
Explore our expert-made templates & start with the right one for you.
Databricks Delta Lake vs Data Lake ETL: Overview and Comparison
-
 Eran Levy
Eran Levy
- Cloud Architecture
- July 18, 2019
Looking for a high-performance, high-scale data pipeline? Read out 6 Tips for Evaluating Data Lake ETL Tools.
Databricks described Delta Lake as ‘a transactional storage layer’ that runs on top of cloud or on-premise object storage. Delta Lake promised to add a layer of reliability to organizational data lakes by enabling ACID transactions, data versioning and rollback.
In this article we take a closer look at Delta Lake and compare it to a data lake ETL approach, in which data transformations are performed in the lake rather than by a separate storage layer. Obviously, we have a horse in this race since Upsolver SQLake is a declarative data pipeline platform that reduces 90% of ETL and custom pipeline development. But we welcome readers to scrutinize our claims and test them against their own real-world scenarios. For another comparison, see our article on Databricks vs Snowflake.
The Challenge of Storing Transactional Data in a Data Lake
With all the talk surrounding data lakes, it can be easy to forget that what we’re essentially talking about is files stored in a folder (e.g. on Amazon S3). As we’ve previously explained, in a data lake approach you store all your raw data on inexpensive, decoupled object storage, and then employ a variety of analytics and data management tools to transform, analyze and drive value from the data. Your success will largely depend on how efficiently you structure your data lake.
Since the storage layer is composed of files partitioned by time rather than tables with primary and foreign keys, data lakes are traditionally seen as append-only. The lack of indices means that in order to delete or update a specific record, a query engine will need to scan every single record in the lake which isn’t a reasonable solution.
Because data lakes are so difficult to update, they are often seen as less desirable for transactional use cases – for example:
- Data that needs to be frequently updated – such as sensitive customer information that might need to be deleted due to GDPR requests
- Data that must be absolutely reliable, such as financial transactions that could be cancelled due to charge-backs and fraud
- Reflecting changes in operational databases via change data capture (CDC)
Delta Lake purports to address these and similar scenarios – let’s talk about how.

The Delta Lake Solution
Going off the materials Databricks has published online, as well as the coverage in various media outlets, we can get a pretty good impression of how Delta Lake works.
Basically, Delta Lake is a file system that stores batch and streaming data on object storage, along with Delta metadata for table structure and schema enforcement.
Getting data into the lake is done with Delta ACID API and getting data out of the lake is done with Delta JDBC connector. The data is Delta is not queryable by other SQL query engines like AWS Athena, Redshift Spectrum, Apache Presto and vanilla SparkSQL.
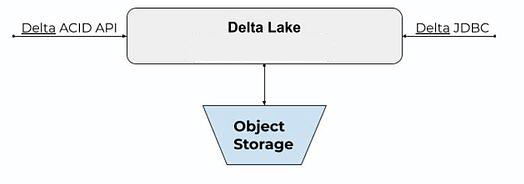
If this sounds a lot like a database built on decoupled architecture, that’s probably not a coincidence. While the word “database” is notably absent from the documentation and marketing materials related to Delta Lake, it’s safe to say that the software behaves very similarly to decoupled databases such as Snowflake and BigQuery: a separate transactional layer on object storage that uses an ACID API and JDBC connector.
To understand how this differs from a data lake ETL approach, let’s look at what the latter entails:
The Data Lake ETL Solution
A data lake ETL solution needs to plug into an existing stack and not introduce new proprietary APIs. Hence, ingestion is performed using connectors and queries are performed by any query engine like AWS Athena, Redshift Spectrum, Apache Presto and SparkSQL. Metadata stores like Hive Metastore or AWS Glue are used to expose table schema for data on object storage.
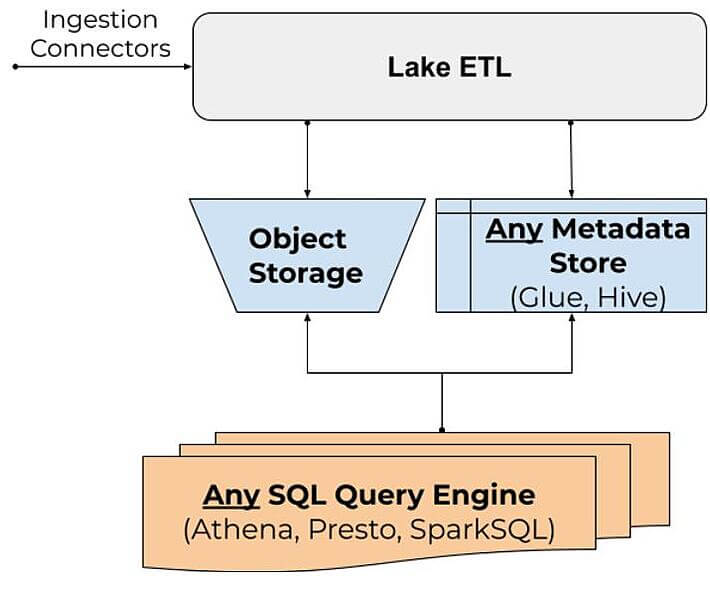
The challenge for data lake ETLs is how to keep the table data consistent in real-time for queries while maintaining good performance. This is how Upsolver SQLake does so, with Athena as an example query engine:
- A user in SQlake creates an ETL job, with the purpose of transforming raw data to a table in Athena with a primary key.
- Metadata – SQlake’s engine creates a table and a view in the AWS Glue metadata store with 2 types of partitions: 1 for inserts (new keys) and 1 for updates/deletes.
- Data – SQlake’s engine writes the table data to object storage using the standard data lake append-only model. By maintaining an index for the table primary key, SQLake can route each row to the right partition (insert or update/delete).
- Query – An Athena user sees the new table and view in the Athena console because Athena is integrated with the AWS Glue Data Catalog. Queries run against the view (and not the table) that joins insert, update, and delete rows from different partitions and returns exactly 1 row per key.
- Performance – This part is the trickiest to execute. Data lakes don’t include indexing, and a join of 2 large tables could create a number of issues. Therefore the performance of queries against the view deteriorates as the number of updates/deletes grows in the partition. Therefore SQLake rewrites the data every minute in a process called compaction (read more about compaction in dealing with small files), merging the updates/deletes from the original data. This process keeps the number of updates and deletes to a minimum so queries against the view are high-performing.
Key differences
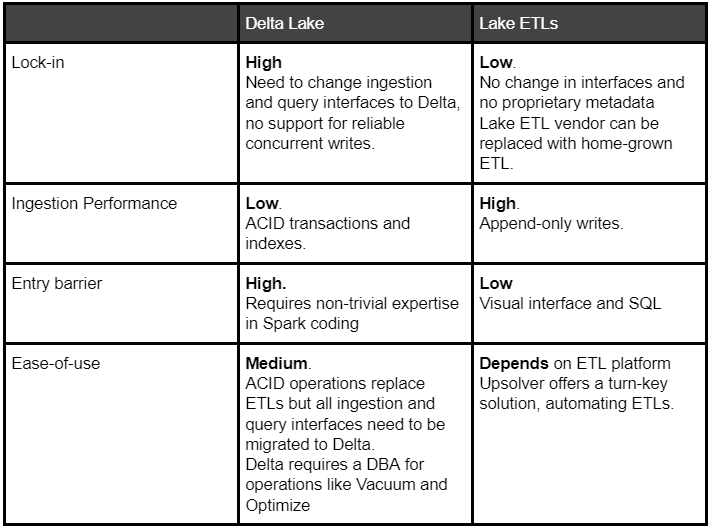
Lock-in to one query engine
Delta Lake tables are a combination of Parquet based storage, a Delta transaction log and Delta indexes which can only be written/read by a Delta cluster. This goes against the basic logic of a data lake which is meant to allow users to work with data their way, using a wide variety of services per use case.
To use Delta Lake, it’s necessary to change ingestion to use Delta ACID API and run queries using the Delta JDBC. Delta cannot ensure data consistency across partitions, while updates to partitions need to be done manually in order to ensure users see the most up-to-date version of a table.
Data lake ETLs only make changes to the underlying table data so there is no lock-in and any SQL engine can be used to query the data. Replacing a vendor for Lake ETLs doesn’t require changing ingestion or query APIs.
Ingestion Performance
Lake ETLs will out-perform Delta by an order of magnitude since they perform append-only writes to object storage while Delta needs to update indexes for each ACID transaction.
Ease-of-use
The Delta Lake approach offers a simple insert/update/delete API but requires a project to change existing ingestion and query interfaces to Delta.
While data lake ETL requires a significant ETL effort as explained above- especially when it comes to dealing with small files – platforms like SQLake can be used to reduce this effort to nothing:
Summary
Try SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free for 30 days. No credit card required.
To learn more about how SQLake works, read technical blogs that delve into details and techniques, and access additional resources, visit our SQLake Builders Hub.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
Published in:
Blog
,
Cloud Architecture