
Explore our expert-made templates & start with the right one for you.
Apache Kafka Architecture: What You Need to Know
-
 Jerry Franklin
Jerry Franklin
- Cloud Architecture
- July 29, 2022
The article you’re currently reading is partially taken from our extensive 40-page eBook, “The Architect’s Guide to Streaming Data and Data Lakes.” This article reviews Kafka’s design patterns and essential insights. To dive deeper, including thorough tool comparisons, extensive case studies, and much more, you can download the free eBook.
Financial, social media, IoT, and other applications constantly produce real-time information. There must be fast, simple methods of transmitting all this information to the people and applications that wish to consume it. But the applications that produce data and the applications that consume data are siloed. We need a point of integration between producer and consumer.
What is Apache Kafka?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its core architectural concept is an immutable log of messages that can be organized into topics for consumption by multiple users or applications. A file system or database commit log keeps a permanent record of all messages so Kafka can replay them to maintain a consistent system state.
Kafka stores data durably, in serialized fashion. It distributes data across a cluster of nodes, providing performance at scale that’s resilient to failures.
Kafka is available as open source code at https://kafka.apache.org/downloads or from vendors who offer it as a cloud managed service, including AWS (MKS – Managed Kafka Service), Azure, Google and Confluent (Confluent Cloud), the company founded by the creators of Kafka.
What is Apache Kafka Used For?
Kafka is flexible and widely-used, but there are several use cases for which it stands out:
- Log aggregation. Kafka provides log or event data as a stream of messages. It removes any dependency on file details by gathering physical log files from servers and storing them in a central location. Kafka also supports multiple data sources and distributed data consumption.
- Stream processing. Kafka is valuable in scenarios in which real-time data is collected and processed. This includes raw data that’s consumed from Kafka topics and then enriched or processed into new Kafka topics for further consumption as part of a multi-step pipeline.
- Commit logs. Any large-scale distributed system can use Kafka to represent external commit logs. Replicated logs across a Kafka cluster help data recovery when nodes fail.
- Clickstream tracking. Data from user click stream activities, such as page views, searches, and so on, are published to central topics, with one topic per activity type.
Understanding Event-driven Architecture in Apache Kafka
Kafka receives and sends data as events called messages which are organized into topics which are “published” by data producers and “subscribed” to by data consumers, which is why Kafka is sometimes called a “pub/sub” system. An event is simply a statement that something occurred in the real world. An event may also be referred to as a record or a message.
An event has a key, a value, a timestamp, and optional metadata headers. Here’s an example:
- Event key: “Daniel.”
- Event value: “Added an ergonomic keyboard to his wishlist.”
- Event timestamp: “June 10, 2022, at 5:03 p.m.”
Learn more about event-driven architecture and Kafka.
What is a Kafka cluster?
A cluster is a distributed computing concept in which a group of devices works together to achieve a specific purpose. Multiple Kafka brokers form a Kafka cluster.
The main goal of a Kafka cluster is to spread workloads evenly across replicas and partitions. Kafka clusters can scale without interruption. They also manage the persistence and replication of data messages. If one broker fails, other Kafka brokers step in to offer similar services without data loss or degraded latency.
Kafka Cluster Architecture
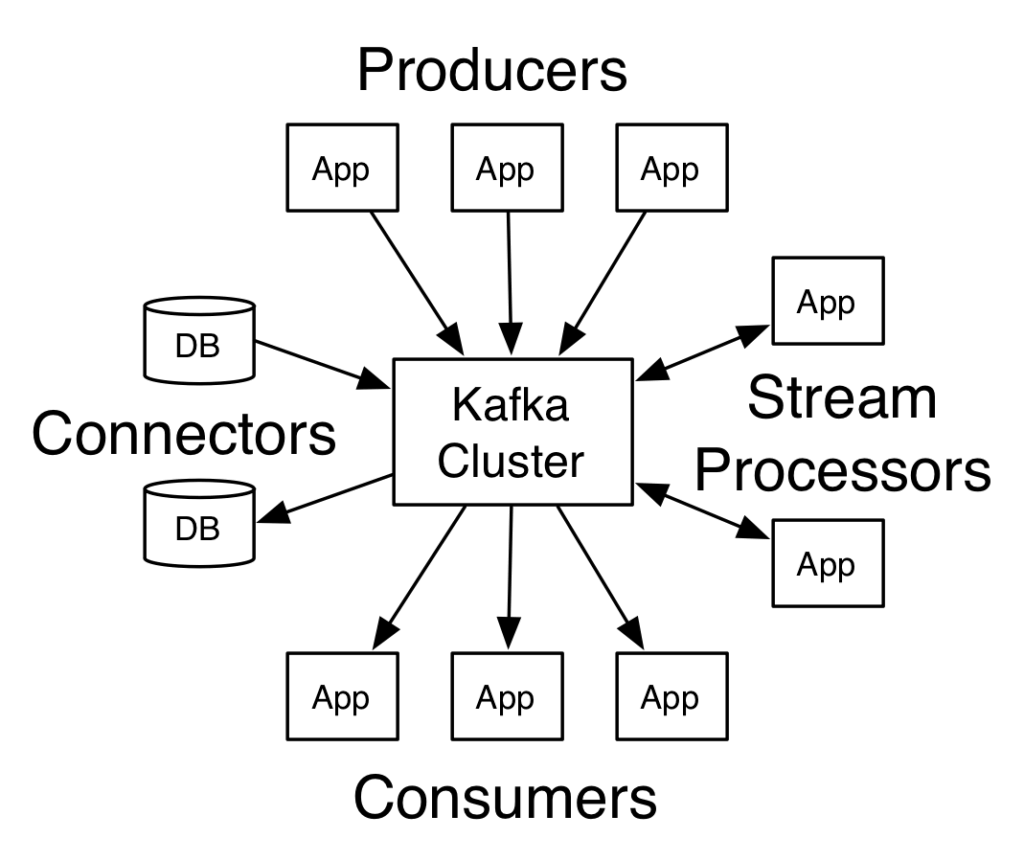
Multiple components comprise the core Kafka cluster architecture:
- Broker
- Controller
- Partitions
- Consumer
- Producer
- Topic
- Zookeeper (phasing out)
- Schema registry
About the Apache Kafka broker
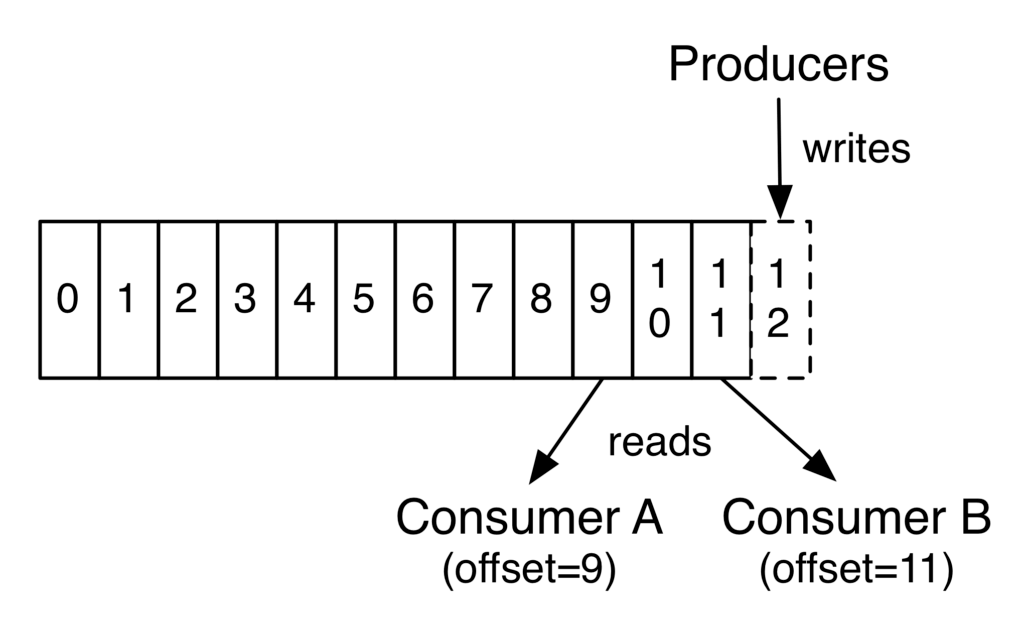
A broker is a single Kafka server. Kafka brokers receive messages from producers, assign them offsets, and commit the messages to disk storage. An offset is a unique integer value that Kafka increments and adds to each message as it’s generated. Offsets are critical for maintaining data consistency in the event of a failure or outage, as consumers use offsets to return to the last-consumed message after a failure. Brokers respond to partition call requests from consumers and return messages that have been committed to disk. A single broker operates based on the specific hardware and its functional properties.
About the Apache Controller
Kafka brokers form a cluster by directly or indirectly sharing information. In a Kafka cluster, one broker serves as the Apache controller. The controller is responsible for managing the states of partitions and replicas and for performing administrative tasks such as reassigning partitions and registering handlers to be notified about changes.
Although the Controller service runs on every broker in a Kafka cluster, only one broker can be active (elected) at any point in time. The Kafka Controller is created and starts up as soon as the Kafka server starts up.
About partitions in Apache Kafka
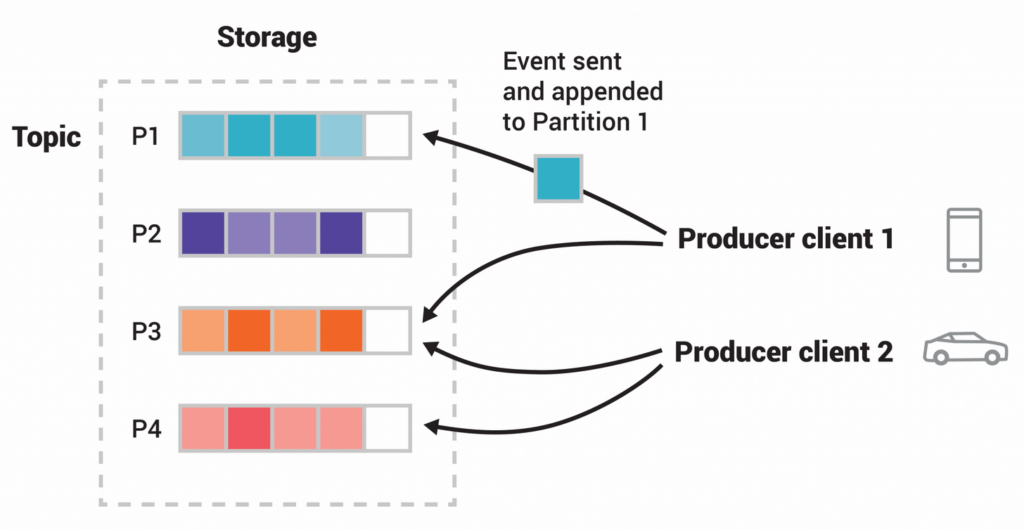
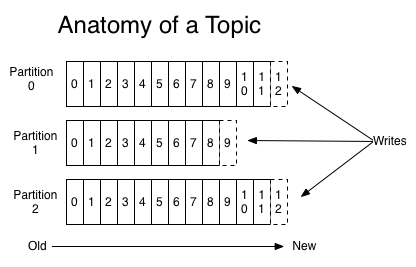
Partitioning is a foundational principle in most distributed systems. In Kafka, a topic is split into multiple partitions. A partition is a discrete log file. Kafka writes records to each partition in append-only fashion. In other words, all of the records belonging to a particular topic are divided and stored in partitions.
Kafka distributes the partitions of a particular topic across multiple brokers. This distributed layout improves scalability through parallelism, as you’re not limited to one specific broker’s I/O. Kafka also replicates partitions and spreads the replicas across the cluster. This provides robust fault tolerance; if one broker fails other brokers can take over and pick up where the failed machine left off.
When a new message is written to a topic, Kafka adds it to one of the topic’s partitions. Messages with the same key (for example, an enrollment number or customer ID) are published to the same partition. Kafka assures that any reader of a given topic/partition always consumes messages in their published sequence.
Kafka architecture diagram – partitions in a Kafka topic:
About consumers in Apache Kafka
Consumers are applications or machines that subscribe to topics and process published message feeds. Sometimes called “subscribers” or “readers,” consumers read the messages in the order in which they were generated.
A consumer uses the offset to track which messages it has already consumed. A consumer stores the offset of the last consumed message for each partition so that it can stop and restart without losing its place.
Consumers interact with a topic as a group (although a group can consist of only one consumer). This enables scalable processing. The group ensures that one member only consumes each partition; if a single consumer fails, the group’s remaining members reorganize the consumed partitions to compensate for the absent member. Groups enable Kafka to consume topics with a massive amount of messages horizontally.
About producers in Apache Kafka
Producers are client applications that publish (write) events to Kafka. Sometimes called “publishers” or “writers,” producers distribute data to topics by selecting the appropriate partition within the topic. They allocate messages sequentially to the topic partition.
Typically, the producer distributes messages across all partitions of a topic. But the producer may direct messages to a particular partition in certain instances – for example, to keep related events together in the same partition and in the exact order in which they were sent. The producer can also use a customized partitioner to map messages to partitions based on specific business logic. However, the producer should take care to distribute keys roughly evenly across partitions to avoid sending too much traffic to one particular broker, which could threaten performance.
About Apache Kafka topics
Topics classify messages in Kafka. A topic is roughly analogous to a database table or folder. Topics are further subdivided into several partitions as described above.
A single topic can be scaled horizontally across various servers to deliver performance well beyond the capabilities of a single server. A Kafka cluster sustains the partitioned log for each topic. Note that while a topic generally has multiple partitions, there is no assurance of message time-ordering throughout the whole topic – only within a single partition.
About Apache Kafka Zookeeper
Zookeeper stores metadata for the Kafka brokers. It acts as a liaison between the broker and the consumers, enabling distributed processes to communicate with one another via a common centralized namespace of data registers called znodes.
With the introduction of Apache Kafka 3.0, Zookeeper is in the process of being removed. Many users had complained about having to manage a separate system and the single point of failure that Zookeeper created. Going forward, Kafka brokers will essentially assume Zookeeper’s functions, storing metadata locally in a file. The Controller takes over registering brokers and removing failed brokers from the cluster, and upon startup the brokers just read from the Controller what has changed, not the full state. This enables Kafka to support more partitions with less CPU consumption.
Check with the Apache Software Foundation to learn whether and when Apache Kafka 3.0 will be considered ready for production environments. (It’s been recommended primarily for test environments.)
About queues in Apache Kafka
Initially Kafka was developed as a messaging queue. But it took on a life of its own, and as a result, was donated to Apache for further development. Kafka still operates like a traditional messaging queue such as RabbitMQ, in that it enables you to publish and subscribe to streams of messages. But comparing RabbitMQ vs Kafka, there are three core differences.
- Kafka operates as a modern distributed system that runs as a cluster and can scale to handle any number of applications.
- Kafka is designed to serve as a storage system and can store data as long as necessary – most message queues (like RabbitMQ) remove messages immediately after the consumer confirms receipt.
- Kafka is designed to handle stream processing, computing derived streams and datasets dynamically, rather than just in batches of messages.
About the Apache Kafka schema registry
A schema registry handles message schemas and routes them to topics. The schema registry verifies and maintains schemas implemented for Kafka messages. It also imposes compatibility before message addition. In this way publishers know which topics receive which forms (schemas) of events, and subscribers know how to interpret and extract information from events in a topic. The schema registry sends data serialized per schema ID so the consumer can map a schema to a message type.
Kafka stores the schema’s namespace in the record it receives from publishers. Then the reader uses the namespace to retrieve records from the schema registry and deserialize the data.
The schema registry saves Kafka from enumerating the same schema details repeatedly into every message. Producers communicate with the registry and write new message schema to it. The producer obtains the schema ID from the registry and includes that in the message.
About Core Kafka Enhancements
Beyond the core Kafka architecture are the following enhancements that extend the capabilities of Kafka. Kafka Streams integrates stream processing with Kafka and Kafka Connect facilitates connecting Kafka to external data sources and sinks.
What is Kafka Streams?
Kafka Streams is an API-driven client library for building applications and microservices, where the input and output data are stored in Kafka clusters. Kafka Streams jobs do not execute on Kafka brokers; rather, they run inside your application or microservice.
Kafka Streams’ approach to parallel processing resembles that of Kafka:
- Each stream partition is a fully-ordered sequence of data records that maps to a Kafka topic partition.
- A data record in the stream maps to a Kafka message from that topic.
- The keys of data records determine the partitioning of data in both Kafka and Kafka Streams – that is, how data is routed to specific partitions within topics.
Kafka Streams processes messages in real-time (that is, not in microbatches), with millisecond latency. It supports stateless and stateful processing and window operations.
Kafka Streams includes two special processors: a Source Processor and a Sink Processor.
- The source processor produces an input stream by consuming records from one or more Kafka topics and forwarding them to its down-stream processors.
- Sink Processor: A sink processor sends any received records from its up-stream processors to a specified Kafka topic.
The processed results can either be streamed back into Kafka or written to an external system.
What are Kafka Connect and Kafka Connectors?
Kafka Connect provides a scalable means of moving data between Kafka and other repositories. It provides APIs and a runtime for designing and operating connector plugins, which are frameworks that Kafka Connect executes and are essential for data movement.
The connector controls:
- The definition and number of tasks that operate for the connector.
- How to divide the data-copying work among tasks.
- Getting task configurations from workers and passing them on to the target.
Connectors initiate tasks to transfer data in parallel at scale and best use existing tools on the worker nodes.
- Source connector tasks consume data from the source system and send Kafka Connect data items to the workers.
- Sink connector processes receive Kafka Connector data items from workers and write them to the target data repository.
In addition, Kafka Connect uses “convertors” to aid ingestion of differently-formatted data items into Kafka (JSON, Avro, Parquet, and so on). Users decide the format in which data is saved in Kafka regardless of the connectors they employ.
What are Kafka APIs?
Kafka provides five key APIs for Java, Scala, and command-line tools for management and administrative tasks. In addition, these APIs enable you to communicate with Kafka programmatically:
- The Admin API enables you to manage and analyze Kafka topics, brokers, Access Control Lists, and other objects.
- The Producer API enables applications to submit (write) data streams to Kafka cluster topics.
- The Consumer API enables programs to access (read) data streams from topics in the Kafka cluster.
- The Streams API provides stream processes that convert a data stream into an output stream.
The Connect API creates connections that continuously draw data from a source data system into Kafka or push data from Kafka into a target data system. (The Connect API is not often needed, as you can instead use pre-built connections without writing any code.)
Kafka on AWS: Reference Architecture Examples
You can install Kafka in cloud computing environments such as Amazon Web Services (AWS). AWS offers their Managed Kafka Service as well.
With AWS, for example, you can:
- Retain full control of all underlying infrastructure by installing an Apache Kafka cluster on an Amazon EC2 instance.
- Outsource much of the infrastructure management to AWS via Amazon Managed Streaming for Apache Kafka (MSK).
Kafka Architecture: Key Takeaways
- Apache Kafka is an open-source stream-processing software platform that helps deliver real-time data feeds to applications.
- Kafka stores data durably, distributes it across a cluster of nodes, and replicates partitions and replicas to ensure data consistency and resilience to failures.
- Kafka provides log aggregation, stream processing, commit logs, and clickstream tracking.
- Kafka is comprised of brokers, controllers, partitions, consumers, producers, topics, schema registries, and Zookeeper (phasing out).
- Consumers and producers interact with topics, and Kafka Streams provides stream processing.
- Kafka Connect facilitates connecting Kafka to external data sources and sinks.
- Kafka can be deployed on AWS with either an EC2 instance or Amazon Managed Streaming for Apache Kafka.
Upsolver SQLake and Apache Kafka
ETL pipelines for Apache Kafka can be challenging. SQlake, Upsolver’s newest offering, is a declarative data pipeline platform that enables you build and run reliable data pipelines on streaming and batch data. Via an all-SQL experience, you can easily develop, test, and deploy pipelines that extract, transform, and load data in the data lake and data warehouse in minutes instead of weeks. SQLake simplifies pipeline operations by automating tasks like job orchestration and scheduling, file system optimization, data retention and the scaling of compute resources.
SQLake reads events from the specified Kafka topic in your Kafka cluster, and performs stateful transformations on the data in near-real-time. It then outputs the data to external analytics systems such as a data warehouse, search system, or data lake table. SQLake also can produce data into different Kafka topics as part of a multi-stage pipeline. SQLake enables data engineers to build these transformation jobs using only SQL. It automates the “ugly plumbing” tasks such as orchestration (DAGs), table management and optimization, and state management, saving data engineers substantial amounts of data engineering hours and heartache.
Try SQLake for free for 30 days. No credit card required.
Real-World Scenario: The Meet Group
Online dating solution provider The Meet Group collects all its data in a centralized Kafka datahub. It uses Upsolver as a real-time collection and transformation engine that connects data producers (such as Apache Kafka and Amazon Kinesis), transforms it on a data lake (AWS S3), and outputs to a range of query services for analysis. (This is the same cloud-native processing engine that powers SQLake.)
Further Reading on Apache Kafka and Upsolver
- Read our comprehensive, 40-page eBook: The Architect’s Guide to Streaming Data and Data Lakes.
- Compare Apache Kafka with Amazon’s managed Kinesis service.
- Compare Kafka vs. RabbitMQ: Architecture, Performance & Use Cases
- Find out the differences between using Kafka with and without a data lake
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo
- Visit our SQLake Builders Hub, where you can read learn more about how SQLake works, read technical blogs that delve into details and techniques, and access additional resources.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
Published in:
Blog
,
Cloud Architecture
