
Explore our expert-made templates & start with the right one for you.
Big Data Infrastructure: When to Build, When to Buy
-
 Eran Levy
Eran Levy
- Cloud Architecture
- May 14, 2019
Every software development team makes build-vs-buy decisions on a regular basis. For most coding problems, someone is offering a packaged or white-label solution. The decision whether to purchase a tool or develop an alternative in-house – to ‘build or buy’ – is typically made ad-hoc based on cost, existing engineering skillsets and organizational culture.
However, barring the most ardent of open-source purists, it’s rare for an organization to do just one or the other; instead, developers will rely on a mix of purchased, proprietary and open-source technologies.
With that caveat in mind, let’s look at data infrastructure for big data projects: while here too any decision should be made on a case-by-case basis, we’ll suggest a few guidelines or general considerations that you should apply before choosing to go one way or the other.
Cloud Data Lakes: The Technical Whitepaper
Planning a change to your data architecture? First read our comprehensive Roadmap to Self-service Data Lakes in the Cloud to learn how you can achieve the performance and scale of a data lake architecture, without the technical complexity.
Infrastructure, Value and Costs
Defining ‘data infrastructure’ can be tricky, but let’s keep it simple and use the term to refer to backend technologies used to store and access data, and whose primary function is to enable other products or systems to work properly. When everything is in order, infrastructure should be invisible to data consumers outside of specialized organizations such as IT, DevOps, DataOps or Data Engineering.
Infrastructure is different from features, updates and bug fixes. The latter generate tangible value for the business, i.e.: they make the software better, more useful, mores sellable, etc. Whereas with data infrastructure, the best case scenario is that everything is working as expected; doing a perfect job will still not make your software more useful or sellable (while doing a bad job can be disastrous, which makes infrastructure work all the more thankless).
In other words: the connection between infrastructure and business value is murky. It’s difficult to explain to the CEO why you need to spend $200K on a data quality project rather than a new product feature. Hence most organizations will try to minimize the time and effort they spend on infrastructure – more so than for other types of software development projects.
When to Buy
If controlling costs is the key factor in most infrastructure purchasing decisions, you might be tempted to bias towards in-house development using readily available open-source big data processing frameworks (Apache Spark, Hadoop, Apache Airflow, and the list goes on and on).
However, as many engineering teams have learned the hard way, big data frameworks are no picnic for developers who don’t have extensive experience with them – there is an extremely steep learning curve, and ongoing optimization is a bottomless time sink. If you end up needing to increase headcount, or to devote a lot of your engineering resources to building and maintaining infrastructure, the total project cost will be astronomical.
You should lean towards buying rather than building if:
- You’re not good at big data. Most software teams outside of dedicated data infrastructure companies aren’t very familiar with the landscape and how to stitch together all the open-source components needed for storage, querying and orchestration. The further this stuff is from your core competencies, the more time and money you’ll need to spend learning it.
- You’re a smaller organization / can’t afford the headcount. According to Glassdoor, the average base salary of a big data engineer in the United States is a whopping $116,591 annually.
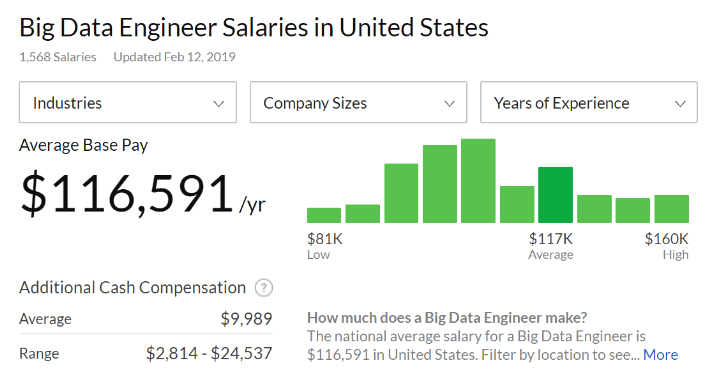
If your most talented and best-paid engineers are spending the majority of their time on infrastructure, your costs are likely going to be higher than you would be paying in software licensing costs.
- You want to move fast. In addition to costs, the complexity of big data projects and the need to implement several new technologies often results in long implementation times before the new infrastructure is actually in production. If you need something in production in less than three months, building a solution might not be feasible.
When to Build
While buying infrastructure products can be a good fit in many cases, it is not a silver bullet that applies to every scenario. If your organization already has a prominent and highly effective data engineering team, it might make more sense to keep using the development frameworks that they know and love. If your use case is extremely specific and will require a lot of custom development to do what you need, you might have no choice but to develop it in-house.

You’re better off building rather than buying if:
- You are very good at big data: same as before, but the other way around – the closer big data engineering is to your organization’s core competencies, the more you’ll feel comfortable developing your own big data infrastructure. Of course, this doesn’t necessarily mean pipeline development is the best use of your engineering resources; however, it is one sign that you should be less “afraid” of tackling an infrastructure project.
- You are working at insane scale or need something insanely specific: if you’re dealing with hundreds of petabytes of unstructured data, or need to run extremely complex and unorthodox queries – in other words, if you’re trying to achieve something that is very unique to your own use case – you’re unlikely to find a packaged solution to your problem. In these cases, developing might be the best way to go.
Striking the Right Balance
Finally, we should once again stress that the decision is never a binary choice between one or the other, nor is it a single decision. You’re probably going to buy some components, use open-source technologies for others, and do some development in-house from scratch. We’ve suggested a few guidelines for considering whether to buy or build a certain piece of technology – but it’s up to you to figure out what works best for your team at any given fork in the road.
Need a cloud solution for big data analytics? Check out how you can use Upsolver to analyze streaming data on AWS. Want to learn more about data architecture? Read about the 4 key components of a streaming data architecture.
Published in:
Blog
,
Cloud Architecture