
Explore our expert-made templates & start with the right one for you.
Dealing with Small Files Issues on S3: A Guide to Compaction
-
 Eran Levy
Eran Levy
- Data Lakes
- August 31, 2021
Get a copy of the new O’Reilly report, Unlock Complex and Streaming Data with Declarative Data Pipelines – available for FREE exclusively through Upsolver. Grab your copy now to learn how industry leaders modernize their data engineering work with declarative data transformation tools. Get the report now
Streaming data is typically made up of many small files. Event-based streams from IoT devices, servers, or applications arrive in kilobyte-scale files, easily totaling hundreds of thousands of new files, ingested into your data lake each day. It’s generally straightforward to write these small files to object storage (Amazon S3, Azure Blob, GCS, and so on). But querying the data in this raw state, using any SQL engine such as Athena or Presto, isn’t practical. Queries can run 100x slower, or even fail to complete, and the cost of compute time can quickly and substantially exceed your budget.
Small Files Create Too Much Latency For Data Analytics
As a typical example, let’s take S3 as our target for ingesting data in its raw form before performing transformations afterward. Since streaming data comes in small files, typically you write these files to S3 rather than combine them on write.
But small files impede performance. This is true regardless of whether you’re working with Hadoop or Spark, in the cloud or on-premises. That’s because each file, even those with null values, has overhead – the time it takes to:
- open the file
- read metadata
- close the file
This only takes a few milliseconds per file. But multiply that by hundreds of thousands, or millions, of files, and those milliseconds add up.
Query engines struggle to handle such large volumes of small files. This problem becomes acute when dealing with streaming sources such as application logs, IoT devices, or servers relaying their status, which can generate thousands of event logs per second, each stored in a separate tiny JSON, XML, or CSV file. Querying the prior day’s worth of data and results can take hours.
In addition, many files mean many non-contiguous disk seeks – another time-consuming task for which object storage is not optimized.
Compaction – Turning Many Small Files into Fewer Large Files to Reduce Query Time
The way to address this “small files” issue is via compaction – merging many small files into fewer larger ones. This is the most efficient use of compute time; the query engine spends much less time opening and closing files, and much more time reading file contents.
You can approach this via purely manual coding, via managed Spark services such as Databricks or Amazon EMR, or via an automated declarative data pipeline engine such as Upsolver SQLake. The latter requires only that you know SQL.
Let’s briefly examine each method.
Compacting Files Manually
Traditionally, companies have relied on manual coding to address the small files issue – usually by coding over Spark or Hadoop. This is a time-intensive process that requires expertise in big data engineering. It’s also generally performed along with allied methods for optimizing the storage layer (compression, columnar file formats, and other data prep) that, combined, typically take months of coding, testing, and debugging – not to mention ongoing monitoring and maintenance – to build ETL flows and data pipelines, as per a detailed, complicated list of necessary best practices.
And there are many nuances to consider – optimal file size, workload management, various partitioning strategies, and more. So when writing a script that compacts small files periodically, here’s what you must account for:
- Define an algorithm for identifying when a partition is qualified for compaction based on current number of files, their size, and the probability of future partition updates.
- Delete uncompacted data, to save space and storage costs.
- Keep your file size as big as possible but still small enough to fit in-memory uncompressed.
- Avoid table locking while maintaining data integrity – it’s usually impractical to lock an entire table from writes while compaction isn’t running. The best practice is to write new data to both the compacted and uncompacted partition until compaction is finished. But be very careful to avoid missing or duplicate data.
Compacting Files in Proprietary Platforms
Proprietary managed services such as Databricks and Amazon EMR now include compaction as a way to accelerate analytics. But while they facilitate aspects of streaming ETL, they don’t eliminate the need for coding. You must write a Scala or Java script to repartition the data, then another script to compact the repartitioned data, then run the vacuum() command to delete the old data files to avoid paying to store the uncompacted data.
And there are additional nuances involved. For example, in Databricks, when you compact the repartitioned data you must set the dataChange flag to false; otherwise compaction breaks your ability to use a Delta table as a streaming source. You must also ensure you do not corrupt the table while updating it in place. And data is locked while the compaction process executes, which causes a delay in accessing the most recent data.
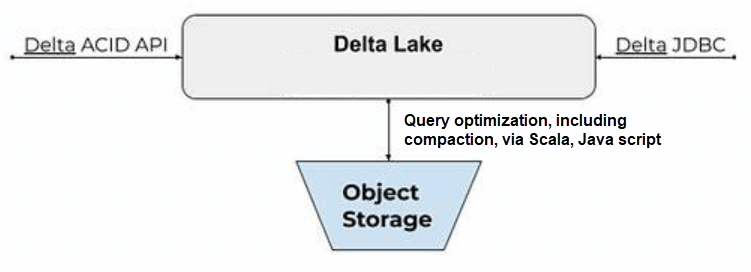
Open Platforms that Automate File Compaction For Consistent Query Optimization
To be sure, resorting to manual coding to address the small files issue can work quite well. However, the process is time-intensive, complex, and error-prone.
Upsolver SQLake fully automates compaction, ingesting streams and storing them as workable data. In the process, SQLake continuously merges small event files into larger archives – 500 MB each, to stay within comfortable boundaries. And it handles this process behind the scenes in a manner entirely invisible to the end user.
SQLake is designed for streaming data. You can upsert or delete events in the data lake during compaction by adding an upsert key. This key is the identifier of each row that is updated. For example, if you wanted to keep only the latest event per host, you would add the host field as the Upsert Key. When compaction takes place, only the last event per upsert key is kept.
How Upsolver SQLake Solves the Small File Problem via Continuous No-Locking Compaction
When you define the upsert key in a SQLake workload, SQLake starts keeping a map between the table keys and files that contain them. The compaction process looks for keys in more than one file and merges them back into one file with one record per key (or zero if the most recent change was a delete). The process keeps changing the data storage layer so the number of scanned records on queries is equal to the number of keys and not the total number of events.
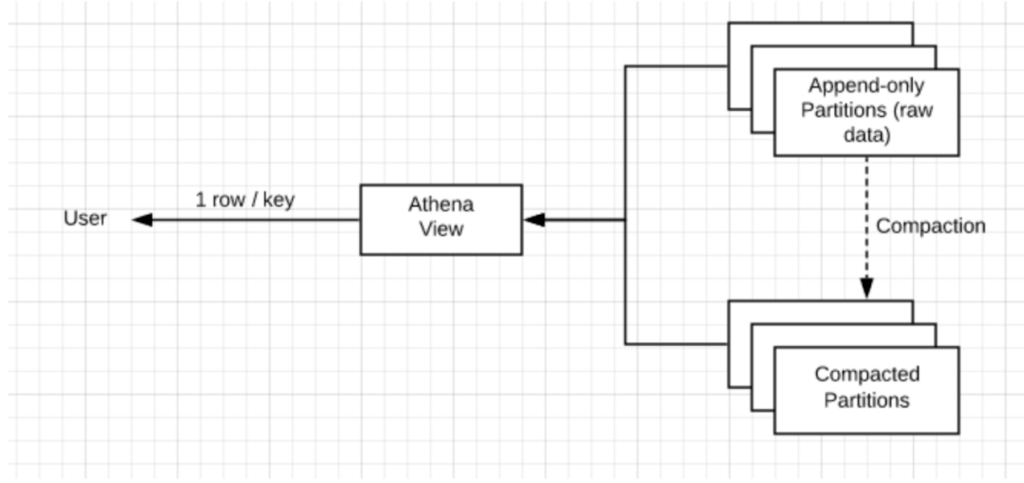
After writing data to storage, SQLake creates a view and a table in the relevant metastore (such as Hive metastore, AWS Glue Data Catalog). The table has two types of partitions:
- Append-only, for new data
- Compacted, for data with just 1 entry per key
To ensure a consistent result, in the append-only partitions every query against the view scans all the data. The compacted partitions only require scanning until finding the first result (the 1 entry per key, mentioned above). Keeping the append-only partitions small is critical for maintaining fast queries, which is why it’s so important to run compaction continuously without locking the table.
SQLake rewrites the data every minute, merging the updates/deletes into the original data. This process keeps the number of updates/deletes on the low side so the view queries run fast.
Meanwhile SQLake also deletes uncompacted files every 10 minutes, to save space and storage costs.
Critically, SQLake’s approach avoids the file-locking problem, so data availability is not compromised and query SLAs can always be met. SQLake’s ongoing compaction does not interfere with the continued ingestion of streaming data. Rather, the system continuously loads data into the original partition while simultaneously creating a discrete compacted partition. In addition, the metadata catalog is updated so the query engine knows to look at the compacted partition and not the original partition. There’s no locking on tables, partitions, or schema, and no stream interruption or pause; you maintain a consistent optimized query performance while always having access to the most current data.
Note Small file compaction is only one of many behind-the-scenes optimizations that SQLake performs to improve performance of queries, including partitioning, columnar storage, and file compression.
Benchmarking the Difference
Here’s a very simple but representative benchmark test using Amazon Athena to query 22 million records stored on S3.
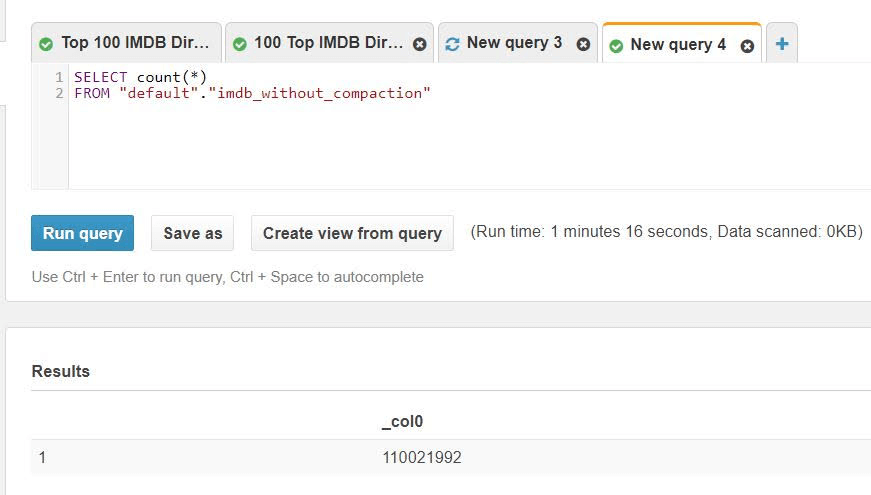
Running this query on the uncompacted dataset took 76 seconds.
Here’s the exact same query in Athena, running on a dataset that SQLake compacted:
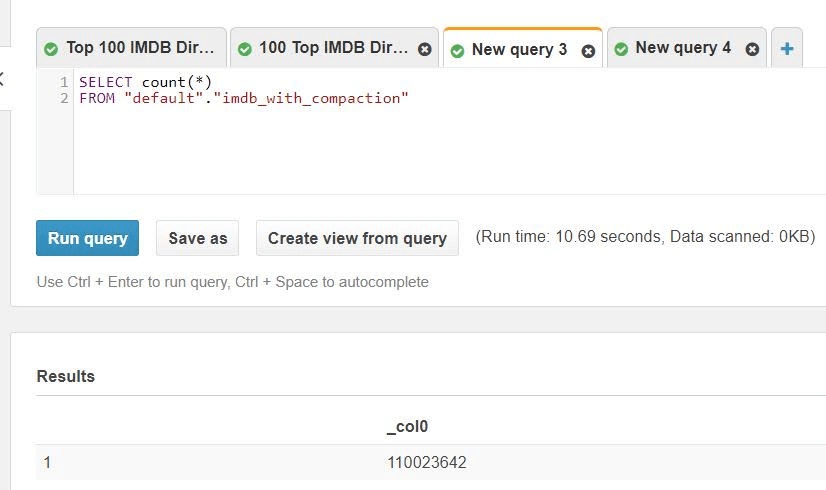
This query returned in 10 seconds – a 660% improvement.
You can also review more detailed Athena vs. BigQuery benchmarks with SQLake.
Dealing with Small Files – Correct and Incorrect, at a Glance
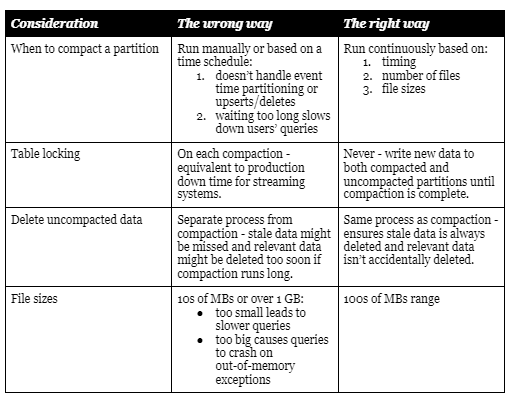
If you’re using SQLake, compaction is something you don’t need to worry about since it’s handled under the hood. Otherwise, you’ll need to write a script that compacts small files periodically – in which case, you should take care to:
- Define your compaction window wisely, depending on how Athena is set up. Compacting too often will be wasteful since files will still be pretty small and any performance improvement will be marginal; compacting too infrequently will result in long processing times and slower queries as the system waits for the compaction jobs to finish.
- Delete uncompacted fields to save space and storage costs (we do this every 10 minutes). Needless to say, you should always have a copy of the data in its original state for replay and event sourcing.
- Remember to reconfigure your Athena tables partitions once compaction is completed, so that it will read the compacted partition rather than the original files.
- Keep your file size as big as possible but still small enough to fit in-memory uncompressed. SQLake uses a 500 MB file size limit to stay within comfortable boundaries.
More Information
- There’s much more information about the Upsolver SQLake platform, including how it automates a full range of data best practices, real-world stories of successful implementation, and more, at www.upsolver.com.
- More details on how you can use Upsolver to improve Athena performance.
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
- Try SQLake for free for 30 days. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes