
Explore our expert-made templates & start with the right one for you.
Guide to Change Data Capture (CDC) in 2023 – Pipelines, Challenges, Examples
-
 Roy Hasson
Roy Hasson
- Data Lakes
- January 20, 2023
What is change data capture (CDC)?
Change data capture is a data integration capability available with most major databases. It monitors, identifies and captures changes to your data and delivers them to external systems, commonly for analytics. Changes include adding, updating and deleting the contents of rows, and modifying the schema of a table.
Changes are captured in a transaction log stored in the database. This log goes by different names, for example in MySQL CDC it’s referred to as a binlog. In PostgreSQL it’s referred to as a WAL (Write Ahead Log). This log is a critical part of a reliable and resilient database design because it allows the database to enforce ACID properties and recover from failures.
An important aspect of CDC is the ability to ship these change events to an external system for further processing or archival. For years, we’ve been leveraging CDC to extract data from operational databases and load it into data warehouses and data lakes for the purpose of analytics, BI and reporting. However, CDC has traditionally been difficult to configure and manage. The tools we used to listen and collect these change events often failed. They also put undue pressure on operational databases, already under heavy load from applications, to deliver fresh data for analytics, resulting in database and application outages.
What are the challenges when implementing change data capture?
No single standard for CDC implementation methods
Operational databases like MySQL, PostgreSQL, Microsoft SQLServer, and Oracle Database have completely different implementations of CDC. This leads to unique challenges, limitations and corner cases that are difficult to manage and work around.
For example, change data capture in MySQL works by writing change events to a binlog. An external agent reads the binlog, keeps track of its position in the log, extracts the changed rows, then sends them to another system for further processing. This is what the open source CDC software Debezium does. Change data capture in PostgreSQL, on the other hand, uses the concept of replication slots. This allows the CDC tool to track the progress of the replication client (CDC listener) and recover if a connection drops. Each implementation has its pros and cons. They both require paying close attention to different aspects to ensure reliable delivery of change events and to minimize impact to the source database.
Configuration is vastly different across different database types
Configuring CDC database replication is vastly different across database types. As mentioned above, because implementations are different, so are the configuration steps and behavior. This makes it difficult to share best practices or have a battle-tested “golden config”. Some companies standardize on a single type of database such as PostgreSQL or Oracle to mitigate this problem. Others may have different types of databases, by choice or not.
Existing methods are not suitable for analytics
The transaction log implementation was not originally designed to extract data for analytics. It was built to replicate changes between primary and secondary DBs or primary and read replicas. These are systems that are continuously synching data, unlike an analytics system where a CDC listener may only read the PostgreSQL WAL every 10 minutes or hourly, depending on the batch processing schedule. Periodic collection of change events requires the database to retain WAL files for the length of time between batch job runs. This results in storage filling up, which increases the possibility of a database crash.
What about Amazon’s “zero-ETL”?
At re:Invent 2022, AWS announced support for “zero-ETL” solution that tightly integrates Amazon Aurora with Amazon Redshift. This eliminates the need to configure and manage CDC on Aurora MySQL and PostgreSQL for replicating to Redshift.
This solution is convenient if your use case is to replicate operational data into Redshift, perform transformations there (ELT) and serve datasets to analysts and BI users. If this is you, the zero-ETL solution may be a viable option. However, if this solution is only part of what your business requires – you need the flexibility to deliver data to multiple analytics systems your users require and apply different transformations for different use cases – then you still need to build a more flexible CDC solution and you should keep reading.
Why do you need change data capture? Benefits of CDC tools
There are several reasons why you need to deploy a CDC solution. The main ones are:
Managing access to multiple cloud and on-prem databases
There are many types of databases located on-cloud and on-premises that you need to access, if not today then tomorrow. Each requires a different way to access and replicate data.
I’ll try to explain using a simple analogy. When you establish a new village, one of the first things you want to do is connect it to other villages and towns. But you’re still small with few people and resources so you decide to only lay down a few unpaved, dirt roads. The roads work fine, but you need to have the right kind of car and skills to navigate them, no signs. As the village grows into a town, the roads need to be improved, so you pave the main ones and leave the side roads unpaved, for now. As time moves on and you now have a sizable city, you decide to build highways connecting your city to other major cities. You also start to pave your side roads so it’s easy for everyone to get around.
CDC evolved in a similar way. Initially it was used only to connect primary with secondary DBs or read replicas. You needed specific experience to use this technology to extract events and write them to a data warehouse – unpaved roads. As CDC became more popular for analytics, new tools came on the market, the dirt roads were paved. Tools like Fivetran (via the HVR acquisition), Airbyte and Upsolver SQLake paved the side roads to make setting up CDC simple.
Now we’re entering the phase where we need to build highways. Amazon Aurora and Amazon Redshift are very popular products that customers want to move data between – think driving between New York City and Boston. To reduce friction, AWS built a highway – “zero-ETL” connection. In the future, expect more highways to be built between popular data solutions. But we will always need side roads that lead us to the many other cities and villages that still exist, like self-hosted databases, those hosted in other clouds or on-prem and popular up-and-coming ones like graph and time series databases.
Data lakes provide more flexibility for historical data storage
Moving operational data to a data warehouse is not always desirable because you may have non-analytics use cases like archiving or ML model training. A data lake, based on data stored in an object store like Amazon S3, is ideal to manage very large datasets, archive immutable copies and to give access to non-SQL tools like Notebooks and distributed training (such as Ray).
Some CDC solutions on the market only give you the option to replicate data to a data warehouse or another database. Although analytics have been the primary use case for CDC, the need for data to serve a wide range of use cases continues to grow, if not accelerate. Therefore, a more flexible CDC solution is required.
Transformations are typically required after the data is replicated
In the majority of cases, zero-ETL is not possible and some transformation and modeling is always required. Data in operational stores is modeled to meet the needs of the application that uses it. Oftentimes this data model is not intuitive to users that are performing analytics on it. The operational data model is also not optimized for analytics type queries, such as computationally expensive joins. You need a transformation step, to restructure, clean, normalize and validate the quality of CDC data before it can be used for analysis.
Two Approaches to CDC architecture: ELT and ETL
You can transform data in a staging area before loading it in a data warehouse (ETL), or you can load it into the data warehouse in its raw state, and transform it there (ELT).
In the ELT pattern, data is replicated using a dedicated CDC tool connected to a data warehouse. The raw data is merged (upsert and delete) automatically to reflect the state of the source database. Then, you would schedule and orchestrate queries that model and transform the data to meet business needs.
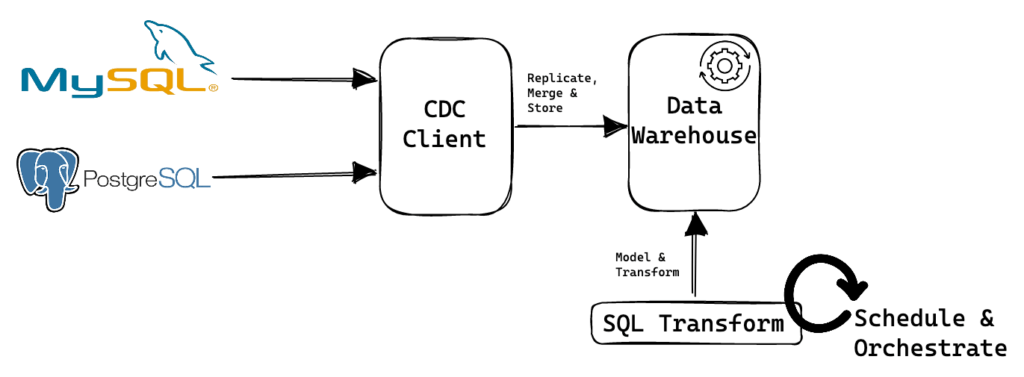
In the ETL approach, data is replicated using a dedicated CDC tool, then it is consumed in near real-time by an ETL engine like Apache Spark or Flink. The engine then merges the data into a data lakehouse table like Apache Iceberg or Hudi. Either during or after the data arrives, data modeling and transformation is performed to apply business logic. In a different blog post, we presented an example of CDC ETL.
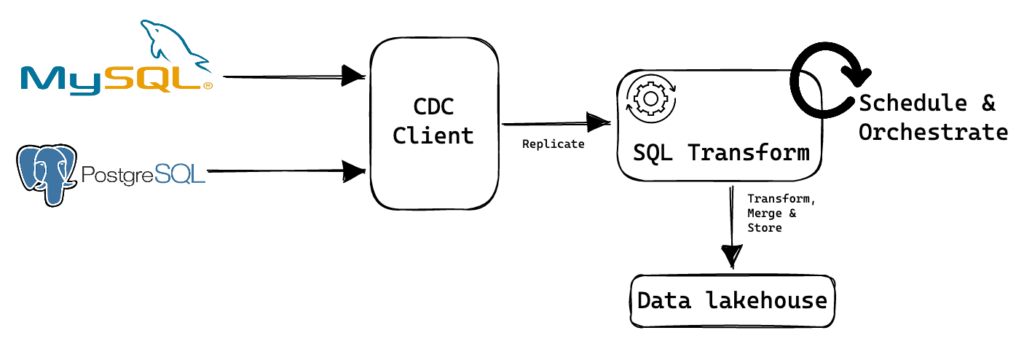
Building change data capture (CDC) pipelines in Upsolver SQLake
Upsolver SQLake follows the ETL model, comprising of 3 steps:
- Configure the CDC client to read and replicate change events
- Stage the raw events
- Model, transform and merge change events
Let’s walk through each step.
Step 1 – configuring the CDC client
For listening to changes and replicating events to a target system, SQLake embeds the Debezium Engine, a popular open source solution. Why not just use Debezium? Well, Debezium requires Kafka Connect (self-hosted or managed by Confluent) which in turn requires you to deploy a Kafka cluster. If you are self-hosting, you will be forced to handle redundancy, high availability and Debezium failures – all on your own. Our customers loved the power of Debezium, but hated managing it alongside Kafka Connect (too many dependencies).
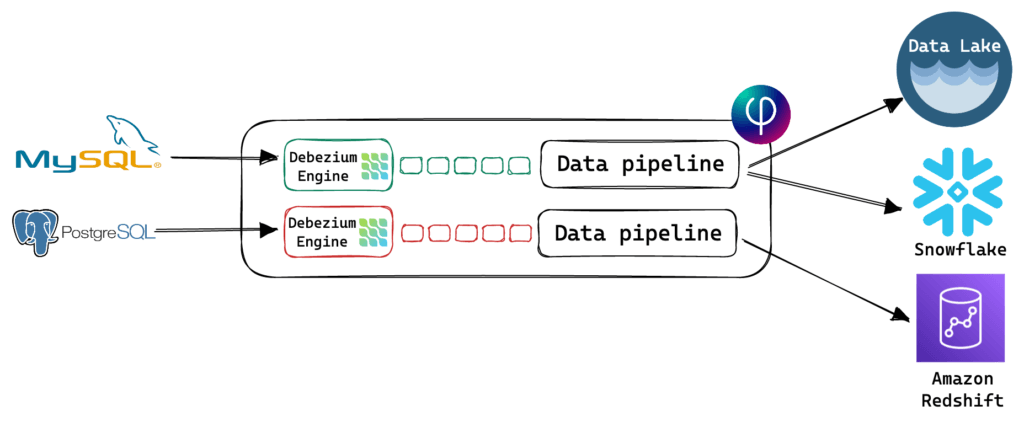
When we designed the CDC solution for Upsolver SQLake, we wanted to simplify the architecture for customers. We decided to integrate Debezium directly into SQLake. This unifies the power, flexibility and features of Debezium, with the scalability and ease of use of a fully-managed SQLake platform.
The following diagram shows how SQLake utilizes the Debezium Engine to support CDC:
Connecting to a source database in SQLake using the embedded Debezium Engine is as simple as creating a connection, like this:
CREATE MYSQL CONNECTION ops_mysql_v8_2 CONNECTION_STRING = 'jdbc:mysql://host.region.rds.amazonaws.com:3306/demo' USER_NAME = 'your username' PASSWORD = 'your password';
The SQLake connection holds the connection string and credentials. It needs to be created only once by a DevOps or cloud infrastructure engineer, and then can be reused by as many jobs as you require.
Step 2 – staging CDC events
A unique capability of SQLake is that it automatically stages all incoming, raw data in the data lake first. Reading events and staging database changes into a landing zone prior to loading a target system is a critical step that is not a common practice with other CDC solutions such as Fivetran/HVR.
This provides several key benefits:
- You can query and access the raw, unfiltered data from your choice of tools
- You can easily time-travel and reprocess data from any point in time
- Reprocessing is highly scalable and doesn’t impact your source systems
- You can reduce the storage costs of your source systems because historical data archived in the data lake
- You can backup and archive the full state of your source databases in case of failures and disaster recovery
We often talk about real-time change capture, but in actuality that is the running state, as changes are continuously being made to the database. The initial phase of CDC is to replicate the current state of the tables. When you first connect SQLake, or other CDC tools to your source database, the engine needs to first snapshot the tables you selected for replication. This allows you to copy the historical data and bootstrap your target system. After that you begin to capture and merge live changes.
Let’s see how to create a replication job in SQLake.
CREATE TABLE default_glue_catalog.ops_db.ops_mysql_v8_2_staging()
PARTITIONED BY $event_date;
CREATE SYNC JOB ingest_ops_mysql_v8_2_staging
AS COPY FROM MYSQL ops_mysql_v8_2
TABLE_INCLUDE_LIST = ('sales.customer', 'sales.salesorder)
INTO default_glue_catalog.ops_db.ops_mysql_v8_2_staging;
You see here that we have two commands. The first creates a table in the data lake to stage the raw data. The second creates a job to copy events from the source database, using the connection you created in the first step, and writes them to the staging table.
This job does two things. First, it takes a full snapshot of the source tables and writes them to the staging table. These snapshots are performed in stages and are scheduled to avoid overloading the source database. Second, after the snapshot operation is complete, the job begins to replicate the changed events in real time to the staging table.
The staging table serves a very similar function to the MySQL binlog. It maintains an append-only, immutable copy of every event from every table chosen for replication. The staging table is partitioned by date and full table name – database.schema.table. This results in a denormalized wide table, containing all of the columns from all of the replicated tables. SQLake also includes metadata columns to provide additional hints useful in filtering and replaying the data.
Before we move on, let’s compare this approach to one used in the Modern Data Stack (MDS), an ELT approach to CDC.
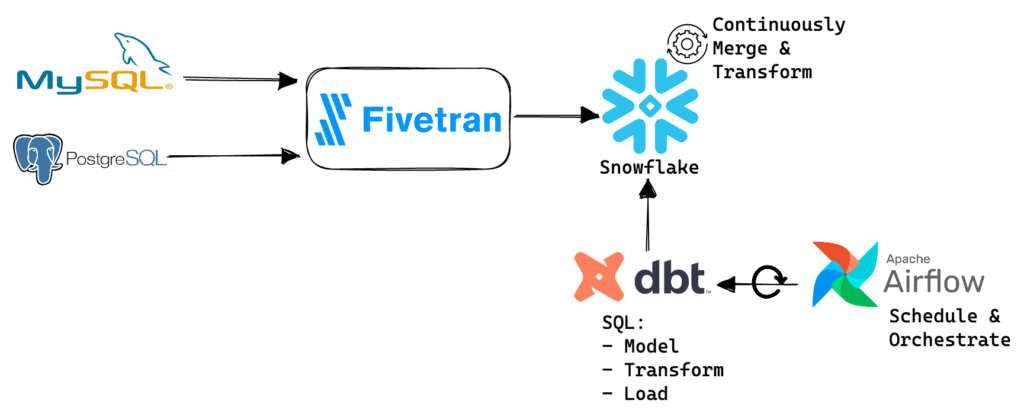
The MDS approach highlighted in the diagram requires you to set up and manage Fivetran to perform CDC. Fivetran writes the change events to Snowflake. These events are not stored as an append-only log, like in SQLake. The rows are merged to represent the final state of the source tables. To accomplish this, Fivetran executes SQL queries on Snowflake to merge the data.
Although this approach appears more convenient, only storing merged rows means you’ve lost the ability to time travel and reprocess events. Without access to raw data for replay, it is very difficult to fix corruption, fill-in gaps or simply enhance the data, like recalculating taxes or changing time zones. To regain this benefit you need to build and manage custom logic like SCD Type 2 or create pipelines that pull data from the source system every time you need to reprocess, which adds operational overhead and cost.
Up to this point, you have only ingested the CDC data (E and L). You now need to store, model, transform and clean it inside the data warehouse (T). In the MDS model, you commonly use dbt to define your SQL models and transformations, Apache Airflow to schedule and orchestrate the pipelines, and the data warehouse for the processing. Not only is this architecturally complex, but continuous real-time processing is not cost-effective in a data warehouse, as they are designed and priced for batch processing. As noted above, for CDC, ELT is a less flexible and far more expensive solution than the ETL approach SQLake uses. This becomes even more of an issue as data volume, frequency of updates, the variety of sources and use cases increase.
Step 3 – model, transform and merge
The staging table is now populated with rows from all of the replicated tables, partitioned by date and full table name. Next, you select the tables you want to publish. Then, you model, clean, prepare and merge the data before loading it into your data lake or data warehouse.
Let’s look at an example:
CREATE TABLE default_glue_catalog.prod.customer(
customerid string,
partition_date date
)
PRIMARY KEY customerid
PARTITIONED BY partition_date
COMPUTE_CLUSTER = "Default Compute";
CREATE SYNC JOB job_merge_customer_table
START_FROM = BEGINNING
ADD_MISSING_COLUMNS = TRUE
RUN_INTERVAL = 1 MINUTE
COMPUTE_CLUSTER = "Default Compute"
AS MERGE INTO default_glue_catalog.prod.customer target
USING (
SELECT *,
customerid,
$is_delete AS is_delete,
$event_date AS partition_date
FROM default_glue_catalog.ops_db.ops_mysql_v8_2_staging
WHERE $full_table_name = 'ops_mysql_v8_2.sales.customer'
AND $event_time BETWEEN run_start_time() AND run_end_time()
) source
ON target.customerid = source.customerid
AND target.partition_date = source.partition_date
WHEN MATCHED AND is_delete THEN DELETE
WHEN MATCHED THEN REPLACE
WHEN NOT MATCHED THEN INSERT
MAP_COLUMNS_BY_NAME EXCEPT source.is_delete;
This job produces results where any inserts, updates or deletes to the source customer table, tracked in the staging table, are automatically merged into the target table. Querying the target table will return the most current values belonging to the customer table. The staging table will still hold all of the raw changes if you later need to reprocess the data in a different way.
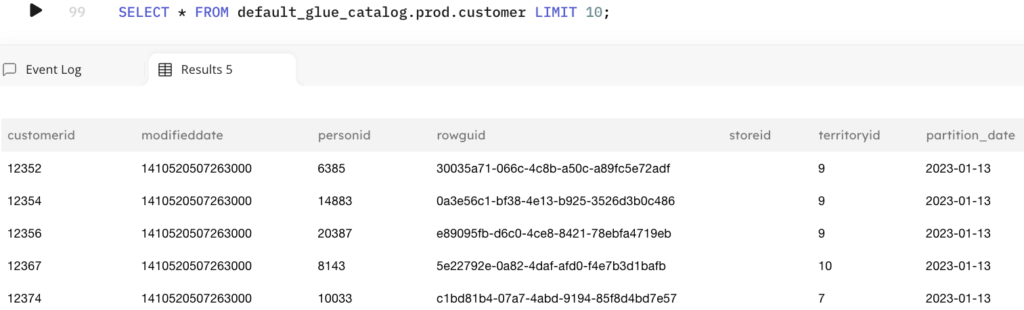
You can take this a step further. When loading data into the data warehouse or data lake, you may have sensitive information, like PII or PHI. You can easily redact and mask these columns prior to loading into the target table for users to consume.
Here is an example of masking credit card details:
CREATE TABLE default_glue_catalog.prod.salesorder(
sales_order_id string,
partition_date date
)
PRIMARY KEY sales_order_id
PARTITIONED BY partition_date
COMPUTE_CLUSTER = "Default Compute";
CREATE SYNC JOB job_merge_salesorder_table
START_FROM = BEGINNING
ADD_MISSING_COLUMNS = TRUE
RUN_INTERVAL = 1 MINUTE
COMPUTE_CLUSTER = "Default Compute"
AS MERGE INTO default_glue_catalog.prod.salesorder target
USING (
SELECT
salesorderid AS sales_order_id,
customerid AS customer_id,
STRING_FORMAT('{0}{1}', '#####',
SUBSTR(creditcardapprovalcode, -4, 4)) AS credit_code_masked,
creditcardid AS credit_card_id,
accountnumber AS account_number,
purchaseordernumber AS purchase_order_number,
$is_delete AS is_delete,
$event_date AS partition_date
FROM default_glue_catalog.ops_db.ops_mysql_v8_2_staging
WHERE $full_table_name = 'ops_mysql_v8_2.sales.salesorder'
AND $event_time BETWEEN run_start_time() AND run_end_time()
) source
ON target.sales_order_id = source.sales_order_id
AND target.partition_date = source.partition_date
WHEN MATCHED AND is_delete THEN DELETE
WHEN MATCHED THEN REPLACE
WHEN NOT MATCHED THEN INSERT
MAP_COLUMNS_BY_NAME EXCEPT source.is_delete;
Querying the output table returns the masked fields as expected:
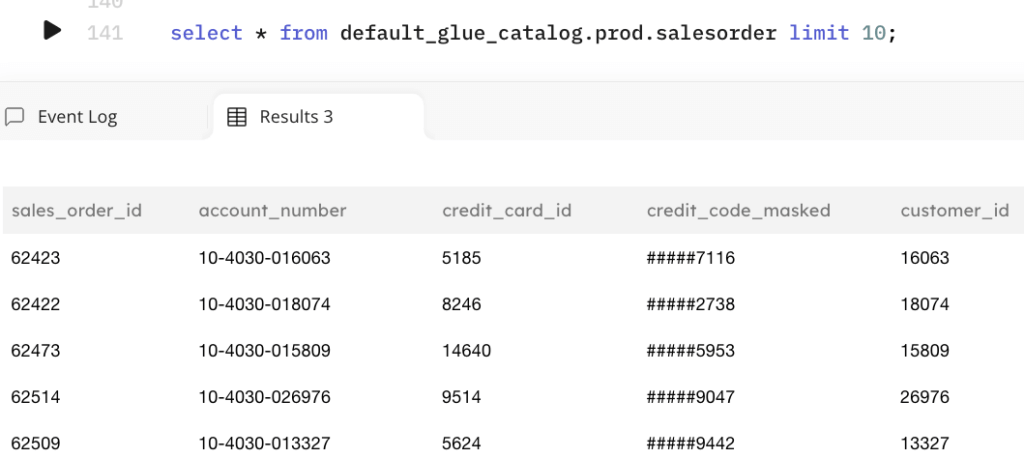
There is much more to data preparation
Nearly every replicated dataset requires some form of data preparation, such as modeling, cleansing and PII masking. However, there is much more that you can accomplish by performing computation before loading results to your data warehouse. SQLake is at its core a powerful stream processing engine that efficiently compute intensive operations that may require maintaining large amounts of state. Operations like multi-way joins, window functions and aggregations across wide ranges of time. Performing these operations in SQLake can reduce your data warehouse compute and storage costs.
In summary
Upsolver SQLake allows you to build change data capture (CDC) pipelines using only SQL. With SQLake, you easily replicate data from operational databases to your data lake, data warehouse and other analytics systems or applications. SQLake’s unique approach embeds the Debezium Engine to provide a feature-rich and battle-tested CDC implementation. This eliminates the complexity and difficulty of configuring, deploying and maintaining Kafka and Kafka Connect clusters typically required to run Debezium. Processing of change data capture events is handled by SQLake’s advanced batch + stream processing engine, allowing you to automatically scale from a few events to millions of events per second.
With SQLake, the raw change events are replicated into a scalable staging zone. Doing this enables you to easily and cost-effectively archive and reprocess past events without the need to go back and extract data again from the source system. This approach allows you to save money by reducing your source database retention and shifting raw data storage to the data lake. To reduce storage costs even further, you can choose to enable Amazon S3 intelligent tiering.
Three simple steps to build a change data capture (CDC) pipeline using SQLake:
- Configure a connection to the source database and select tables to replicate.
- Create a job to copy rows from source tables to append-only, immutable staging tables in the data lake.
- Create jobs to pick tables from staging, model, clean and transform them, and merge the results to an output table in the data lake, data warehouse or another system. Output tables continuously update as changes are emitted from the source.
Once SQLake pipeline jobs are executed, they continue to run without any manual orchestration or scheduling. Orchestration of jobs and synchronization between them based on availability and readiness of the data is managed by SQLake. You don’t need to develop or manage any manual orchestration logic – a massive productivity win. Compute resources scale up and down to handle spikes or dips in volume and velocity of incoming data.
Finally, SQLake’s disruptive pricing model eliminates the need to count rows. You are only charged for the amount of data you ingest. If you need to reprocess or reuse the data, you don’t pay again.
Try SQLake today for free. Get started quickly with one of our prebuilt change data capture (CDC) pipeline templates.
Published in:
Blog
,
Data Lakes