
Explore our expert-made templates & start with the right one for you.
Cloud architects! Here’s how to decide between a data lake, a data warehouse, and a data lake house
-
 Upsolver Team
Upsolver Team
- Data Lakes
- May 5, 2021
Organizations of all sizes can now capture more data from more sources – more quickly than ever before.
But what good is all that real-time data if it takes six months until you can use it?
This conundrum is at the core of the data warehouse vs data lake debate.
On the one hand, you need a way to store all your streaming data quickly and easily – and data warehouses aren’t up to the task.
On the other hand, if you can’t query, model and analyze that data while it’s fresh enough to yield genuinely business-critical insights, why bother at all? This makes data lakes a less compelling choice.
So what’s a cloud architect to do? Accept the limitations of the warehouse? The inefficiencies of a lake? Pivot to a newer, hybrid concept: the data lake house?
Or, perhaps, a combination of all three.
Data warehouses: disciplined but limiting
Remember when all hard drives were formatted to work exclusively with Mac or PC?
If you ever wanted to use a different operating system, you’d have to first get a brand new storage drive, formatted differently, and copy all your data onto it, all over again.
Essentially, this is what data warehouses do.
They lock you in to a single vendor to process your data. Either because your storage and analytics are lumped in together, or because the processing engine requires your data to be formatted in a way that only this engine can understand. And while a hard drive is one thing, it’s hardly feasible to duplicate a warehouse-full of data for each processing engine you might want to use.
That said, when it comes to making your data readily available and valuable, you can depend on a data warehouse. Data prep with SQL is relatively straightforward. Querying is simple. It’s a well-organized, easily navigable approach.
At least, that is, for simpler data analytics pipelines.
Once you get into more complex data processing, like machine learning, log analytics, or streaming, data warehouses seriously struggle. Trying to store semi-structured data in a relational database format like a data warehouse can get expensive and inefficient. Not least because you have to go through a time-consuming process of cleaning and normalizing it so that it fits into the data warehouse structure.
The more high-volume, semi-structured data you use, the more time-consuming and expensive this gets. Data warehouses aren’t economical when dealing at coping with swathes of data streamed from IoT sensors, machines or logs – and they struggle with semi-structured, natural language text.
Data warehouses at a glance
| Pros
| Cons
|
The shift to data lakes
With data lakes, you don’t have get this problem. It’s a very affordable centralized repository for all your data, no matter what kind. Structured, unstructured… it can all go in the lake. And you can analyze it using whichever system is best fit for the purpose.
For example, you might stream data from a transactional database into your data lake so you can run analytics on it later on. You can move clickstream and other types of semi-structured data into your data lake in real-time, without forcing it into a relational database structure.
What you absolutely shouldn’t do, though, is take all that data and dump it in the lake. Unless you manage the data lake carefully, organizing your data as you go, locating it fast enough to be useful will become a mammoth task.
This brings us to the biggest issue with data lakes: it’s really hard to get value out of them. Sure, you have all this potentially valuable data in there, but you still need to get your head around where it is and how it fits together. You still need to prepare it for a processing engine to use it the way you want.
This can turn into a major headache.
More often than not, analysts are stuck waiting around for engineers to write complicated, customized Apache Spark code before they can access and organize the data they need.
Depending on the complexity of your data pipelines and the size of your data lake, it could take you 18 months just to build the data pipelines you need to get started!
Plus, if any issues crop up, your engineers will have to go back and tweak the code, potentially adding weeks to the process.
Data lakes at a glance
| Pros
| Cons
|
Best of both worlds: the open data lake?
The idea of a data lake house is to make it faster and easier to get value out of your data lakes, while letting you connect to as many different types of analytics engines as you like.
You use the data lake not just for affordable storage, but to create queryable data sets for use by various analytics platforms, probably through a connecting automation platform. Ideally, one that ingests and parses the data, lets you apply transformations but also join it with data from external sources.
You can think of this as a data lake engineering platform. You build your pipeline using a visual interface or SQL, and it handles operationalizing that as well as tuning the data for high-performance. No more Spark coding or intensive configuration for optimal file system management.
This cuts a ton of time and hassle from building your analytics project, adds value to the dataset and gets it as ready for processing as possible. You can build, test and deploy a new analytics project in days not months.
The key here is to use a platform that doesn’t save your data in a proprietary format. It needs to be open, so that any kind of processing engine can read the data from the data lake.
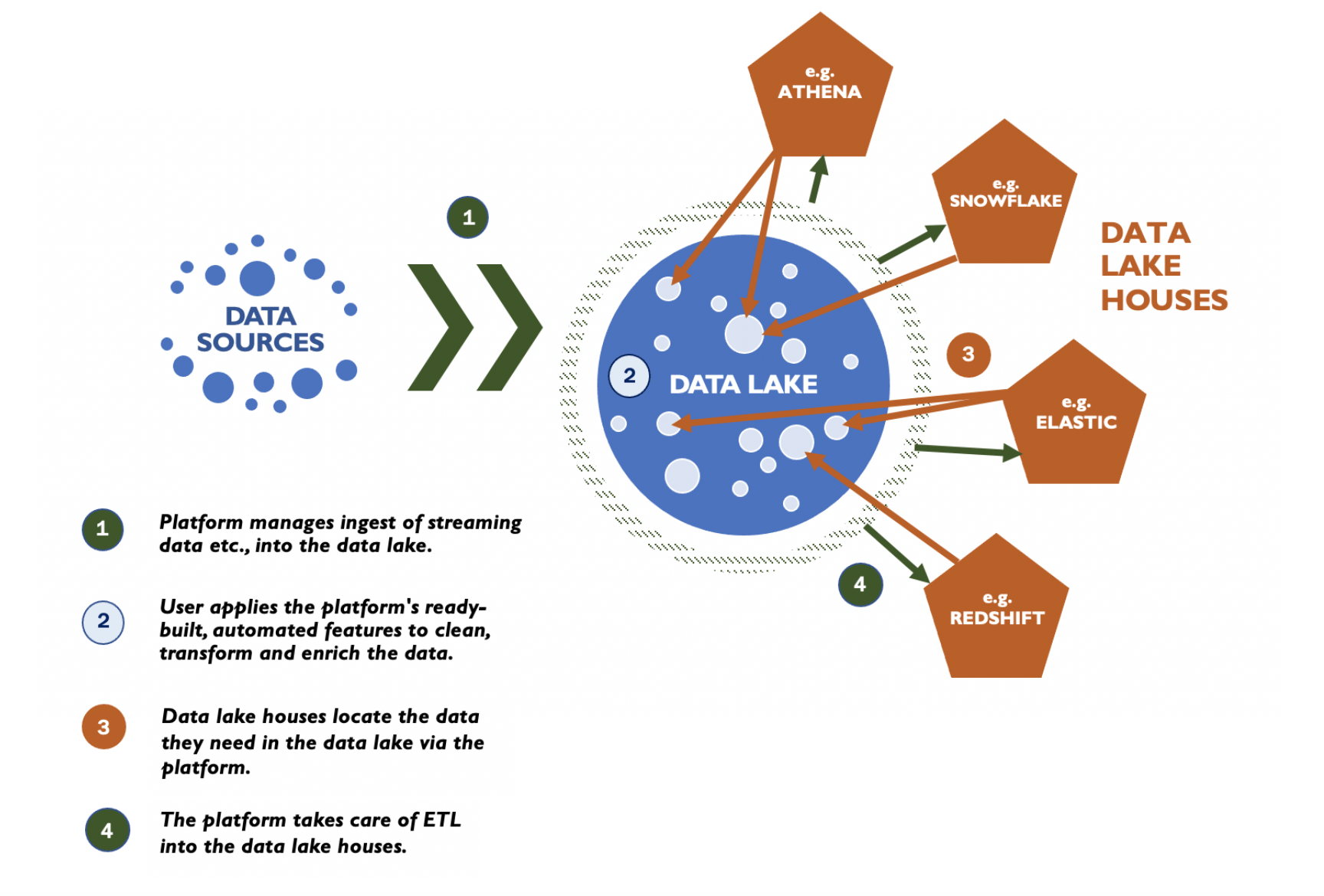
Rather than settling on just one vendor and using them for everything, you can then pick the best fit for the task at hand, such as SQL analytics or machine learning. For example, you might have Amazon Athena query the data in the lake directly, or send the prepared data to Snowflake for data science or Elasticsearch if you need to search log, IoT and semi-structured data.
You get the economics of a data lake, but the flexibility to make the prepared data available for analysis by a variety of systems, with higher performance and lower cost than if you’d sent your raw data there in the first place.
Each of these vendors becomes an analytics destination for the open data lake. But since they connect to the data in the lake via the platform, there’s no need for any complex coding. It’s all automated.
This is also handy if you discover a mistake in the data once it’s loaded into one of your lake houses.
When you’re dealing with data lakes the traditional way, just having an analyst come back and say there’s an issue with a column in a dataset in Redshift could mean weeks of painstakingly rewriting Apache Spark.
But in an open data lake house set up, you can track down the source dataset easily enough in the data lake. In fact, with a platform like Upsolver, you can alter your source dataset in just a few clicks and supply it back to Redshift. While you’re at it, you can duplicate the corrected data and update any other processing engines, too.
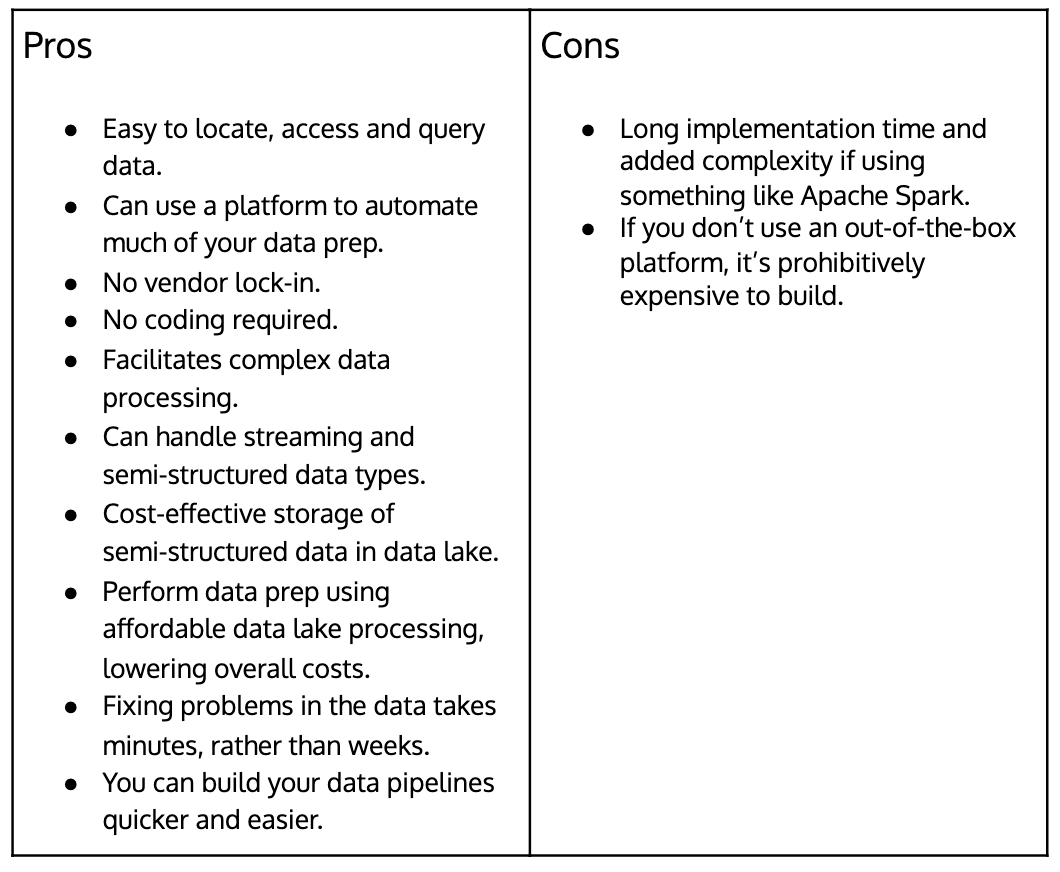
Open data lake at a glance
Final thoughts: The best of all worlds
The open data lake is an evolution of the data lake to leverage its cost and open-ness advantages over special-purpose analytics platforms while mitigating its historical weaknesses. It’s a way to make them more valuable by importing the best elements of data warehouses. Done right, this frees up your data to use how you want, in a time frame that works.
Is it possible to build your own solution to facilitate these connections and organize data inside your data lake?
Sure. But you’ll have to dedicate a ton of resources, invest heavily in the right people with the right skills – and, frankly, pray they never leave.
It’s far more efficient to use a platform built to support open data lake house architecture. One that lets you connect to any kind of processing engine you want. That enriches your data for you. That automates connections to data sources, external datasets and lake houses, so your team can always find precisely what they need – at speed.
Curious to see how data lake infrastructure works in practice? Schedule a demo of the Upsolver platform now.
Or try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes