
Explore our expert-made templates & start with the right one for you.
Database Replication – Why Do It, and How to Do It Right
-
 Jerry Franklin
Jerry Franklin
- Data Lakes
- May 16, 2021
If you replicate the data in your transactional databases into mass storage you can unlock all the intelligence, insight, and other value contained in the data. Here we lay out:
- All you can gain from replicating your database
- What your options are for doing this
- How you can easily automate the process without sacrificing data integrity or blowing out your budget.
Why replicate a database
Database replication, while often painful, is a must:
- For performance, since transactional databases must be preserved for operations. Any extracurricular reporting or processing could impede performance, which in turn would negatively impact a number of things – SLAs, customer wait times, fraud prevention, and so on.
- For redundancy, to enable error recovery, trace data lineage, or perform exploratory analysis. (This is becoming less of an issue for inherently backed-up cloud databases than for on-premises data.)
- For compliance, for example to satisfy data residency requirements.
- For cost, as object storage in a data lake is much cheaper than keeping data in transactional database systems.
Freed from the constraints of preserving an operational database, you can do whatever the business wants to get needed insight from the data:
- Engineering can use Elasticsearch to run analyses on log files.
- Business analysts can use Athena for ad hoc queries.
- Data scientists can use SageMaker to train and deploy machine learning models.
- You can combine operational and historical data to unearth patterns and trends from your earliest data; operational databases only contain relatively recent data, and usually only the most recent state of a data point.
You can also replicate data in multiple ways. For example:
- Replicate operational data to a data lake first and then then send hot and transformed data to a data warehouse (or other analytics engine) for real-time streaming analysis. You can keep cold data in the lake for regression testing.
- Enrich data as you replicate it, for example joining or aggregating tables for new insights and better forecasting.
In essence, replicating your data gives you the best of both worlds, combining the compute functionality of a database with the near-unlimited capacity (and cheaper storage) of a data lake.
Challenges in Database Replication
If you’re not careful you could run into issues of data integrity and technology lock-in, either of which impairs the value you derive from your data.
Change Data Capture – Keeping it all up to date
When replicating your transactional database to free up your operational data for analysis, you must be assured of exactly-once processing of event streams – no losing or duplicating messages.
- You can use open-source frameworks to ingest data into object storage such as Amazon S3, Azure Blob, or Google Cloud storage. But this is notoriously difficult to implement, requiring a lot of time-intensive and error-prone manual coding.
- You can employ change data capture (CDC) as a design pattern, to update records in your storage layer based on updates to the replicated database. But this is taxing to configure and maintain, especially when you add new data sources or schemas, or when data volumes grow very quickly.
Keep the Keys to Your Data, or Hand Them Over?
Few organizations can afford to manually build the pipes and transform the data they need to provide real-time analytics to support a wide range of business cases. Regardless, building your own monolith essentially is just creating a 1990s ERP system on steroids.
You have two options:
- A proprietary data warehouse (such as Snowflake) or data lake (such as Delta Lake)
- An open data lakehouse
While using a data warehouse differs in some ways from using a data lake, in either case you’ll be putting yourself in the vendor’s hands. They’ll replicate your database, manage your storage, your pipelines, your analytics, your architecture, and so on. They’ll take on much of the complexity of building out your data architecture for you.
That’s good.
But the pace of data innovation is breathtaking – new companies automating different pieces of the puzzle, new architectures, exploding volumes of data, billions of dollars of new investment. Why lock yourself out of all this innovation? Because if you do:
- It might be almost impossible to use a tool not in your vendor’s stack.
- Getting the precise data you want out, appropriately transformed, may not be possible without expensive re-work.
- Business agility will be significantly impeded, as you won’t be able to rebuild and maintain your data pipelines in response to business changes.
- You won’t have the elasticity you may need to scale up or down, for example if your business is seasonal.
- If you expand into new geographies, adding on another layer of governance may be difficult.
When you hand the keys to your data over to a single vendor, you are essentially putting the growth of your business in their hands. You’re also at their mercy should they change their cost structure; they have your data and they control the computing environment.
Learn more about database replication strategies.
Replicate Data, Retain Control, Reduce Complexity
You can now automate out much of the complexity and cost of creating a data architecture that best suits your enterprise.
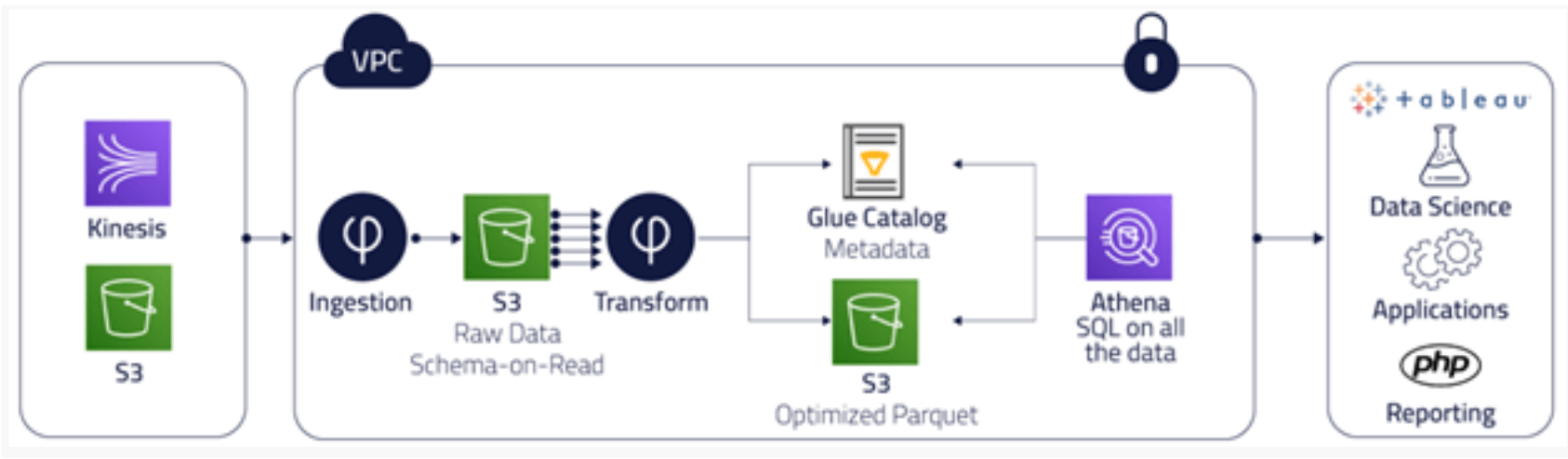
Upsolver is a no-code data lake platform that combines data lake economics with database simplicity and speed. Upsolver connects natively to event streams or existing object storage. It stores a raw copy of the data for lineage and replay, along with consumption-ready Parquet data – including automatic partitioning, compaction, and compression. When data is in object storage (S3, Azure), Upsolver performs transformation and aggregation before making your data instantly available to other systems – Glue Data Catalog, Elasticsearch, search engines such as Athena, Presto, or Qubole, data warehouses such as Snowflake or Redshift Spectrum, and so on. You gain the flexibility you need to use the analytics tool of your choice.
Upsolver ensures exactly-once processing from Kafka or Kinesis via idempotent operations. This ensures all relevant records are updated. As updates occur, Upsolver detects the changes and then writes those changes to your target database, whether it’s Athena, Redshift, another data warehouse – anywhere. Upsolver forestalls data drift (that is, it keeps data copies from diverging), no matter whether your business logic changes or there are errors in code. CDC happens automatically and continuously.
It’s also easy to enrich data. Upsolver implicitly indexes the data and creates Lookup Tables. Lookup Tables enable joins between data streams and data lakes at a cardinality of billions of keys, with query response in milliseconds. Upsolver also provides more than 200 functions out of the box, such as joins, aggregations, calculations, and conversions. In addition, Upsolver has built in automated best practices, including columnarization, compaction, compression, partitioning, metadata management, and more.
With Upsolver, you can architect a solution suited to the data needs of your organization, while preserving business agility and technical flexibility to keep up with business dynamics.
Replicating Success
Peer39 is an innovative leader in the ad and digital marketing industry, daily analyzing more than 450 million unique web pages holistically to contextualize the true meaning of page text/topics. Their products enable advertisers to optimize their spend and place ads in the right place, at the right time, with the right audience.
With its IBM Netezza infrastructure approaching end of life, Peer39 chose Upsolver to help it replicate all its data and update its aging legacy technology stack. Within one month, Upsolver provided Peer39 with a modern cloud-native stream processing platform with an easy-to-use no-code UI.
With Upsolver successfully deployed, Peer39 processes 17B events daily and has:
- realized a 90% reduction in Athena query latency
- dramatically improved the performance of ad targeting and digital marketing campaigns
- onboarded new publishers and data providers within minutes instead of weeks
Summary
Replicating a database is the first step in unlocking the full value of your data. Upsolver gives you the widest possible latitude to build the open data lake you need. It simplifies and manages the orchestration of your data as you replicate and store it, preparing it for use by the services of your choice. You can build and run complex stateful transformations on at-scale batch and streaming data on your data lake – all without writing code.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Sign up for a demo for a thorough overview.
Published in:
Blog
,
Data Lakes