
Explore our expert-made templates & start with the right one for you.
Implementing CDC: 3 Approaches to Database Replication
-
Dima Etkin
- Change data capture
- February 2, 2023
Learn how to create query-able tables from your operational databases with Change Data Capture (CDC)
Data replication has been around almost since the birth of databases. Early uses included integration between heterogeneous systems and data centralization (via the enterprise data warehouse).
Change Data Capture (CDC) is not a recent invention, either. It was devised to identify and capture changes happening in the database. Much has already been said about it, but the main idea remains the same: CDC is an efficient way to de-silo and democratize an organization’s data, so the enterprise can derive business value from its data, rather than just hoarding it or keeping a copy to please the auditors. Heck – in a lot of cases CDC has even brought enterprise teams closer, so instead of fighting about the scope of responsibilities, people actually change their mindset and start collaborating to maximize the value of their shared data.
What is fresh is the paradigm shift from a locked and heavily-guarded data warehouse (DW) to an open data lake (DL), or using the data lake as the engine for data warehouse use cases in a Data Lakehouse architecture. Moving away from batch-oriented data distribution to streaming data pipelines opens up new ways to leverage this data, by having both change propagation and event-based architectures built on top of the same stream. Thus a CDC capability to make databases available to all becomes essential for any modern data architecture.
In this post, we discuss the different CDC approaches and patterns, and cover CDC capabilities in Upsolver SQLake that make it an indispensable tool in high-performance data pipelines.
Why replicate data?
One of the most compelling and frequent use cases for data replication is to stream changes from OLTP systems to a single source of truth for downstream manipulation or distribution, while protecting OLTP system SLAs by avoiding resource contention from analytics queries. This was the primary use case during the good old EDW days, and it remains relevant in the age of the data lake / data lakehouse / cloud data warehouse.
This approach appeals to mature organizations with legacy core systems because the data, methodology, and expected outcomes all are usually well known in advance. This helps organizations plan ahead and significantly shorten time-to-market for data related projects. Financial organizations are good examples. They tend to have multiple siloed data sources, yet must provide data-driven insights across numerous lines of business, all while maintaining a secure, fraud-free and complaint environment.
Digital age companies face a different challenge. Software applications are released via rapid development cycles, data is generated continuously as customers use the apps. Development teams instantiate new databases and create new tables every day, and people immediately adopt new features. But the business may lag behind in analyzing these new and rapidly-multiplying data points. Frequently, companies are forced to replicate the contents of entire OLTP databases before they can find an actual use for the data, so that data scientists can mine the data without impacting the source systems.
For example, in the online games industry, improving the game experience is an iterative process; each successive iteration generates more data, potentially dictating a different approach to data for the next iteration.
Comparing database replication approaches
CDC is one of multiple methods to replicate a database. Furthermore there are several flavors of CDC. They are all oriented to a single purpose – to determine and track what has changed so that the current state of the database can be shared and accessed by the maximum number of analytics users. Of course we can react based only on the changes, but to obtain a complete view of data evolution in time we need to get the data baseline (“snapshot”) and then apply to it all the changes that have occurred within a given timeframe.
But for now let’s put the snapshot process aside and focus on different approaches to handling the changes that occur afterwards.
Delta by comparison
Extract the changes by unloading the current snapshot of a source table and comparing it to an earlier snapshot.
| Pros | Cons |
| Gets the job done, eventually. | – Slow – Compute-intensive – Labor-intensive – High impact on the source database – Schema is not provided within the data, but rather as a separate external artifact, making it difficult to parse the data automatically |
Timestamp-based CDC
Selecting all records with a “last modified” timestamp greater than the base value passed to the query.
| Pros | Cons |
| – Faster and less labor intensive than the “delta” approach – Easy to extract the changes – Supports Deletes | Updates | Inserts | – Compute-intensive – Does not support Deletes – Requires an extra timestamp column and associated index for optimal performance – Schema obtained via manual DB queries – Compute-intensive – each DML happening on the source table has an extra DML penalty caused by corresponding change tracking table inserts plus trigger execution overhead – Labor-intensive to maintain the setup – Very high impact on the source system – Schema should be obtained via manual DB queries |
Transaction Log-based CDC
DB Transaction Log API returning a list of table data changes happening after the base timestamp (or LSN/RBA/SCN/… – relative offset of a log record in the log)
| Pros: | Cons |
| – Easy to extract the changes – Supports D/U/I – Contains schema within the data – Non-intrusive | – Requires access to DB Transaction Log |
Replication Patterns
Having covered some examples, let’s explore common data replication patterns. Using the right tools for the job greatly improves your experience, helping you maintain a positive attitude towards your assignment. Data replication patterns are those tools. They include:
- Unidirectional replication
- Bi-directional
- Multi-directional
- Consolidation
- Broadcast
- Cascading data propagation.
Bi-directional and multi-directional replication are patterns of specialty data integration tools used mostly for database mirroring, where clustering is either unavailable or impossible due to technological overlay. Other patterns are used in more generic scenarios to distribute data in 1-to-1, 1-to-N, or N-to-1 patterns.
Upsolver supports the following patterns:
1. Unidirectional
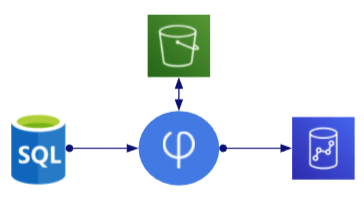
| Description: | Read changes from a single source system and write them to a single target system |
| Usage: | Propagate source changes to a single target for further processing (HDS, ODS, event-based architecture) |
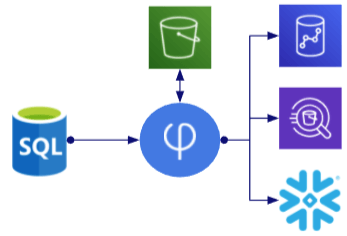
2. Broadcast / Cascading
| Description: | Read changes once and apply to multiple targets |
| Usage: | Propagate source changes to multiple targets for further processing to enable multiple usages in parallel |
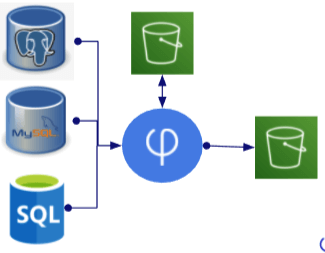
3. Consolidation
| Description: | Replicate changes from identical or similar schemas on different sources to a single schema on a single target |
| Usage: | Consolidate changes from multiple hosted systems into a single set of tables to facilitate simpler analysis |
Upsolver SQLake Architecture for CDC
Now that we’ve reviewed CDC methods, let’s look into the Upsolver SQLake approach. SQLake is a cloud service for building continuous data pipelines. It unifies data from streaming and batch sources and allows you to define pipeline logic declaratively using only SQL. Orchestration and optimization tasks are automated (e.g. no Airflow DAGs to build).
It enables you to ingest data from streams, files and databases into a data lake to create a single immutable source of true data, which can either:
- Serve as a final destination
- Become a central data hub for direct access by query engines, or
- Continuously serve prepared and blended data to purpose-built data stores such as data warehouses, databases and search systems.
With SQLake, you can perform complex transformations on the incoming data, including aggregations, joins, nested queries, and the like. All of this is accessible through an IDE that enables you to design pipelines using a notebook-style SQL code editor or alternatively, a CLI. The Upsolver platform automatically handles data lake performance optimizations such as compaction, partitioning, conversion to column-based file formats, and orchestration.
When you use SQLake for CDC, the system first takes a complete source data snapshot and stores it in the data lake. Once this task is complete, a new CDC stream starts replicating changes to the source data into the data lake raw zone. From there you can transform the data and write it to the desired data store. Transformations range from simple data cleansing and normalization to complex operations that ensure consistent Operational Data Store (ODS) or Historical Data Store (HDS)-like results on the target system. The target system could be the data lake (it can perform upserts and deletes directly into the data lake) or a cloud data warehouse such as Snowflake or Amazon Redshift.
Regardless of the target, SQLake stores all database changes in an immutable log on inexpensive cloud object storage. This allows you to time travel (gain access to every previous state of the database) and reprocess data as needed without going back to the source database.
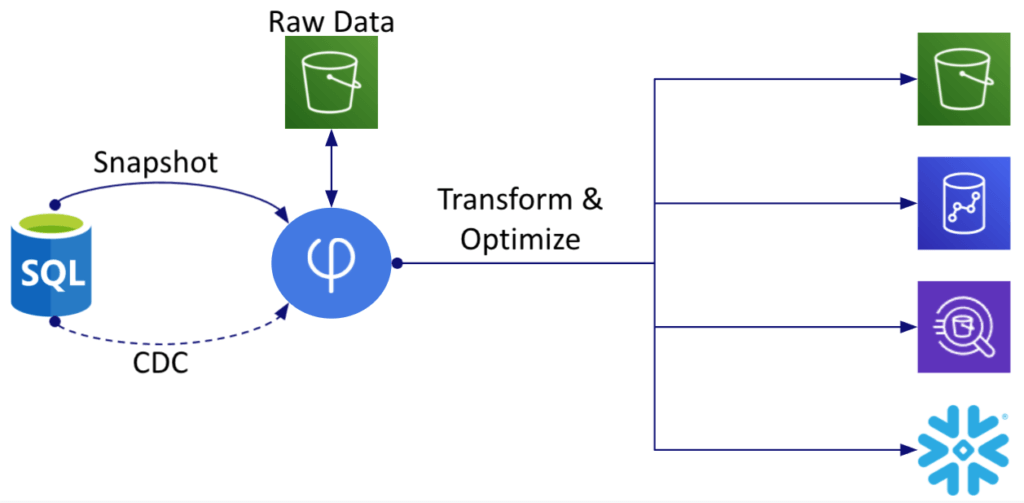
How SQLake makes log-based CDC simple and powerful
This section explores the differentiating features of SQLake that are so highly valued by our customers.
Dynamically Split Tables on Key Field
Upsolver’s specialty is data stream processing. We’ve leveraged this to create a unique, simple, and powerful CDC feature. Upsolver can dynamically split a single data stream into multiple tables based on the values of a key field, which could either be a field in the original data stream or added as a function of inbound data/metadata. Upsolver customers in data-intensive industries such as gaming and digital ads apply this capability in non-CDC use cases, but it also applies to CDC streams.
Stateful Transformations
Most CDC tools specialize in reliable data movement and have limited to no native transformation capabilities. This means the data must be transformed in the destination system, which, if it’s a data warehouse and the data flow is continuous, can be come very expensive, additionally so if there are other data sources that must be copied to the DW for blending with the CDC data.
SQLake is a scalable stream processing system which can perform transformations extremely quickly and cost-effectively by leveraging AWS data lake resources such as S3 and EC2 Spot instances. This allows you to stage your database replica in the data lake and from it create derivative tables for use via query engines, data warehouse or applications.
UPSERTs on the Data Lake
Traditional CDC tools can land database changes as raw data in a data lake. But they cannot maintain table consistency in the lake without your building a separate process. Merging updates/deletes is challenging since the data in the lake isn’t indexed – it is only partitioned by time. Upsolver automates this process.
Time Travel and Reprocess Data from a Previous State
With Upsolver, raw data ingested from the source system can be stored indefinitely or retained for a predetermined duration. When using data replication, Upsolver keeps the raw data – both the initial baseline snapshot as well as all changes since that snapshot. This is another paradigm shift when compared to other data integration products on the market. It enables Upsolver (or any other solution accessing the democratized S3 storage) to “Rewind-Replay” all of the changes from the initial “snapshot” as many times as necessary when updating the data pipeline logic or when directing the data into an alternative output/target for different use cases. And Upsolver accomplishes this without accessing the data on its original database source.
Schema Evolution
No CDC discussion is complete without mentioning schema evolution.Upsolver CDC detects and replicates changes to schema in the source system. With a simple SELECT * statement (yes – contrary to all known best practices Upsolver’s SELECT * is recommended and required to successfully implement schema evolution) any columns created while the CDC process is running are automatically reflected on the data lake replica. This is possible due to Upsolver’s schema-on-read capability. If a column has been dropped in the source database, it is maintained on the target and its data nullified for all the new records.
Summary
In this article we’ve discussed high-level concepts related to CDC and drilled into Upsolver’s unique capabilities related to CDC-based database replication. In the next BLOG post dedicated to CDC we will discuss the details of setting CDC up in Upsolver and show how easy it is to unsilo and democratize your organization’s data while optimizing the overall costs associated with data operation.
Next steps
Want to learn more about CDC and SQLake?
- Try SQLake for 30 days free – risk free. SQLake gives you an all-SQL experience for building and running reliable data pipelines on streaming and batch data.
- Read this step-by-step walkthrough implementing CDC in SQLake.
- Attend a SQLake 60 Minute Hands-On Workshop
- Request a demo to chat with an Upsolver Solution Architect
Published in:
Blog
,
Change data capture