tendency would be towards streaming ETL. This could include situations where a data-driven decision needs to be made automatically in <1 second, such as fraud detection, but applies equally to any case where data freshness needs to be <1 hour, such as website operational outages.
Learn more about streaming ETL pipelines.
Learn more about ETL and Analytics for Kafka Data
- Check out our previous article on Apache Kafka with or without a Data Lake
- Learn how to improve Amazon Athena performance when querying streaming data
- Talk with one of our data experts about modernizing your streaming data architecture
Try SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free for 30 days. No credit card required.
Visit our SQLake Builders Hub, where you can read learn more about how SQLake works, read technical blogs that delve into details and techniques, and access additional resources.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
Published in:
Blog
,
Streaming Data