
Explore our expert-made templates & start with the right one for you.
Table of contents
An Architect's Guide to Stream Processing at Scale
What’s the best way to design and build a data platform that’s aligned with your use cases? How do you decide which stack to choose for a given business scenario, given the proliferation of new databases and analytics tools? How can you turn the coming onslaught of data to your competitive advantage?
Building a modern streaming architecture eliminates the need for large data engineering projects later. It ensures flexibility so you can support a robust set of use cases. It can abstract the complexity of traditional architecture into a single self-service platform that turns event streams into analytics-ready data. And it makes it easier to keep up with the pace of innovation and get ahead of the competition.
In this e-book, read about the streaming industry landscape and:
- get an overview of common options for building an infrastructure
- see how to turn event streams into analytics-ready data
- cut through some of the noise of all the “shiny new objects”
- come away with concrete ideas for wringing all you want from your data streams.
Why a Streaming Data Architecture?
Stream processing began as a “niche” technology. But with the rapid growth of SaaS, IoT, and machine learning, organizations across industries are now piloting or fully-implementing streaming analytics. It’s difficult to find a modern company that doesn’t have an app, online ads, an e-commerce site, or IoT-enabled products. Each of these digital assets creates streams of real-time event data. There’s an increasing hunger for incorporating a streaming data infrastructure that makes possible complex, powerful, and real-time analytics.
Traditional batch architectures can suffice at smaller scales. But streaming sources – sensors, server and security logs, real-time advertising, clickstream data from apps and Web sites, and so on – can generate as much as a Gb of events every second. A streaming data architecture consumes this data as it is generated and prepares it for analysis. The latter is especially important, given the unique characteristics of data streams – typically unstructured or semi-structured data that must be processed, parsed, and structured before you can do any serious analysis.
Streaming architectures provide several benefits batch processing pipelines cannot. You can:
- Handle never-ending streams of events in their native form, avoiding the overhead and delay of batching events.
- Process in real-time or near-real-time for up-to-the-minute data analytics and insight – for example, dashboards to display machine performance, or just-in-time service of micro-targeted ads or assistance, or detection of fraud or cybersecurity breaches.
- Detect patterns in time-series data, for example to highlight trends in website traffic data. This is difficult to do with traditional batch processing, as consecutive time-adjacent events can be broken across multiple batches.
Building a streaming architecture is a complex challenge best solved with additional software components depending on use case – hence the need to “architect” a common solution that can handle most if not all envisioned use cases.
What are those building blocks?
The Components of a Streaming Architecture
A streaming data architecture is a framework of software components built to ingest and process voluminous streams of raw data from multiple sources.
Broadly, it consists of four components:
- A stream processor or message broker, to collect data and redistribute it
- Data transformation tools (ETL, ELT, and so on), to ready data for querying
- Query engines, to extract the business value
- Cost-effective storage for high volumes of streaming data – file storage and object storage
Below we review where and how each component type fits in a streaming architecture. Later on we compare some of the most common tools for each component type.
Upsolver makes it possible to build an open lakehouse architecture, which enables companies to design the data infrastructure they need with the components that best serve their specific set of business scenarios – without locking themselves into any single proprietary technology.
Stream Processor / Message Broker
The stream processor collects the data from its source, translates it into a standard message format, then continuously streams it for other components to consume. (Such components could be a storage component such as a data lake, an ETL tool, or some other type of component.) Stream processors are high-capacity (>1 Gb/second) but perform no other data transformation or task scheduling.
40,000-foot view: stream processor as data conduit (Source: Wikimedia Commons)
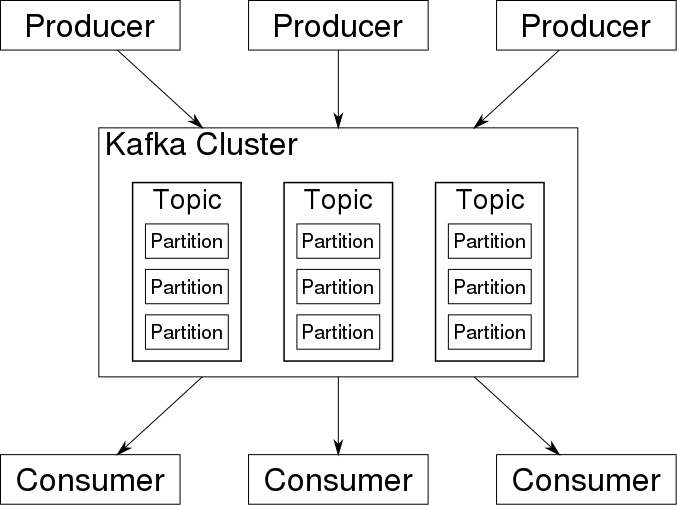
Examples:
Stream Processing Tools
fter the message broker deposits the data you must aggregate, transform, and structure the data to make it query-ready. You can do this via ETL, in which you prep the data in a staging area or in the streaming tool before moving it to a query location, or via ELT, in which you transform and query the data in the same location. Such transformations include normalization; mapping relevant fields to columns; joining data from multiple sources; file compaction; partitioning; time-based aggregation; and more.
Examples:
- Apache Spark Streaming (SQL querying possible, mostly via complex Java or Scala)
- Amazon Web Services – Kinesis
- Google Cloud – Dataflow
- Microsoft Azure – Stream Analytics
- Apache Flink
- Upsolver
Note that, depending on your needs and on the architecture you create, data transformation may occur directly on the data as it streams in and before it’s stored in a lake or other repository, or after it’s been ingested and stored.
Also, see the section on Pitfalls of Stream Processing for considerations regarding Apache Spark.
Query Engines
Data is now ready for analysis. Tools and techniques vary widely, depending on use case.
Examples (not exhaustive):
- Query engines – Athena, Presto, Hive, Redshift Spectrum
- Text search engines – Elasticsearch, OpenSearch, Solr, Kusto
- Cloud data warehouse – AWS Redshift, Snowflake, Google BigQuery, Synapse Analytics (Azure)
- NOSQL store – Cassandra, Amazon DynamoDB, CosmosDB, Google BigTable
- Graph analytics – Neo4j, Amazon Neptune
- Relational database – RDS, SingleStore, CockroachDB
- Real-time database – Imply, Clickhouse
- TSDB – InfluxDB, AWS TimeSeries
Streaming Data Storage
Due to the sheer volume and multi-structured nature of event streams, organizations usually store their streaming event data in cloud object stores to serve as data lakes. They provide a cost-effective and persistent method of storing large volumes of event data. And they’re a flexible integration point, so tools outside your streaming ecosystem can access streaming data.
Examples:
- Amazon S3
- Microsoft Azure Storage
- Google Cloud Storage
Streaming Data – Common Use Cases
Streaming data processing makes it possible to gain actionable insight in real- or near-real-time. Use cases that lend themselves particularly well to streaming include:
- Fraud detection – Combine complex machine-learning algorithms with real-time transaction analysis to identify patterns and detect anomalies that signal fraud in real-time.
- Cybersecurity – Anomalies in a data stream help data security practitioners isolate or neutralize threats, for example a suspicious amount of traffic originating from a single IP address.
- IoT sensor data – Calculating streams of data in real-time, for example to monitor mechanical or environmental conditions or inventory levels and respond almost immediately.
- Online advertising and marketing intelligence – Track user behavior, clicks, and interests, then promote personalized, sponsored ads for each user. Measure audience reactions to content in real-time to make fast, targeted decisions about what to serve visitors and customers and drive leads.
- Product analytics – Track behavior in digital products to understand feature use, evaluate UX changes, increase usage, and reduce abandonment.
- Log analysis – IT departments can turn log files into a centralized stream of easily-consumable messages to extract meaning from log files; often combined with visualization tools and out-of-the-box filters.
- Cloud database replication – Use change data capture (CDC) to maintain a synced copy of a transactional database in the cloud to enable advanced analytics use by data scientists.
Common Pitfalls of Stream Processing
Stream processing is the best approach to getting business value out of massive streams of data. But the path isn’t necessarily straightforward. Keep these pitfalls in mind when designing your streaming architecture:
- Complexity of Apache Spark
- Over-reliance on databases
- Proliferation of small files
Upsolver reduces friction and complexity with a streaming data platform.
Complexity of Apache Spark
Spark is a robust open-source stream processor, and it’s in wide use. But, as with Hadoop, it’s a complex framework that requires significant specialized knowledge. It’s powerful and versatile – but it is not easy to use, simple to deploy, or inexpensive to run. That’s because Spark:
- is built for big data and Scala engineers, not for analytics teams. Building data transformations in Spark requires lengthy coding in Scala with expertise in implementing dozens of Hadoop best practices around object storage, partitioning, and merging small files.
- is not a stand-alone solution. Spark is only part of a larger big data framework. For stream processing, workflow orchestration, and state management, you need to assemble quite a few additional tools, each with its own specialized skill set, adding yet more complexity and cost.
- requires a very long time-to-value. A large-scale implementation of Spark is a complex coding project. With the time it takes to hire or train the expertise, custom develop, and manually tune to optimize and scale Spark, and it’s months – or more – from inception to production.
- creates tech-debt and stifles agility. Any change to the data or analytics requirements will demand a coding cycle including regression testing / QA.
- creates a data engineering bottleneck. The data team must implement any new dashboard or report that requires a new ETL flow or a pipeline change. So every change request must fit into an engineering team’s Sprint planning. This can be painful and ultimately reduces access to data across the organization.
- is costly. True, there are no direct licensing fees (although there can be heavy subscription costs through a managed Spark service). But add the cost of additional hardware to the cost of specialized expertise, and an Apache deployment can easily exceed most software license prices. There’s also the opportunity cost incurred when you use high-end developers for mundane data pipeline building and maintenance.
Over-reliance on Databases
If you’re already managing high-volume data streams it may be obvious – but keeping your streaming data in relational databases is untenable:
- Transactional databases must be reserved for operations. Any extracurricular reporting or processing impedes performance.
- Event-based data is stored as objects rather than tables. But relational databases are built on tabular storage; using them to store unstructured data requires lengthy cleansing and transformation processes and creates engineering bottlenecks on ingest.
- Storage costs can easily dwarf all other project costs, especially when you’re storing big data in a database where storage and compute are closely coupled.
- Operational databases only contain relatively recent data, and usually only the most recent state of a data point. It’s exceptionally challenging to unearth patterns and trends, or trace data lineage so you can recover from an error.
- The value of streaming data is unlocked through exploratory techniques, predictive modeling, and machine learning. These analyses require broader and more flexible access to data than a traditional database can provide.
Proliferation of Small Files
Writing small files to object storage is straightforward. But regardless of whether you’re working with Hadoop or Spark, in the cloud or on-premises, small files can ruin your performance. It takes milliseconds to open each file, read the metadata, and close the file, which becomes meaningful when you’re dealing with millions of files. In addition, many files result in many non-contiguous disk seeks, for which object storage is not optimized.
To mitigate this, use compaction in your data architecture – regularly merging your smaller event files into larger archives – to improve query performance. The best ways to do that:
- Define your compaction window wisely. Compacting too often is wasteful, as files will still be pretty small and any performance improvement will be marginal. Compacting too infrequently results in long processing times and slower queries as the system waits for the compaction jobs to finish.
- Delete uncompacted fields to save space and storage costs. Of course, always keep a copy of the data in its original state for replay and event sourcing.
- Reconfigure your Athena table partitions after compaction is completed, so Athena will read the compacted partition rather than the original files.
- Keep your file size as big as possible but still small enough to fit in-memory uncompressed.
Meanwhile, adhering to a number of best practices can ensure you derive more value, more quickly, when you build a streaming architecture.
Streaming Architecture Best Practices
Keep these techniques in mind when building your streaming architecture:
- Deploy a schema-on-read model
- Separate real-time and historical data
- Maintain an immutable log of all incoming events
- Layer your data lake
- Keep your architecture open
- Optimize query performance
Upsolver automates best practices to help you build a modern streaming architecture with minimal effort. More information on data lake best practices.
Deploy a schema-on-read model
You should understand the data as it is being ingested – the schema of each data source, sparsely populated fields, data cardinality, and so on. Gaining this visibility on read rather than trying to infer it on write saves you much trouble down the line, because as schema drift occurs (unexpected new, deleted and changed fields) you can build ETL pipelines based on the most accurate and available data.
Separate the data you want for real-time analytics from historical data
Optimize the data intended for real- or near-real-time analysis to ensure fast reads. Keep historical data in its original raw form for ad hoc queries, to use for:
- “replaying” a past state of affairs
- error recovery
- tracing data lineage
- exploratory analysis
Maintain an immutable log of all incoming events
Here you’re essentially storing the entire chain of event transformations, rather than just the final (or most recent) result of a transformation. In this way you can restore any event to its state at a certain point of time. This “event-sourcing” approach has multiple benefits:
- enable data teams to validate their hypotheses retroactively
- enable operations teams to trace issues with processed data and fix them quickly
- Improve fault-tolerance in cases of failures or data corruption; you can recover the current state of data by just applying an entire sequence of events to the corrupted entity.
To drive costs down, store the log in your object storage. When you get a request from an analyst or researcher, create an ETL job to stream the data from the immutable log to an analytics platform, and replay from there.
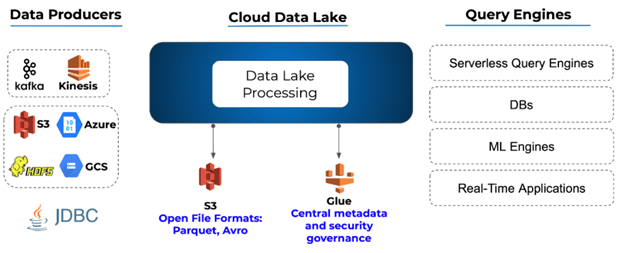
Layer your data lake according to your users’ skills
Store multiple copies of data in your data lake to serve a wide spectrum of constituents. An ideal data pipeline gives each of these consumers access to the data they want using the tools they already know – for example, complete (or nearly complete) raw data for data scientists or machine learning algorithms, or an aggregated, thinner, and structured version that BI analysts can use to create reports rapidly. You can automate the ETL pipelines that ingest the raw data and perform the relevant transformations per use case. Then you avoid the bottleneck of relying on manual work by data providers (DevOps, data engineering), for example by coding ETL frameworks such as Apache Spark for every new request.
Cloud data lake configured for different user sets
Keep your architecture open
Given the quick pace of change in the analytics industry, preserving an openness to “future-proof” your architecture is critical. Avoid vendor lock-in or overreliance on a single tool or database (and, therefore, the “gatekeeper toll” that inevitably comes with it). You get the most value when you can provide ubiquitous data access using a wide variety of tools, via a broad range of services.
To create an open architecture:
- Store your data in open columnar file formats such as Avro and Parquet, which are standard, well-known, and widely supported (as opposed to proprietary file formats built for a specific database such as Databricks Delta Lake). This also improves query performance, as we explain in the next section.
- Retain raw historical data in inexpensive object storage, such as Amazon S3. You’ll always have your data available no matter what platform you use to manage your data lake and run your ETL.
- Use a well-supported central metadata repository such as AWS Glue or the Hive metastore. You can centralize and manage all your metadata in a single location, in the process reducing operational costs in infrastructure, IT resources, and engineering hours.
Optimize query performance
The following best practices improve query performance for most business cases:
- Partition your data appropriately for your use
- Convert to efficient columnar file formats
- Compact (merge) small files frequently
Partition your data
How you partition your data has a major impact on query costs and speed. Queries run more efficiently and inexpensively because proper partitioning limits the amount of data query engines such as Amazon Athena must scan to answer a specific analytical question.
Data is commonly partitioned by timestamp. However, depending on your queries data may be partitioned by other fields such as geography or a time-based field that differs from the record time-stamp. If possible, configure the size of the partition based on the type of query you’re likely to run and the recommendations of your analytics system. For instance, if most of your queries require data from the last 12 hours, consider hourly partitioning rather than daily, to reduce the amount of data to scan.
Review this guide to data partitioning to learn more.
Convert to efficient columnar file formats
Another way you can reduce the amount of data to scan. Store the data you plan to use for analytics in a columnar file format, such as Apache Parquet or ORC. With columnar formats you can query only the columns you need, reducing the compute required, in turn speeding queries and reducing cost.
Compact frequently to address the “small files problem”
Data streams regularly produce millions of small event files every single day. Small files give you fresher data, but if you query these small files directly, you crush performance over time. The process of merging small files into right-sized files is called compaction.
Weigh the value of data currency against the value of high performance, and compact your files as frequently as needed to keep your data in optimal file sizes.
Stream Processing: Which Tool do I Use?
Event streaming brings unbounded streams of data together from disparate sources for real-time processing. How you ultimately architect your streaming solution depends on technical factors such as company resources and engineering culture, as well as on business factors such as budget, use case, and the metrics you want to achieve.
There is a large and growing variety of tools and technologies available from which to choose, roughly speaking in four categories:
- Event streaming / stream processing
- Batch and real-time ETL tools
- Query engines
- Storage layers
We survey the most significant tools in each category.
Tool Comparison: Stream Processing/Event Streaming Tools
By far, the most common event streaming tools are Amazon Kinesis and Apache Kafka.
Amazon Kinesis
Amazon Kinesis is a publish-and-subscribe (pub-sub) messaging solution. It’s a managed service in the AWS cloud; configuration is limited, and you cannot run Kinesis on-premises.
- Setup/config: AWS manages the infrastructure, storage, networking, and configurations needed to stream data on your behalf. AWS also handles provisioning, deployment, and on-going maintenance of hardware, software, and other services of data streams.
- Cost: There are no upfront setup costs. Charges depend on:
- the number of shards (partitions) you need for the required throughput each shard essentially is a separate stream containing a subset of the data; Kinesis has multiple shards per stream).
- the amount of data a producer transmits to the data streams, so costs can be significant with high volumes of data.
- Used for: Given Amazon’s promise of high availability, Kinesis can be a good choice if you don’t have resources for 24/7 monitoring, alerting, and a DevOps team to recover from a failure.
Apache Kafka
Apache Kafka is an open source pub-sub system that has evolved into a mature horizontally scalable and fault-tolerant system for high-throughput data replay and streams.
- Setup/config: Optimizing Apache Kafka for throughput and latency requires tuning of both producers and consumers. Server side configurations – for example, replication factor and number of partitions – are also crucial for achieving top performance by means of parallelism. For high availability, you must configure Kafka to recover from failures as soon as possible.
- There are challenges to building ETL pipelines in Kafka; in addition to the basic task of data transformation, you must also account for the unique characteristics of event stream data.
- Cost: Kafka requires its own cluster. Setting up a Kafka cluster requires learning and distributed systems engineering practice and capabilities for cluster management, provisioning, auto-scaling, load-balancing, configuration management, and significant DevOps involvement. You also need a high number of nodes (brokers), and replications and partitions for fault tolerance and high availability of your system.
- Used for: Real-time data processing; application activity tracking; logging and/or monitoring systems.
Managed Kafka services
Confluent KSQL and Amazon MSK (Managed Streaming for Kafka) both offer a discrete managed Kafka service deployed in the cloud. Their aim is to leverage the flexibility and near-ubiquity of Kafka while managing much of its inherent complexity.
Confluent Cloud is a fully managed cloud service for Kafka, accelerating the development of event-driven services and real-time applications without requiring you to manage the Kafka cluster.
- Setup/Config: Requires a Java runtime environment and access to a Kafka cluster for reading and writing data in real-time. The cluster can be on-premises or in the cloud. Need to set configuration parameters for ksqlDB Server and for queries, as well as for the underlying Kafka Streams and Kafka Clients (producer and consumer).
- Cost: Multiple pricing models: Per Gb (data in, data out, data stored); compute per hour; partitions per hour.
- Used for: For hosting Kafka in the cloud. Also useful as a message broker that facilitates communications between enterprise-level systems and integrates the data generated by each system into a central location such as Amazon S3.
Amazon MSK is a fully-managed service that simplifies building and running production applications that use Apache Kafka to manage message queues and process streaming data.
- Setup/Config: MSK simplifies setup and maintenance. Settings and configuration based on Apache Kafka’s deployment best practices. Automatically provisions and runs your Apache Kafka clusters.
- Cost: Usage-based. You pay for the time your broker instances run, the storage you use monthly, and standard data transfer fees for data in and out of your cluster.
- Used for: Maintaining and scaling Kafka clusters, enabling an end-to-end ingestion pipeline supported by a fully managed service. Also used as a real-time message broker between different microservices.
Tool Comparison: Batch and Real-Time ETL Tools
In this category you can choose from open source tools, managed services, or fully-managed self-service engines.
Upsolver is a popular tool for real-time data processing. Whether you’re just building out your big data architecture or are looking to optimize ETL flows, Upsolver provides a comprehensive self-service platform that combines batch, micro-batch, and stream processing. Upsolver automates menial data pipeline work, enabling developers and analysts to easily combine streaming and historical big data.
Apache Spark
Spark is a distributed general-purpose cluster computing framework. (See the Pitfalls of Stream Processing section for caveats about Spark.) It’s an example of a declarative engine, which developers use to chain stream processing functions. The Spark engine calculates and optimizes the Directed Acyclic Graph (DAG) as it ingests the data. (A DAG is a data flow that proceeds in one direction with no loops). Spark’s in-memory data processing engine executes analytics, ETL, machine learning, and graph processing on data in motion or at rest. It offers high-level APIs for certain programming languages: Python, Java, Scala, R, and SQL.
Pros:
- A mature product with a large community, proven in production for many use cases
- Readily supports SQL querying.
Cons:
- Complex and labor-intensive to implement and maintain
- Latency of several seconds, which eliminates some real-time analytics use cases
Amazon Glue
Amazon Glue is a fully-managed service for ETL and data discovery, built on Apache Spark. Glue provides a serverless environment to run Spark ETL jobs using virtual resources that it automatically provisions. Using Glue you can execute ETL jobs against S3 to transform streaming data, including various transformations and conversion to Apache Parquet.
Pros
- Can reduce the hassle of ongoing cluster management
Cons
- Still evolving as a service
- Confined to the batch nature of Spark, which entails certain latencies and limitations
- Much optimization must be done on the storage layer (such as compacting small files on S3) to improve query performance
Apache Flink
A stream processing framework that also handles batch tasks. Flink is also a declarative engine. It approaches batches as data streams with finite boundaries. Data enters via a source and leaves via a sink. It’s based on the concept of streams and transformations.
Pros:
- Stream-first approach offers low latency, high throughput
- Real entry-by-entry processing
- Does not require manual optimization and adjustment to data it processes
- Dynamically analyzes and optimizes tasks
Cons:
- Some scaling limitations
- Relatively new; fewer deployments in production, compared to other frameworks
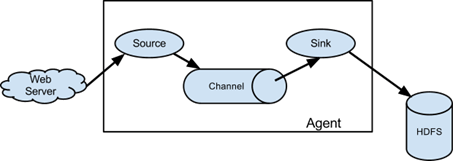
Apache Flume
A reliable distributed service for aggregating, collecting, and moving massive amounts of log data. It has a flexible and basic architecture. Captures streaming data from Web servers to Hadoop Distributed File System (HDFS).
Pros:
- Central primary server controls all nodes
- Fault tolerance, failover, and advanced recovery and reliability features
Cons:
- Difficult to understand and configure with complex logical/physical mapping
- Big footprint – >50,000 lines of Java code
Apache Storm
Apache Storm processes large quantities of data and provides results with lower latency than many other solutions. Suitable for near real-time processing workloads. Storm is a compositional engine, in which developers define the DAG in advance and then process the data. This may simplify code. But it also means developers must plan their architecture carefully to avoid inefficient processing.
The Apache Storm architecture is founded on spouts and bolts. Spouts are origins of information. They transfer information to one or more bolts. The entire topology forms a DAG.
Pros:
- Ideally suited for real-time processing
- Use of micro-batches provides flexibility in adapting the tool for different use cases
- Wide language support
Cons:
- May compromise reliability, as it does not guarantee ordering of messages
- Highly complex to implement
Apache Samza
Samza uses a pub-sub model to ingest the data stream, process messages, and output findings to another stream. It’s another compositional engine. Samza relies on the Apache Kafka messaging system, architecture, and guarantees to offer buffering, fault tolerance, and state storage.
Pros:
- Offers replicated storage that provides reliable persistence with low latency
- Easy and cost-effective multi-subscriber model
- Can eliminate backpressure, persisting data for later processing
Cons:
- Does not support very low latency
- Only supports JVM languages
- Does not support exactly-once semantics
Amazon Kinesis Streams
A proprietary event streaming tool offered as a managed service by AWS. Collects gigabytes of data per seconds from hundreds of thousands of sources. Captures the data in milliseconds for real-time analytics use cases. Works very similarly to Kafka’s pub-sub model, including elastic scaling, durability, and low-latency message transfer (within 70ms of the data being collected according to Amazon’s marketing).
Pros:
- A managed service that is straightforward to set up and maintain
- Integrates with Amazon’s extensive big data toolset
Cons:
- Commercial cloud service, priced per hour per shard; can be expensive when processing large volumes of data
- Requires sacrificing some level of control and customization in exchange for ease-of-use and reduced focus on infrastructure
Do it Yourself vs. End-to-End Stream Platforms
There are many good options for building stream processing pipelines. But all of them require expertise and hard work to create an end-to-end solution. Then enable you to build to suit. But doing so is error-prone and highly resource-intensive.
Managed streaming frameworks such as Upsolver can reduce the time required for your streaming project from weeks or months to hours, while allowing compelling use cases such as persisting events to a data lake. Upsolver connects to data sources and injects the data to the data lake while running storage and query optimizations. A no-code, high-speed compute layer between your data lake and the full range of analytics tools enables data practitioners to explore, discover, process and analyze data with little to no help from IT or engineering teams. Upsolver also makes possible upserts and streaming joins, which typically are difficult to do on a data lake. More information about Upsolver follows.
Tool Comparison – Analytics Engines
There is a wide and growing array of tools that data practitioners use to derive insight and value from stored and streamed data. These tools in turn work with business intelligence applications to visualize and explore data, and data modeling and other predictive analytics applications for machine learning and AI.
Common analytics tools use today include:
- Big data query engines:
- Amazon Athena
- Presto
- Trino / Starburst
- Redshift Spectrum
- Hive
- many others
- Dedicated text search engines
- ElasticSearch
- Amazon OpenSearch
- Apache Solr (open source, based on the same library as ES, but much less prevalent)
- Kusto – managed MS offering
- Storage layers
- Data warehouses
Upsolver transforms raw data into queryable data for your preferred analytics engines, at scale and in real-time. – regardless of whether you’re using S3 as your data lake or are using (or planning on using) other data lakes or stores.
“Big Data” Query Engines
As the name implies, these technologies are designed, or have evolved, to run interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.. They search data in any form – structured, semi-structured, unstructured – and can run many simultaneous queries, if possible in real-time. They can query data wherever it is stored, without the need to move the data into a separate, structured system like a relational database or data warehouse.
Amazon Athena
Athena is a distributed query engine that uses S3 as its underlying storage layer. Its performance strongly depends on how data is organized in S3, as there’s no database to do the transformations in place of the ETL tool. ETL to Athena must optimize S3 storage for fast queries and handle stateful operations.
Athena performs full table scans instead of using indexes. This means some operations, such as joins between big tables, can be very slow.
Presto
Presto (or PrestoDB) is an open source distributed SQL query engine that relies on a Hive metastore. It’s designed for fast analytic queries against any amount of data. It is the underlying service on which Amazon based Athena. As with Athena, you can use Presto to query data in the cloud object store; you don’t have to first move the data into a separate analytics system. Query execution runs in parallel over a scalable, pure memory-based architecture.
Presto has the functionality through its connectors to directly interface with a wide variety of data sources in addition to S3, including HDFS data blocks and relational databases.
Trino / Starburst
Trino is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources. Originally named PrestoSQL, Trino is a fork of the original prestoDB open source project. It’s maintained by the large community of contributors and users of the Trino Software Foundation.
Starburst, a member of the Presto Foundation governing board, maintains an enterprise-grade commercial distribution of Trino called Starburst Enterprise. Starburst Enterprise includes additional security features, more connectors, a cost-based query optimizer, support for running additional deployment platforms, and more. It’s designed to help large companies securely extract more value from their Trino deployments.
Redshift Spectrum
Redshift is a relational database; you pay for both storage and compute. Redshift Spectrum is a query engine that resides on dedicated Redshift servers and accesses data in S3.
Compared to Athena, Redshift is:
- faster
- more robust (with additional compute power)
- more expensive
- more complicated to manage, requiring significant expertise in cluster management
Amazon introduced RA3 node types to Redshift to improve performance and increase storage capacity. Amazon’s Advanced Query Accelerator (AQUA) for Redshift sits between an Amazon Redshift RA3 cluster’s compute and storage, and runs with Amazon Redshift RA3 instances. It is not designed to work with a data lake.
Hive
Apache Hive is an open source data warehouse application for reading, writing, and managing large data sets It works with Apache Hadoop Distributed File System (HDFS) or other data storage systems, such as Apache HBase. You connect to Hive via a command line tool and JDBC driver. Use Hive’s SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.
Dedicated Text Search Engines
As the name implies, dedicated text (or full-text) search engines examine all the words in documents and database records. (Metadata search methods analyze only the description of the document.) They promise fast retrieval of data with advanced indexing and more intuitive search results based on relevance.
Elasticsearch
Elasticsearch is an open source scalable search engine based on Lucene. It’s often used for log search, log analytics, and BI and reporting. You can run it anywhere.
It’s not unusual to include Elasticsearch in a streaming architecture expressly to query log files. To do this, store all raw data in a data lake for replay and ad hoc analysis. Then de-dupe it, filter out irrelevant events, and send that subset to Elasticsearch.
You can also use Kafka Connect to stream topics directly into Elasticsearch.
Storing all of your logs in Elasticsearch requires no custom coding. But since Elasticsearch logs are often text-heavy, hence relatively large, storage is expensive
Amazon OpenSearch
The OpenSearch project, created by Amazon, is a forked search project based on Elasticsearch and Kibana. (Amazon is not planning current or future releases of Elasticsearch and Kibana.) It is identical to Elasticsearch but over time will diverge.
Apache Solr
Apache Solr is an open source enterprise search platform built on Apache Lucene™. It provides distributed indexing, replication and load-balanced querying, automated failover and recovery, and centralized configuration. It’s designed to be reliable, scalable, and fault tolerant.
Microsoft Azure Data Explorer (aka Kusto)
Azure Data Explorer is a service for storing and running interactive analytics on large volumes data. It’s RDMS- based and supports entities such as databases, tables, and columns. You create complex analytical queries via the Kusto Query Language.
Kusto supplements (but does not replace) traditional RDBMS systems for scenarios such as OLTP and data warehousing. It performs equally well with all forms of data – structured, semi-structured, and unstructured. Kusto does not perform in-place updates of individual rows and cross-table constraints or transactions.
Storage Layers
As with other types of streaming architecture components, storage layers are evolving, as are the strategies for getting the most out of them
A detailed description of the many storage options is beyond the scope of this eBook. In general, you can choose from file storage, object storage (data lakes, mostly0, and data warehouse.
File storage – Hadoop was designed to handle substantial volumes of data. It’s still simple and effective enough for (relatively speaking) small-to-moderate numbers of files. But metadata is limited, and searching is only through the whole file, so as volume increases, the cost and complexity and latency of using HDFS as your main storage layer simply becomes inappropriate.
Object storage – Generally this means data lakes, the most prominent of which are Amazon S3; Microsoft Azure Data Lake; and Google Cloud Storage. File locations are tagged, and metadata is robust. So scaling is limitless and searching is much faster than file storage. But data must be transformed and optimized to make it queryable.
Data Warehouses – These work best with structured and semi-structured data, and the data must be pre-processed before it can be stored in a warehouse (schema on read). Warehouses can offer easy data access and fast queries, but don’t scale cost-effectively, and also don’t work well with unstructured data. They also generally require a closed architecture – that is, they really only work with the respective vendor’s toolset. This can effectively lock you out of some important innovation. There are many data warehouses available; the most prominent are Snowflake and Amazon Redshift.
Future-proofing Your Architecture with Upsolver
Despite the dizzying pace of investment and technological innovation, you can design an architecture that won’t be outdated quickly and force you to waste time and money re-building to suit new systems or scale increasing volumes of data.
An open data lake architecture — one that gives you access to the best of all worlds (databases, data warehouses, and data lakes) and uses open file formats to enable you to use any new analytics tool you require, keeps you agile.
Here’s a reference architecture:
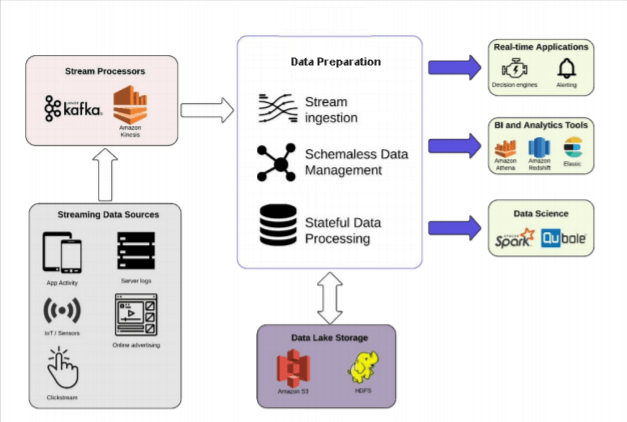
Data Lakes vs. Data Warehouses
For some time, large enterprises have used data warehouses to mine the value hidden in their data. But warehouses can’t keep up with all data processing needs (streaming, machine learning, exponential growth in volumes). They don’t work well with unstructured data. And data warehouses are their own monoliths; there is risk involved in entrusting a single vendor to deliver SQL analytics, streaming, machine learning, text search, and so on. There is too much innovation in data analysis.
Data lakes evolved as an alternative. It’s easy to store data in any format cheaply in a lake (as object storage). But it’s costly and complex to make it valuable and easy to query. Whether you work on-premises or in the cloud, coding and expertise in the complex Hadoop/Spark stack turn the lake into a swamp.
The next logical evolutionary step centers around a simple integration between a lake and multiple warehouses. Centralizing storage, metadata, and access control can address almost any concern about the additional cost and overhead.
An open data streaming architecture achieves the cost and flexibility benefits of a data lake platform with the ease-of-use of a data warehouse.
How Upsolver Enables an Open Streaming Architecture
Upsolver makes this possible, making your cloud data analytics-ready in days, with no coding required, using the components you want. By providing a self-service, high-speed compute layer between your data lake and the analytics tools of your choice, Upsolver automates menial data pipeline work, so you can focus on developing analytics and real-time applications.
You build your pipeline using Upsolver’s visual interface or SQL. Upsolver automatically ingests and parses the data, applies stateful transformations, and enriches the data by joining it with data from external sources. It tunes the data for optimal performance, creating queryable data sets in near real-time for use by various analytics platforms. You get to work with cloud object storage as if it were a relational database – without any Spark coding or intensive configuration for optimal file system management.
It’s proven in the real world, as the following examples illustrate. Note also how Upsolver fits into different designs to support virtually any use case.
Real-world architectures
Here are some real-world illustrations of companies that have made use of Upsolver to create streaming architectures that support organizational growth while preserving flexibility.
Peer39
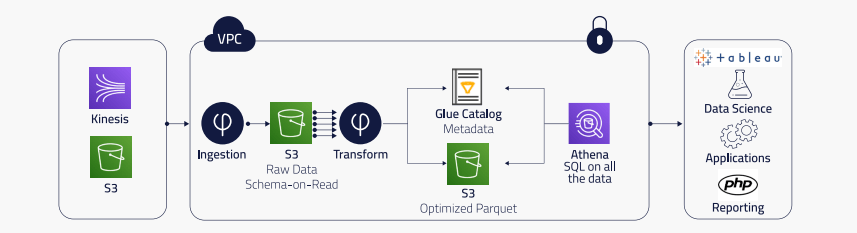
Peer39 is an innovative leader in the ad and digital marketing industry that provides page level intelligence for targeting and analytics.
The company relies on Upsolver to unify teams across data scientists, analysts, data engineers, and traditional DBAs. With its streaming architecture, Peer39 can onboard new publishers and data providers within minutes instead of weeks and make frequent changes without impacting the end result, in turn accelerating the company’s time to market.
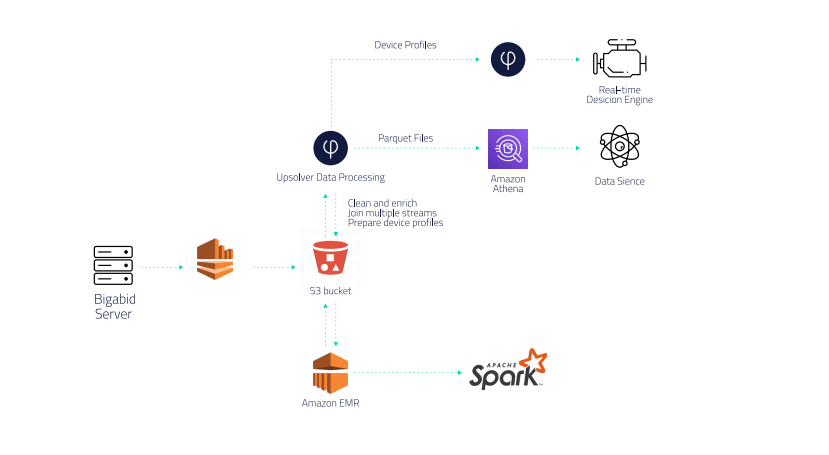
Bigabid
Bigabid is an innovative mobile marketing and real-time bidding company that empowers its partners to scale their mobile user acquisition efforts while lowering advertising costs through AI-based and cost-per-action optimization.
Bigabid employs Upsolver in its real-time architecture to prepare data for Athena and help the company avoid coding ETLs. Upsolver also optimizes Athena’s storage layer (Parquet format, compaction of small files) so queries can run much faster.
Bigabid uses the same data in a separate pipeline that sends data via Amazon EMR to Apache Spark, which performs complex calculations that could not be done in SQL.
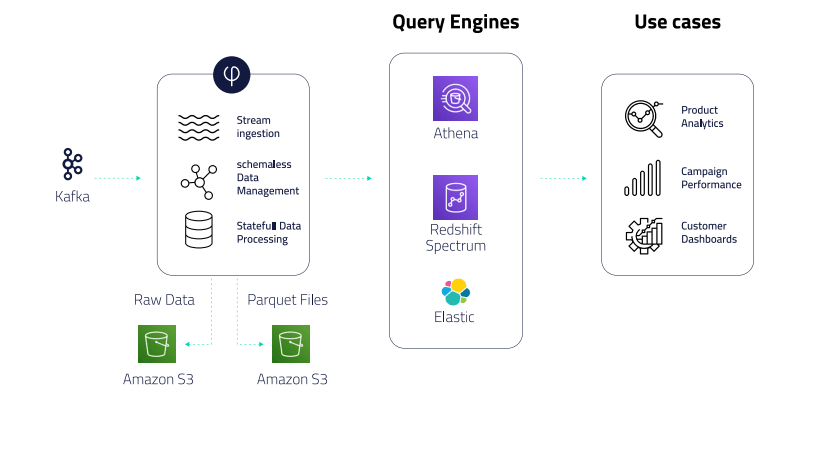
ironSource
ironSource helps app developers take their apps to the next level, including the industry’s largest in-app video network. Over 80,000 apps use ironSource technologies to grow their businesses.
ironSource successfully built an agile and versatile architecture with Upsolver and AWS data lake tools. It stores raw event data on object storage, and creates customized output streams that power multiple applications and analytic flows. Upsolver enables BI developers and operations and software teams to transform data streams into tabular data without writing code. ironSource also supports a broad range of data consumers and minimizes the time DevOps engineers spend on data plumbing via Upsolver’s GUI-based, self-service tool for ingesting data, preparing it for analysis, and outputting structured tables to various query services.
Summary
As the scale of streaming data continues to grow, organizations can stay competitive by building or upgrading a data architecture that enables them to process and analyze it, in real- or near-real-time. There are multiple approaches, technologies, and tools at each step of the process. By adopting a finite number of best practices and adhering to an open data architecture that maximizes choices, your data stack can be not only cost-effective, but flexible and scalable enough for the foreseeable future.
Tools like Upsolver facilitate this further, eliminating much of the manual, time-intensive, and error-prone task of building and maintaining data pipelines. They also shrink the time it takes for data practitioners in any department to extract value from the data and thus get better answers faster and improve business decision-making.