
Explore our expert-made templates & start with the right one for you.
What Is An Open Data Lakehouse? A World Without Monoliths
-
 Ori Rafael
Ori Rafael
- Data Lakes
- August 25, 2020
Welcome to The Cloud Lakehouse blog, where we’ll re-examine warehouses and lakes as we rethink the future of data platform architecture.
There’s been a 15-year battle between data lakes and warehouses.
In 2005 I started my career as a database engineer in the army intelligence — around the time Apache Hadoop was released to open source — allowing me to experience warehouses and lakes as an end-user and as a manager committed to timelines, budgets, and compliance.
Large enterprises used warehouses for a long time because they’re great for making data valuable. But warehouses can’t keep up with all data processing needs like streaming, machine learning, and exponential growth in volumes. Enter data lakes — though not the perfect alternative. It’s easy to store data cheaply in a lake (object storage), but it’s tough to make it valuable and easy to query. Whether you work on-premise or in the cloud, coding and expertise in the complex Hadoop/Spark stack turn the lake into a swamp.
In the last 3 years, data lakehouses entered the mix, which database and data lake vendors interpret in several ways. Some say data warehouses will cannibalize data lakes, and some say the exact opposite. These two paradigms have created a zero-sum game, but it doesn’t need to be that way. There’s a third option that combines the lake with multiple houses (from multiple vendors) to get the best of both worlds — the Open Data Lakehouse.
Let’s explore all three of these paradigms and the next evolutionary step in data infrastructure.
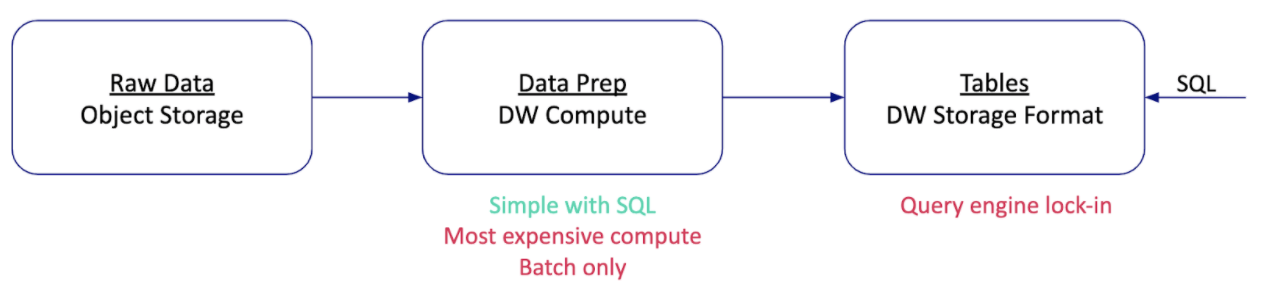
Paradigm 1: The cloud data warehouse is extended to the lake
Early on, I had to stretch the limitations of the data warehouse. Intelligence work is an internet-scale problem with many different use cases and thousands of analytics users. At the time, I could recite every tuning technique for the Oracle query optimizer. The work wasn’t easy, but it was SQL-based, so analytics access was widespread. If I had offered to replace the data warehouse with the cumbersome, code-intensive, Hadoop stack, I would get laughed out of the room. Fast forward to today, can the cloud data warehouse take over the entire value-chain and “eat” the data lake?
The main concern with this paradigm is creating a monolith. Not many would argue with the statement that Oracle DB is a monolith, but are cloud data warehouses any different in that sense? Oracle DB locks data behind a proprietary file format, so using an additional engine (for a use case like machine learning) requires replication. As a database engineer, I would bend over backward to implement my use case in Oracle — even if it’s not the right tool for the job — instead of creating a replication process that would lead to “fun” 2 AM conversations with operations. Cloud data warehouses aren’t different in that sense, and I personally don’t trust one vendor to deliver SQL analytics, streaming, machine learning, text search, etc. There is too much innovation in data analysis for me to opt-out of it for one vendor.
Paradigm 2: The lake replaces the warehouse
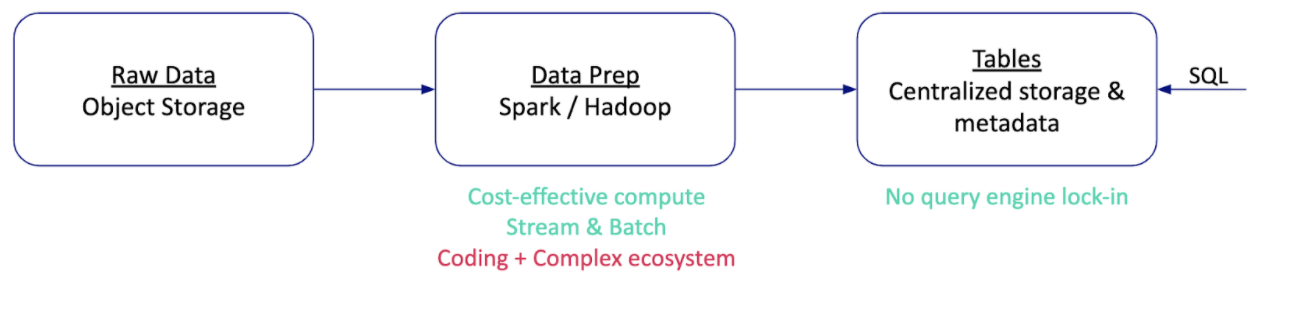
A few years ago, I built a data lake for an advertising use case. It was already in the age of the cloud, and I used Amazon S3 as my lake. If I was sweating to support tens of terabytes with Oracle, now I processed petabytes every month at less than 1% of the cost I knew from my database engineering days.
The downside was that I lost my ability to iterate over data. I found myself frustrated with long dev iterations, data consistency bugs, and long hiring processes for people with hyper-specialized skills. I felt like I was living in a home under continuous construction, and I was tired of talking to the “construction crew” instead of working with data that could help my business. The Spark stack we used was basically a faster Hadoop stack (there is a reason everyone is moving away from Hadoop).
A frequent question is if a solution like Delta Lake is a lake or a warehouse because it uses open source storage formats like Apache Parquet. I get the confusion, but Delta Parquet files are exactly like database changelogs — you don’t query them directly since the results won’t be consistent. You must use the Delta query API to get consistent results, but then how is Delta different from Oracle? It’s the same monolith lock. The best way to test database vendor lock-in and see right through an open source mirage is to ask, “is it possible to read the database files with other engines (without engineering hacks) and still get a consistent result?” For Delta, the answer is no.
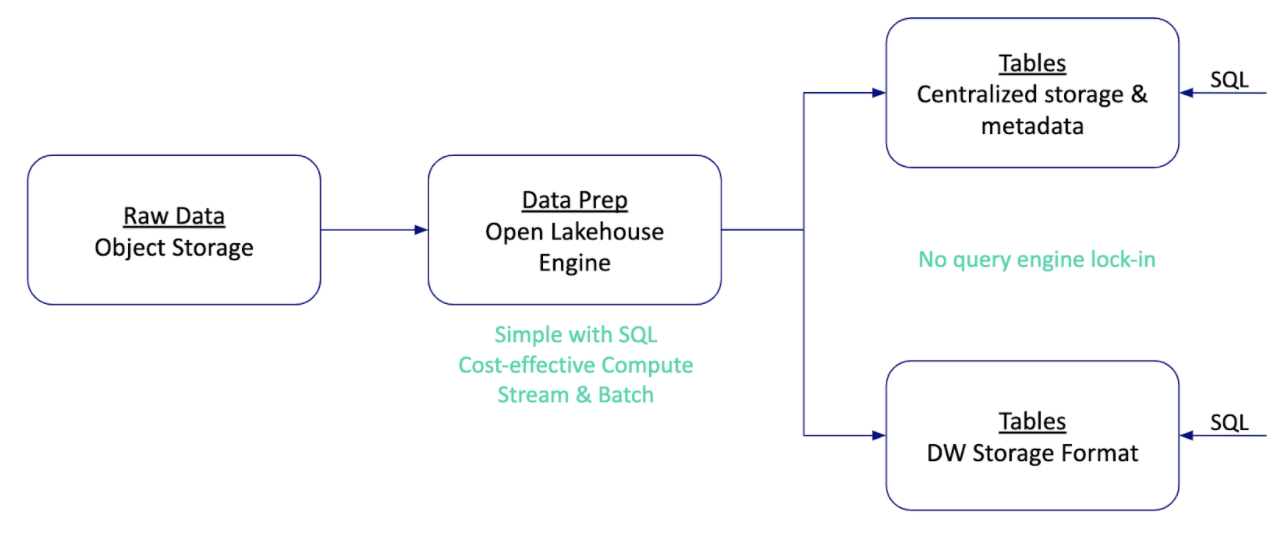
Paradigm 3: One lake, multiple houses
The previous two paradigms treated the problem as a zero-sum game of warehouse vs. lake, which is a direct result of vendors’ competition. The next leap forward and the lakehouse’s true purpose is to simplify the integration between a lake and multiple warehouses. One lake + multiple houses = the best of both worlds.
Some might be worried about the additional cost and overhead of multiple houses. Centralizing storage, metadata, and access control will solve this problem. For example, AWS offers S3 for storage, Glue Catalog for metadata, and Lake Formation for fine-grained access control. Services like Athena, Redshift, and EMR can all query the same copy of the data simultaneously, so there is no additional cost or overhead. A product that is now a database is very likely to become a pure query engine to reduce entry barriers.
Until the centralization transformation completes, it’s possible to ETL a portion of the lake’s data into the house of your choice. If you want to replace one house with another, simply point your ETL to a new target. Your total cost will be lower since data prep will be more cost-effective in the lake than in the warehouse (cheaper compute).
Final Words
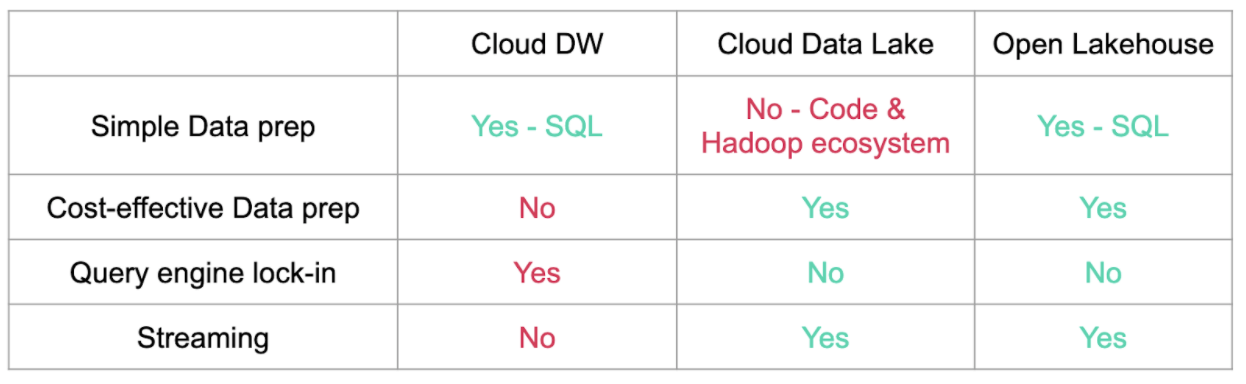
The purpose of an open data lakehouse is to achieve the cost and flexibility benefits of a data lake platform with the ease-of-use of a data warehouse. The following table sums up the main pros and cons we covered today:
It’s time to reevaluate our base assumptions of warehouses and lakes and make the open lakehouse vision a reality. Stay tuned.
Try SQLake for free (early access)
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes