
Explore our expert-made templates & start with the right one for you.
What is Big Data Ingestion?
-
 Eran Levy
Eran Levy
- Building Data Pipelines
- May 2, 2023
Big data ingestion is the process of collecting data from ‘big data’ sources – event streams, logs, or operational database change events (CDC) – and writing it into storage, typically in a format that supports querying or analytics operations.
That last part is where things can get tricky. A simple data ingestion pipeline might replicate events from a source system and dump them into object storage as raw files, in the order in which they arrive. This does not present any noteworthy challenges. But when you want to ensure data quality and downstream usability, there’s some work that needs to be done.
Big Data Ingestion vs ‘Regular’ Data Ingestion
You might be asking – how is this different from regular data ingestion? We’re not making this distinction because we think data engineering needs more buzzwords. The idea we’d like to highlight is that when you work with big data, there are some unique characteristics that make ingestion processes different. You’ll need to adjust your mindset accordingly when building your data pipeline architecture.
Sources, Targets, and Challenges
In traditional data ingestion, structured data is extracted from a source system, such as a relational database or an ERP system, and then loaded into a data warehouse (which is also a relational database). This would be a straightforward extract-transform-load (ETL) pipeline, where data is extracted from the source, transformed to match the target schema, and then loaded into the destination system.
In big data ingestion, sources and targets are different. More often than not, you’ll be working with streaming sources and data that might be semi-structured or unstructured – such as from server monitoring, app analytics events, IoT devices, or operational database CDC logs. Ingestion targets are storage solutions designed to handle the scale, variety, and complexity of big data – i.e., a distributed system such as a data lake, data mesh, data lakehouse, or a modern cloud data warehouse.
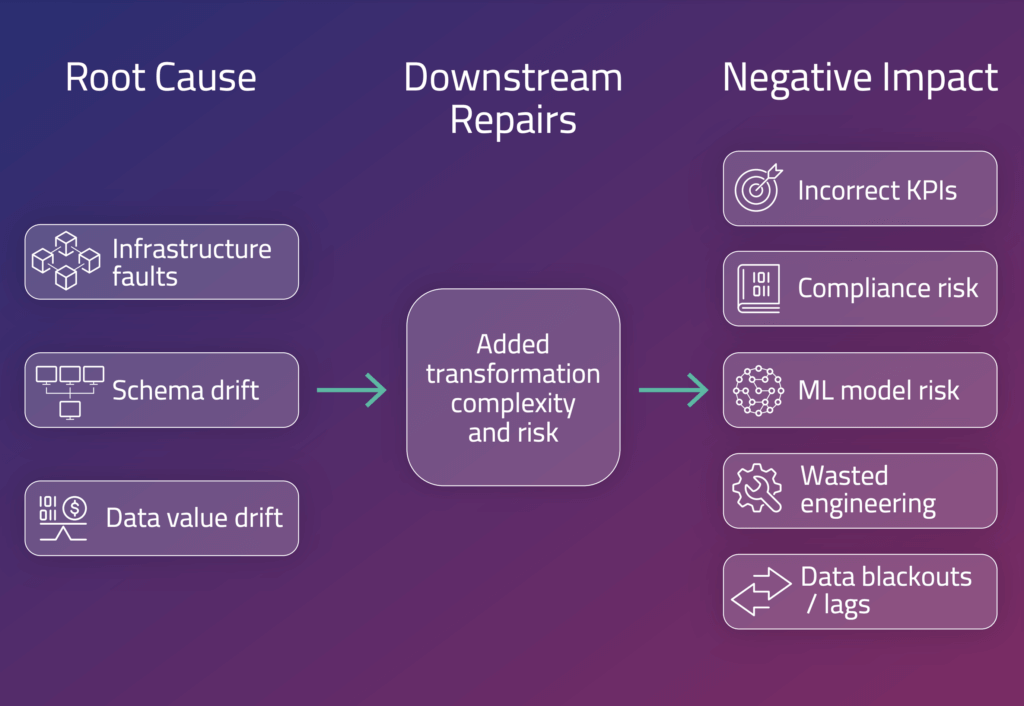
The set of problems you’re likely to encounter is also distinct. There are many moving parts when continuously ingesting and transforming event streams at scale. Human error or system outages often lead to severe degradation in data quality. Missing, corrupted, or poorly-monitored data necessitates costly downstream repairs and can create operational hurdles ranging from poor data availability and completeness, to potential security and compliance risk.
In the next section, we’ll take a closer look at some of the key data engineering concerns you need to address when implementing big data ingestion.
Data Engineering Considerations
For the sake of example, let’s say you’re working with a popular mobile gaming app that has millions of active users worldwide. The app generates massive amounts of data – user interactions, in-app purchases, and gameplay metrics – which are sent as events to your data ingestion pipeline.
As a data engineer, you’ll need to provide accurate and timely data to downstream apps such as analytics dashboards and recommendation engines. But there are several challenges you’ll need to overcome in order to build reliable ingest pipelines while ensuring data quality and availability.
On-time data
In our hypothetical example, the mobile game is the main revenue generator for the company. Stakeholders need to see key metrics – e.g., new signups by marketing campaign – in near-real time, since allowing an issue to persist for days could cost many thousands of dollars in lost revenue.
Meeting these requirements with traditional batch processing methods is difficult and costly. In order to make the data available for analysis in a reasonably-short timeframe, it needs to be ingested as a stream. At the same time, data needs to be correctly joined and aggregated so that the person viewing the Daily Signups dashboard sees accurate data. This becomes more complex the closer to real time the data needs to be (<1 hour is much simpler than <1 minute). In Upsolver, we’ve implemented the ability to check for new data every minute, continuously ensuring that if an event has been created it will make its way downstream on time.
Exactly-once processing
We need to ingest, process, and store each data record once and only once – meaning no duplicate events and no data loss, even in the case of failures or retries. In our mobile gaming scenario, doing this at scale will require coordinating efforts between multiple distributed systems while managing the complexities of network communication, processing, and storage.
This is a streaming-specific issue and thus won’t be addressed by most traditional data ingestion tools. (Whereas Upsolver the exactly-once guarantee is part of Upsolver’s big data ingestion.) When the pipeline tool can’t verify exactly once-semantics, data engineers must rely on a combination of frameworks and technologies to make it work in different pipelines. Going down this route, you’d also need to orchestrate custom logic to manage state, track progress, and handle retries or failures. The process is as time-consuming and error prone as you’d expect.
Strongly ordered data
In our example, we’re collecting millions of events from thousands of devices. Some of these events will arrive late, for example due to the device losing internet connection. However, we want our reports to reflect reality, which means ordering the records according to the time the event occurred, rather than the time the data was ingested.
Databases solve this problem through serialization – but in distributed systems, moving every event through a database introduces latency constraints and performance bottlenecks. And while Apache Kafka guarantees ordering within a single partition, you’ll still need to ensure that all the relevant events end up in the same partition – which is constrained by the volume of data it can store. In Upsolver, we attach a monotonically increasing timestamp to every event in order to ensure that all data is delivered exactly once and strongly ordered.
Continuous transformations
To make the data streams analytics-ready, they might need to be joined with other streaming or static sources. For example, we might want to join our app signups stream with data received earlier from advertising channels, in order to compare acquisition costs with in-app events.
When your data fits into a single database, joins aren’t a big deal. But handling continuous data integration and join operations in distributed systems can get messy. You’re going to run into compute and memory constraints, which will require you to redistribute and shuffle data between different processing engines. Upsolver tackles this by indexing the data lake upon ingesting the data, and storing the indices in memory. Alternative approaches would involve managing large broadcast joins in Spark, or paying a very significant premium to process the data in real time using a modern database such as Snowflake or BigQuery.
Normalization and data modeling
Big data sources such as mobile app events or system logs generate semi-structured data, with schema that tends to evolve over time (e.g., due to developers adding, removing, or renaming fields). We’ll want to normalize this data and apply a relational data model that will eventually allow us to query it with SQL. In addition, changes to schema will often need to be applied retroactively to historical records.
The traditional approach is to reload historical data from the time of the change, which requires a great deal of experimentation and testing and is a compute-intensive operation. Upsolver uses a different approach to automatically detect schema changes upon ingest and update output tables accordingly, and its observability features makes schema changes visible to the end user.
Controlling Costs
The need to continuously transform data while reshuffling it between different compute engines can drive up costs quickly. Relying on batch processing to avoid repeatedly scanning large datasets might reduce your cloud bill, but it adds barriers and latencies to data availability.
Upsolver’s big data ingestion optimizes costs by adding an indexing layer while ingesting the data (either to object storage or directly into a Snowflake data warehouse), and efficiently managing joins and data cleansing before writing the data to its final destination tables. This reduces the need to perform large transformations in a data warehouse or to run compute-intensive Spark jobs.
Solving for Data Quality
The bottom line from all of this is that from a certain level of scale, data ingestion is more than just replicating tables from source to target. Ingest pipelines become engineering challenges that require their own effort in order to prevent data quality degradation:
late events, duplicates, out of order events, or mishandled records.
Unoptimized data ingestion results in incorrect results being served to data consumers, wasted engineering effort to fix data downstream, and fragile transformation pipelines. Running full table scans to correct an error across billions of records (and terabytes of data) is a costly fix that most businesses would prefer to avoid.
Upsolver ensures data quality during ingestion by enforcing the delivery of exactly-once, strongly-ordered data for downstream analytics, and it does so for any scale or data freshness requirement. Upsolver also provides data observability – the ability to inspect and profile data, and send alerts in case of pipeline degradation.
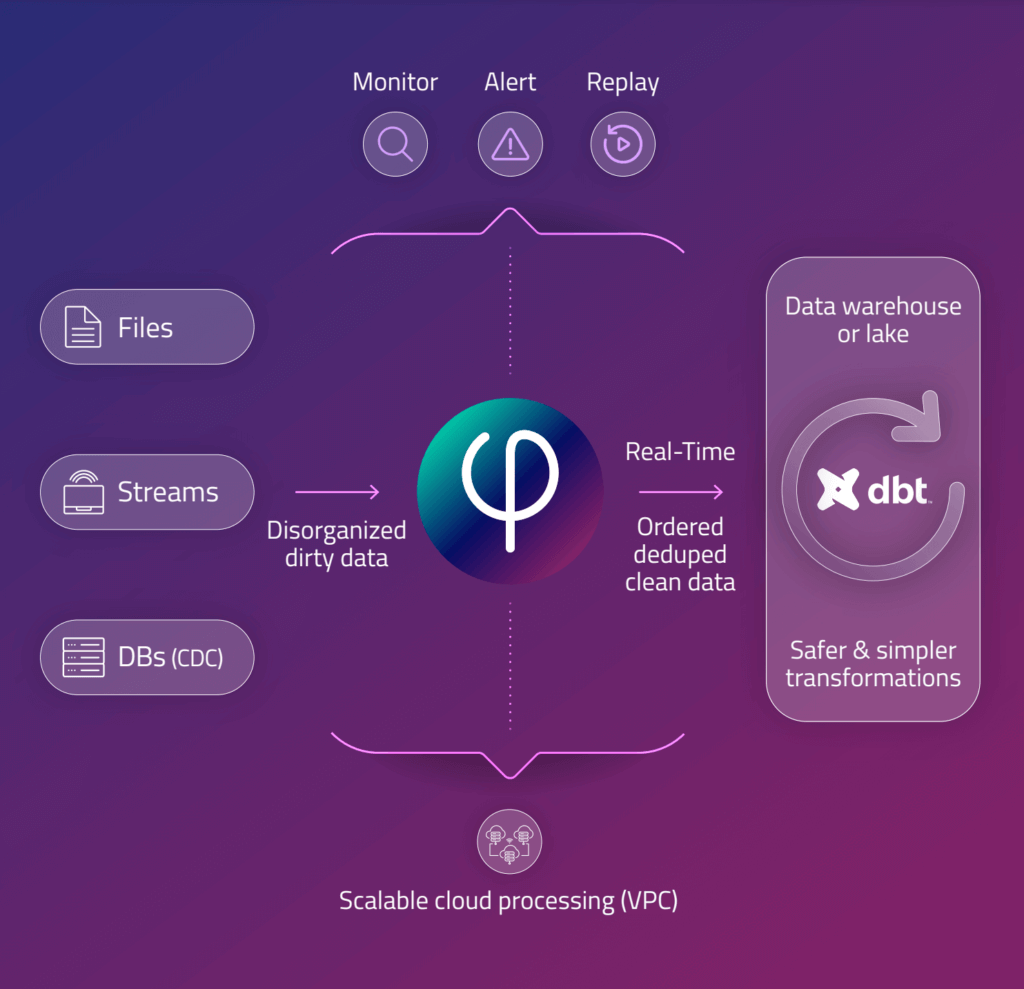
- Learn more about our unique approach to big data ingestion
- For an example of how this works in practice, read about writing data from Kafka to Snowflake
- Test drive Upsolver in risk-free trial (no credit card required)
Published in:
Blog
,
Building Data Pipelines
