
Explore our expert-made templates & start with the right one for you.
CQRS, Event Sourcing Patterns and Database Architecture
-
 Upsolver Team
Upsolver Team
- Cloud Architecture
- February 17, 2022
Thinking about adopting streaming architecture patterns? Check out our Ultimate Guide to Streaming Data Architecture. Over 40 printed pages we cover technologies, best practices, reference architectures and a ton of practical advice about building and managing an effective data platform. Get your copy here
An event source pattern is an approach to a sequence of events. The system stores a history of the changes in data states and notifies a consumer to handle them. In event sourcing, you store the entire chain of data transformations – not just the latest state (or final result) of the data. CQRS – Command Query Responsibility Segregation – promotes separation of commands and queries – in practice, the read and write functions. In this article we describe each approach, illustrate how CQRS facilitates event sourcing, and help you determine whether and how to proceed with this architecture.
By the way, event sourcing is a core architectural tenet of Upsolver SQLake, our all-SQL data pipeline platform that lets you just “write a query and get a pipeline” for batch and streaming data . Using event sourcing, SQLake is able to automate everything else beyond writing the query, including orchestration and file system optimization. If you want to give it a try, you can execute sample pipeline templates, or start building your own, in Upsolver SQLake for free.
Event Sourcing – Explaining the Pattern
Event sourcing stores the state of a database object as a sequence of events – essentially a new event for each time the object changed state, from the beginning of the object’s existence. An event can be anything user-generated – a mouse click, a key press on a keyboard, and so on.
The system of record is a sequential log of all events that have occurred during a system’s lifetime.
Principles of an event sourcing pattern:
- The events are immutable.
- There can be as many events for the given entity as needed – that is, there is no limit on the number of events per object.
- Every event name represents the event’s meaning – for example, NewUserCreationEvent.
- To use the entity in the application (for example, to display the name of a user in the UI), you create a flat representation of the entity. Each subsequent use of the entity recalculates its current state via the sequence of state-changing events.
Benefits of an Event Sourcing Architecture
First, you can restore the data as it was at a certain point in time, just by the chain of transformation events beginning from a certain moment.
Next, you achieve greater fault tolerance; if there’s corruption or a failure you can recover the current state of data by applying an entire sequence of events to the affected entity.
You can also:
- Facilitate the R & D process. Quickly test multiple hypotheses to answer a business question. For example, you can build one pipeline to transform the event source, measure it, then create another pipeline and re-compute the current state of the data using the new sequence of events. Also, analysts and data scientists can derive useful insights not only from the final state of the data but also from the history of its transformations.
- Improve operational flexibility. If a bug causes a miscalculation, or omits a column, instead of doing time-intensive detective work you can simply rerun a pipeline from whatever point in time you need. You’re never in a situation in which you cannot fix the data. Also, each time you create a new use case you can simply create a pipeline that transforms the desired data from the append-only log and writes it to the targeted subscriber(s).
- Ensure compliance via full traceability. In a database it’s difficult to determine how data may have arrived at its current state. With event sourcing you can always retrace your steps.
- Support an open architecture. Create many different pipelines, with multiple databases subscribing; then use a best-of-breed approach to your data architecture.
- Reduce processing time. With an append-only log you can chunk data into small units and process it in parallel.
This model also works well with streaming data.
But there are challenges. For example, you need more processing power to recalculate the state of the entity each time. And storing information about all transformations may require more memory than storing just the last state of entities. You can, however, mitigate both issues with cheaper computing power and cloud storage.
CQRS Explained
CQRS promotes separation of commands and queries. In an application architecture using CQRS, you divide the application into two segments. One is intended for the update and delete – the writing model. With the other segment you do the read – the read model. There are two databases, rather than the one used in the traditional CRUD approach, and each side is optimized for quick and effective operation, whether reading or writing.
The whole application ostensibly works better with separate responsibilities for different parts of code and different elements of the system. For example, in a blog application there are significantly more queries that read data from the database than queries that write data into the database. CQRS helps you optimize the “write” part of the application.

How does CQRS work together with event sourcing? The part of the application that updates data then appends the event sequence. For example, in an Apache Kafka topic, the “write” segment of the application adds new events to the queue. Another segment of the application (called an event handler) is subscribed to the Kafka topic; it reads the events, transforms data accordingly, and writes the final state of the data into the “read” database. The “read” segment of the application (the part that accesses data) works directly with the “read” database. It fetches the current state of entities regardless of how this state was computed, as its main task is to accelerate read queries.
Understanding the CQRS Architecture
Let’s look at the schema that demonstrates how you can implement a CQRS architecture without event sourcing. The first diagram illustrates an example of CQRS architecture without event sourcing:
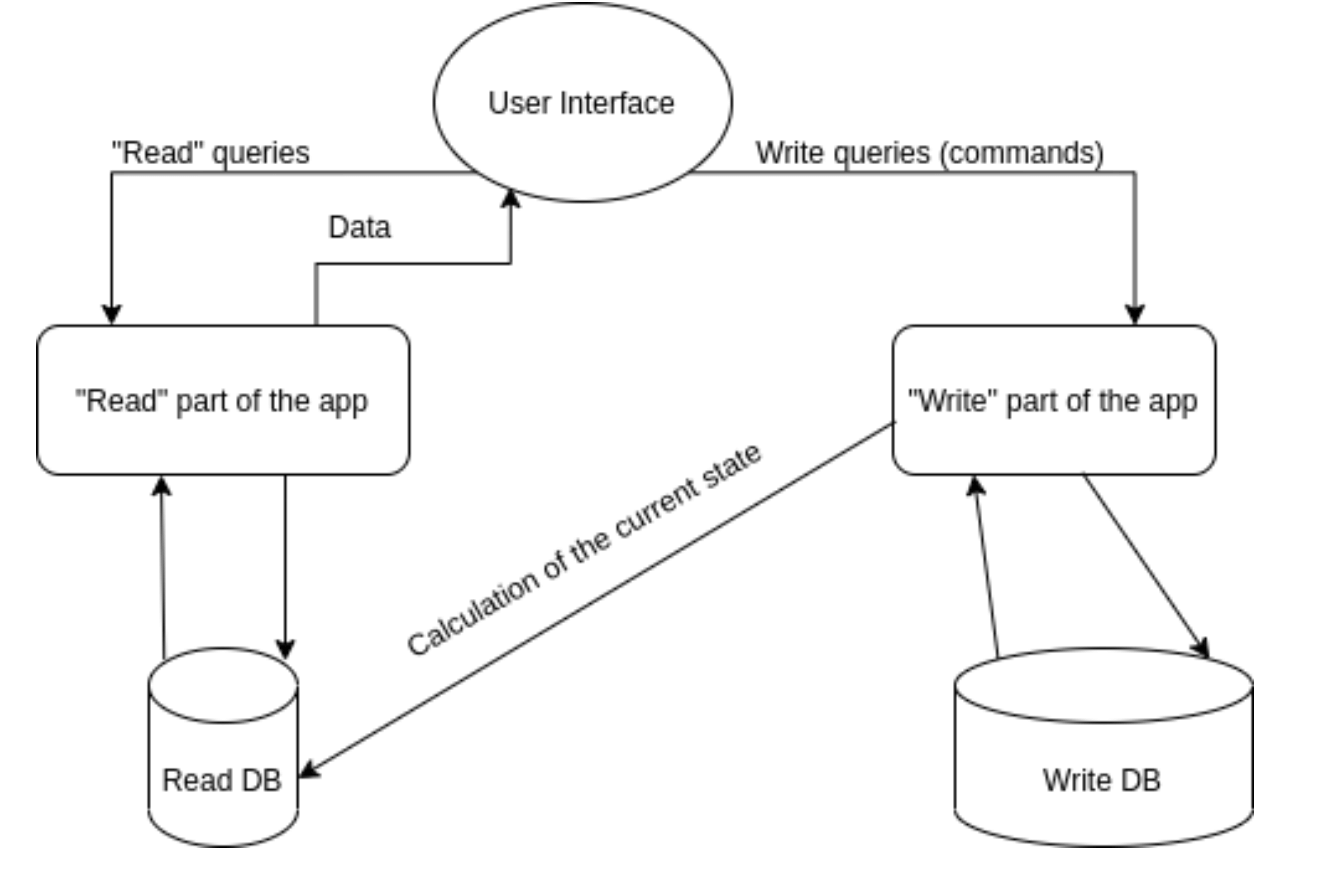
The user interface (UI) component issues commands to update data. The “write” part of the system processes these commands and saves data in the “write” database. This part simultaneously uses data from the “write” database to calculate the state of the data and write it in the “read” database. The UI then interacts with the “read” database to fetch needed data.
Now let’s illustrate how the schema changes when we use both CQRS and event sourcing.
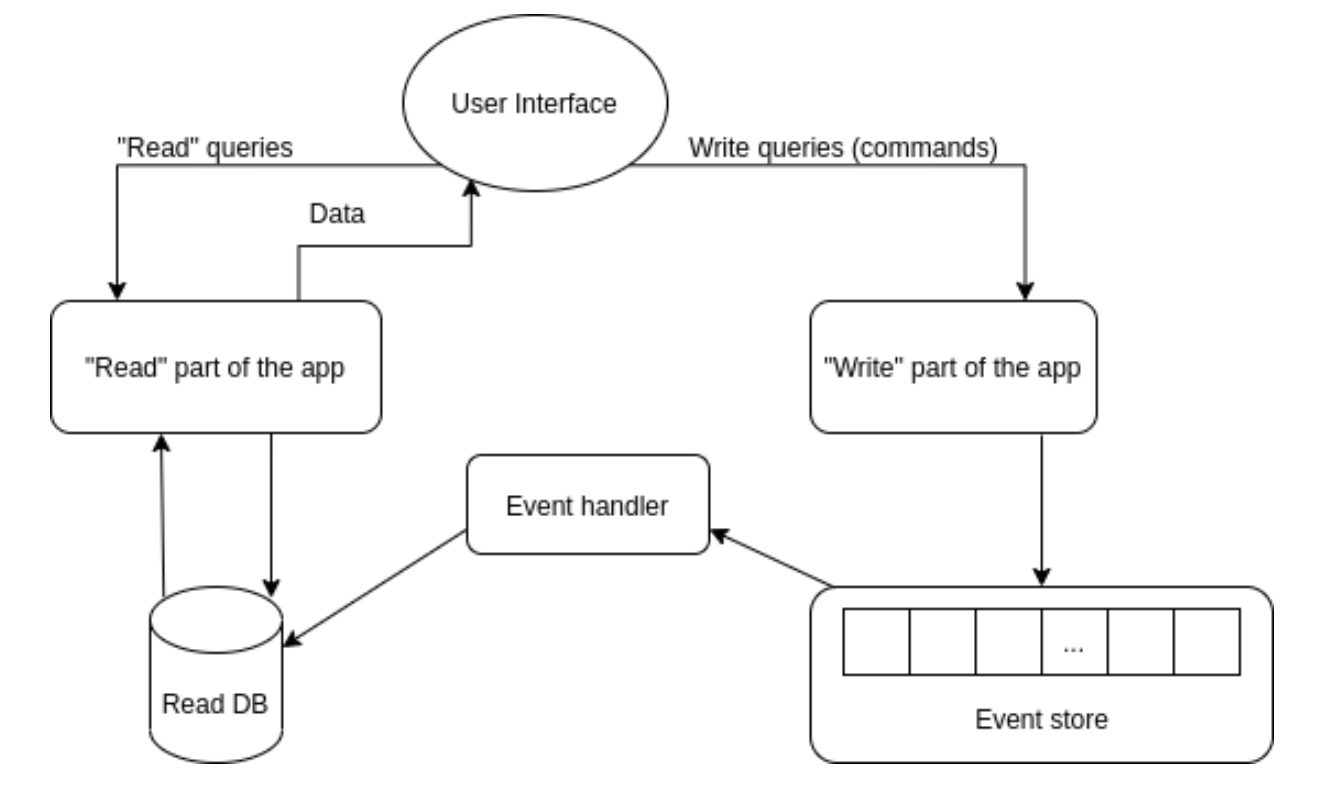
As shown, the “read” part remains unchanged. But the “write” database is now represented by the queue of events (the event store). The “write” segment of the application publishes events (commands) in the queue (a Kafka topic, for example). The event handler consumes events from the event store and updates data in the “read” database. The current states of the entities are stored only in the “read” database. You can extract the entire history of entity transformation using a sequence of the events stored in the “write” database. CQRS is implemented by a separation of responsibilities between commands and queries, and event sourcing is implemented by using the sequence of events to track changes in data.
Best Use Cases for CQRS Implementation
The CQRS approach (with event sourcing) may be appropriate when:
- The business logic of the system is complex. CQRS keeps logic of data changes apart from reading data. This means different components of the system can evolve in their own way, and be optimized as needed. This is akin to a microservices architecture. CQRS makes the system more flexible, ready for scaling and changes, and easier to maintain.
- Scalability is very important. One of the key benefits of CQRS is easier scalability; it’s easier to work individually with isolated components of the system without worrying about other components.
- Teams of developers are large and distributed. It’s more convenient to split work between teams when the elements of the system are loosely coupled. The most experienced developers can organize the work of the system as a whole; less skilled developers work on specific components.
- You want to test different data processing logic. This is especially true if the system has multiple components even without CQRS (for example, a monitoring tool, a search app, an analytics app, and so on). All these tools are consumers of data (or events).
- You built your production system in the traditional CRUD paradigm, but you have serious performance issues that are hard to solve without changing the architecture. Splitting the application into the “read” and “write” parts can help to improve performance. It enables you to focus on system bottlenecks and critical points of failure.
How Upsolver Facilitates Event Sourcing
Upsolver’s architecture follows event sourcing principles and is based on an immutable append-only log of all incoming events. To create this log, ingest raw data from a range of sources, including data lake storage (Amazon S3) and event streams (Kafka, Amazon Kinesis).
Then write declarative data pipelines, using only SQL. The pipelines read from the append-only log and write to the target of your choice – another data store (such as S3 or Snowflake), an analytics tool (such as Apache Presto or Amazon Athena), or other systems.
You can always “go back in time” and retrace your steps. For example you can:
- learn about the exact transformation applied on your raw data down to the event level
- fix a bug in your ETL and then run it using the immutable copy of your raw data
- test out multiple hypotheses
Further Reading
You can read some other articles we’ve written about cloud architecture as well as other streaming data topics, or check out our recent comprehensive guide: Data Pipeline Architecture: Building Blocks, Diagrams, and Patterns
Want to build or scale up your streaming architecture? Try Upsolver SQLake for free for 30 days. No credit card required.
SQLake is Upsolver’s newest offering. It’s a declarative data pipeline platform for streaming and batch data via an all-SQL experience. With SQLake, users can easily develop, test, and deploy pipelines that extract, transform, and load event data in the data lake and data warehouse in minutes instead of weeks. SQLake simplifies pipeline operations by automating tasks like job orchestration and scheduling, file system optimization, data retention, and the scaling of compute resources. SQLake makes building a pipeline as easy as writing a SQL query. Use it free for 30 days.
Learn more about SQLake. Also, we invite you to join our Slack community to continue the discussion and get answers to some of your questions. You can also schedule a demo to learn how to build your next-gen streaming data architecture, or watch the webinar to learn how it’s done.
Published in:
Blog
,
Cloud Architecture