
Explore our expert-made templates & start with the right one for you.
Apache Kafka Use Cases: When To Use It? When Not To?
-
 Jerry Franklin
Jerry Franklin
- Streaming Data
- January 15, 2023
This piece is taken from our detailed, 40-page eBook “The Architect’s Guide to Streaming Data and Data Lakes.” Read it to discover insights into design patterns and best practices when using Kafka, or download the complete [Free] eBook for thorough comparisons of tools, detailed case studies, and much more extensive information.
What makes Apache Kafka probably the most common tool for working with streaming data? According to the Apache Software Foundation, more than 80% of all Fortune 100 companies use Kafka. This article discusses Kafka’s key aspects and components, what Kafka is used for, and follows with the best scenarios for deploying Kafka.
If you need to transform data being sourced from Kafka, consider Upsolver SQLake, an all-SQL data pipeline platform that lets you just “write a query and get a pipeline” for data in motion, whether in event streams or frequent batches. SQLake automates everything else, including orchestration, file system optimization and infrastructure management. To give it a try you can execute sample pipeline templates, or start building your own, in Upsolver SQLake for free.
What is Apache Kafka?
Apache Kafka is an open-source streaming data platform originally developed by LinkedIn. As it expanded Kafka’s capabilities, LinkedIn donated it to Apache for further development.
Kafka operates like a traditional pub-sub message queue, such as RabbitMQ, in that it enables you to publish and subscribe to streams of messages. But it differs from traditional message queues in 3 key ways:
- Kafka operates as a modern distributed system that runs as a cluster and can scale to handle any number of applications.
- Kafka is designed to serve as a storage system and can store data as long as necessary; most message queues remove messages immediately after the consumer confirms receipt.
- Kafka handles stream processing, computing derived streams and datasets dynamically, rather than just passing batches of messages.
See also: Kafka vs RabbitMQ
What is Kafka used for?
Kafka is a stream processing system used for messaging, website activity tracking, metrics collection and monitoring, logging, event sourcing, commit logs, and real-time analytics. It’s a good fit for large scale message processing applications since it is more robust, reliable, and fault-tolerant compared to traditional message queues.
Open-source Kafka or managed distributions are ubiquitous in modern software development environments. Kafka is used by developers and data engineers at companies such as Uber, Square, Strave, Shopify, and Spotify.
Watch Upsolver CEO Ori Rafael discuss how Kafka data is stored and analyzed in user activity and sensor data scenarios:
(This is an excerpt from our recent joint webinar with AWS, which you can watch for free here)
What are the Core Concepts of Apache Kafka?
So how does Kafka work? Broadly, Kafka accepts streams of events written by data producers. Kafka stores records chronologically in partitions across brokers (servers); multiple brokers comprise a cluster. Each record contains information about an event and consists of a key-value pair; timestamp and header are optional additional information. Kafka groups records into topics; data consumers get their data by subscribing to the topics they want.
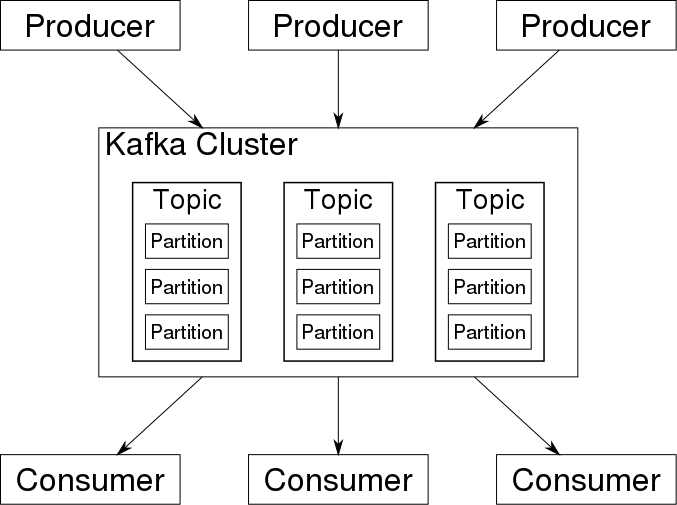
Let’s examine each of these core concepts in more detail.
Events
An event is a message with data describing the event. For example, when a new user registers with a website, the system creates a registration event, which may include the user’s name, email, password, location, and so on.
Consumers and Producers
A producer is anything that creates data. Producers constantly write events to Kafka. Examples of producers include web servers, other discrete applications (or application components), IoT devices, monitoring agents, and so on. For instance:
- The website component responsible for user registrations produces a “new user is registered” event.
- A weather sensor (IoT device) produces hourly “weather” events with information about temperature, humidity, wind speed, and so on.
Consumers are entities that use data written by producers. Sometimes an entity can be both a producer and a consumer; it depends on system architecture. For example, a data warehouse could consume data from Kafka, then process it and produce a prepared subset for rerouting via Kafka to an ML or AI application. Databases, data lakes, and data analytics applications generally act as data consumers, storing or analyzing the data they receive from Kafka.
Kafka acts as a middleman between producers and consumers. You can read our previous post to learn more about Kafka and event-driven architecture.
Brokers and Clusters
Kafka runs on clusters, although there is now a serverless version of Kafka in preview at AWS. Each cluster consists of multiple servers, generally called brokers (and sometimes called nodes).
That’s what makes Kafka a distributed system: data in the Kafka cluster is distributed amongst multiple brokers. And multiple copies (replicas) of the same data exist in a Kafka cluster. This mechanism makes Kafka more stable, fault-tolerant, and reliable; if an error or failure occurs with one broker, another broker steps in to perform the functions of the malfunctioning component, and the information is not lost.
Topics
A Kafka topic is an immutable log of events (sequences). Producers publish events to Kafka topics; consumers subscribe to topics to access their desired data. Each topic can serve data to many consumers. Continuing with our example, the registration component of the website publishes “new user” events (via Kafka) into the “registration” topic. Subscribers such as analytics apps, newsfeed apps, monitoring apps, databases, and so on in turn consume events from the “registration” topic and use it with other data as the foundation for delivering their own products or services.
Partitions
A partition is the smallest storage unit in Kafka. Partitions serve to split data across brokers to accelerate performance. Each Kafka topic is divided into partitions and each partition can be placed on a separate broker.
Easily Ingest Data from Kafka using SQLake
If you’re thinking of using Apache Kafka, SQLake can make it really easy to get your data into Kafka. Here’s an example of how to do it:
Create your staging table:
CREATE TABLE default_glue_catalog.upsolver_samples.orders_raw_data() PARTITIONED BY $event_date;
Next, you can create a COPY FROM job as follows:
CREATE SYNC JOB "extract data from kafka"<br>START_FROM = BEGINNING<br>CONTENT_TYPE = JSON<br>AS COPY FROM KAFKA upsolver_kafka_samples <br>TOPIC = 'orders' <br>INTO default_glue_catalog.upsolver_samples.orders_raw_data;<br>COMMENT = 'Load raw orders data from Kafka topic to a staging table';
Best Apache Kafka Use Cases: What is Kafka Used for?
Let’s look at the most common use cases of Apache Kafka.
Activity tracking
This was the original use case for Kafka. LinkedIn needed to rebuild its user activity tracking pipeline as a set of real-time publish-subscribe feeds. Activity tracking is often very high volume, as each user page view generates many activity messages (events):
- user clicks
- registrations
- likes
- time spent on certain pages
- orders
- environmental changes
- and so on
These events can be published (produced) to dedicated Kafka topics. Each feed is available for (consumed by) any number of use cases, such as loading into a data lake or warehouse for offline processing and reporting.
Other applications subscribe to topics, receive the data, and process it as needed (monitoring, analysis, reports, newsfeeds, personalization, and so on).
Example scenario: An online e-commerce platform could use Kafka for tracking user activities in real-time. Each user activity, such as product views, cart additions, purchases, reviews, search queries, and so on, could be published as an event to specific Kafka topics. These events can then be written to storage or consumed by in real-time by various microservices for recommendations, personalized offers, reporting, and fraud detection.
Real-time data processing
Many systems require data to be processed as soon as it becomes available. Kafka transmits data from producers to consumers with very low latency (5 milliseconds, for instance). This is useful for:
- Financial organizations, to gather and process payments and financial transactions in real-time, block fraudulent transactions the instant they’re detected, or update dashboards with up-to-the-second market prices.
- Predictive maintenance (IoT), in which models constantly analyze streams of metrics from equipment in the field and trigger alarms immediately after detecting deviations that could indicate imminent failure.
- Autonomous mobile devices, which require real-time data processing to navigate a physical environment.
- Logistical and supply chain businesses, to monitor and update tracking applications, for example to keep constant tabs on cargo vessels for real-time cargo delivery estimates.
Example scenario: A bank could use Kafka for processing transactions in real-time. Every transaction initiated by a customer could be published as an event to a Kafka topic. Then, an application could consume these events, validate and process the transactions, block any suspicious transactions, and update customer balances in real-time.
Messaging
Kafka works well as a replacement for traditional message brokers; Kafka has better throughput, built-in partitioning, replication, and fault-tolerance, as well as better scaling attributes.
Example scenario: A microservices-based ride-hailing app could use Kafka for sending messages between different services. For example, when a rider books a ride, the ride-booking service could send a message to the driver-matching service through Kafka. The driver-matching service could then find a nearby driver and send a message back, all in near-real time.
Operational Metrics/KPIs
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Example scenario: A cloud service provider could use Kafka to aggregate and monitor operational metrics from various services in real-time. For example, metrics such as CPU utilization, memory usage, request counts, error rates, etc. from hundreds of servers could be published to Kafka. These metrics could then be consumed by monitoring applications for real-time visualization, alerting, and anomaly detection.
Log Aggregation
Many organizations use Kafka to aggregate logs. Log aggregation typically involves collecting physical log files off servers and placing them in a central repository (such as a file server or data lake) for processing. Kafka filters out the file details and abstracts the data as a stream of messages. This enables lower-latency processing and easier support for multiple data sources and distributed data consumption. Compared with log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
Example scenario: An enterprise with a large distributed system could use Kafka for log aggregation. Logs from hundreds or thousands of servers, applications, and services could be published to Kafka. These logs could then be consumed by a log analysis tool or a security information and event management (SIEM) system for troubleshooting, security monitoring, and compliance reporting.
You may also wish to consult the Kafka project use case page on the Apache Software Foundation website for more on specific deployments.
When Not To Use Kafka
Given Kafka’s scope and scale it’s easy to see why you might consider it something of a Swiss army knife of big data applications. But it’s bound by certain limitations, including its overall complexity, and there are scenarios for which it’s not appropriate.
“Little” Data
As Kafka is designed to handle high volumes of data, it’s overkill if you need to process only a small amount of messages per day (up to several thousand). Use traditional message queues such as RabbitMQ for relatively smaller data sets or as a dedicated task queue.
Streaming ETL
Despite the fact that Kafka has a stream API, it’s painful to perform data transformations on the fly. It requires that you build a complex pipeline of interactions between producers and consumers and then maintain the entire system. This requires substantial work and effort and adds complexity. It’s best to avoid using Kafka as the processing engine for ETL jobs, especially where real-time processing is needed. That said, there are third-party tools you can use that work with Kafka to give you additional robust capabilities – for example, to optimize tables for real-time analytics.
Summing up Kafka’s Use Cases
Kafka’s power and flexibility are key drivers of its popularity. It’s proven, scalable, and fault-tolerant. Kafka is particularly valuable in scenarios requiring real-time data processing and application activity tracking, as well as for monitoring purposes. It’s less appropriate for data transformations on-the-fly, data storing, or when all you need is a simple task queue. In those cases you can use tools that leverage Kafka (or other streaming technologies such as Amazon Kinesis).
How Data-Intensive Companies Use Upsolver to Analyze Kafka Streams in Data Lakes
ETL pipelines for Apache Kafka can be challenging. In addition to the basic task of transforming the data, you also must account for the unique characteristics of event stream data. Upsolver’s declarative self-orchestrating data pipeline platform sharply reduces the time to build and deploy pipelines for event data. Using declarative SQL commands enables you to build pipelines without knowledge of programming languages such as Scala or Python. It also frees you from having to manually address the “ugly plumbing” of orchestration (DAGs), table management and optimization, or state management, saving you substantial data engineering hours and heartache.
See a video of how it works with Snowflake as the final data destination:
Further Reading on Apache Kafka and Upsolver
- Read our comprehensive, 40-page eBook: The Architect’s Guide to Streaming Data and Data Lakes.
- Compare Apache Kafka with Amazon’s managed Kinesis service.
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
- Try SQLake for Free for 30 days. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free, with our sample data or data from your own S3 bucket – no credit card required.
- Visit our SQLake Builders Hub, where you can browse our pipeline templates and consult an assortment of how-to guides, technical blogs, and product documentation.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
Glossary terms mentioned in this post
- Apache Kafka – an open-source streaming platform and message queue
- ETL pipeline – the process of moving and transforming data
Published in:
Blog
,
Streaming Data