
Explore our expert-made templates & start with the right one for you.
Orchestrating Streaming and Batch ETL for Machine Learning
-
 Eran Levy
Eran Levy
- Cloud Architecture
- August 20, 2019
This post is based on our recent webinar on Online Inference with User Personalization at Scale. Read on for the abridged version, or watch the full presentation by Upsolver CTO Yoni Eini here.
In a previous article we discussed some of the challenges of real-time machine learning and why so many projects seem to get stuck in the phase and never come to fruition. This time around we’ll take a more in-depth look at a particular use case, why it’s difficult to solve using traditional big data architectures, and how Upsolver can be used to orchestrate both batch and streaming ETL pipelines for machine learning.
When would we use user personalization in machine learning?
The use case we’re looking at is online inference using user personalization as a target. Basically, what we want to do is predict some interaction your users can have with your website or app.
Types of interactions we might want to predict could include:
- Product recommendations for ecommerce
- For advertising technology – serving the ad that the user is likely to engage with at the right time
- Identifying devices that are likely to be used for malicious user behavior
While the technology considerations are very similar for all of these situations (as well as others, such as predictive maintenance for IoT), for the purposes of this article we’ll focus on the online advertising example.
Breaking down the online advertising use case
In this scenario we have a real-time stream of events that represents the data we have about a user’s previous interactions with apps or advertisements. Each event arrives with a user ID and a campaign ID, which tells us which ad we showed to that user.
We’re trying to improve the monetary value we get from ads. To do that, we want to predict whether the user is going to click on an ad, because we want to show users ads they will engage with; or it can also go in the other direction – maybe there’s a user that always clicks on our ads, which could indicate fraudulent or bot traffic.
Anytime we get a chance to display the ad and our software needs to decide whether to do so, there are two types of information that can help us make that decision:
- Information that arrives in the event itself. For example, we might know the IP of the user which we can use to infer geo-location. We might have a user agent that tells us what browser the user is using, or whether it might be a bot.
- Historical data about the user. This could include, how many times have we seen this user in the past, in which domains, whether they’ve clicked on other ads, what their CTR (click-through rate) is, how other users from the same geo behave — all sorts of characteristics that examine not only this single event, but a group of data points over time.
It seems pretty obvious that if we’re able to take both of these types of information into account, we’re going to have more rich data and subsequently get better predictions. However, getting to that point is surprisingly difficult to do.
The dual ETL challenge
To make the data available for our decision engine, we’re going to need to ETL it – run an extract-transform-load process that turns the raw event data stored in our data lake into something that we can easily access and query.
The main problem here is that in most current big data architectures, we’re going to need to build that ETL flow twice, using both batch and stream processing:
- For model training, we need to convert raw data using Spark, for example, in order to build a dataset which we will use to train and create the machine learning model.
- For model deployment, to use our ML model in real-time, we’re going to have to build it out in our production environment, which is written in Java – and both of these systems have to return the exact same result. The models are very, very fickle about this point. If you don’t get the exact same result from your transformation between the offline and the online code, the model is simply not going to work.
Here is an example of the types of toolsets you need to orchestrate to get the data to the right place at the right time, and the problems you’ll need to solve when you’re building this dual ETL architecture:

NB: All of the above is just for basic transformation of real-time event data – before we’ve even started thinking about historical data!
In the batch ETL model training layer, you need to worry about processes such as exactly-once event processing, compaction, big data, storage, partitioning on S3 – all of which need to be done right if you want reasonable performance at reasonable cloud costs.
An examples of where this can get complicated is ordering. We need to store our events in the order they actually occurred to understand the actual clickthrough rate. It’s not enough to look at a day’s batch worth of data and say, okay, we had 20 interactions for this user and 3 clicks. that’s because that could skew our results if 17 of the impressions were in the early morning and the 3 clicks were in the late evening. Ignoring these types of discrepancies can cause our model to fail when we try to run it in real time.
For the streaming ETL, which is what we’ll use to actually make the online prediction, we need sub-second response time. We’ll need to pull historical data from a NoSQL database such as Redis or Cassandra. There are other considerations at play – probably the events that happened a few minutes ago are actually more pertinent to what the user is doing now than the events that happened last week, even though both might be important – so when we’re creating a historical profile of that user, we’ll need to take these things into account.
Putting it all together
What we end up with is a lot of moving parts to orchestrate between our training and production systems. All of these tools are built on arcane open-source frameworks that require highly specialized knowledge, and the result is a sprawling engineering project written in multiple programming languages. When we understand this, it becomes clear why machine learning and big data projects can take years of work and cost millions of dollars.
We’ll need to synchronize the event as it arrives with the historical data it would have had access to at that time. This is something that needs to happen automatically in real time because then they will have already occurred – but in the batch layer we are looking at data that doesn’t exist yet, so we need to work hard in order to make sure that that happens. Most key-value stores that are going to be used to store state simply don’t support this out of the box, so we’re going to need to build out something completely different in our batch layer. This is a major source of discrepancies.
When we’re building our training set, we have events that are going to be enriched with historical data, but we also want to know what’s going to happen. We do want to train the model to predict the actual clicks, but the click is going to happen, let’s say, 15 minutes after the event. This is something that we need to manage. We need to, on the one hand, not give the model historical data relative to the event for prediction, but we do still need to get some future data for the label. Then combining these things can be quite challenging.
Combining stream and batch processing with Upsolver Data Lake ETL
What can we do to actually make this better? One way is to hire a bunch of big data engineers to build these ETL pipelines over a prolonged period, and once you have that infrastructure in place – move on to the actual data science.
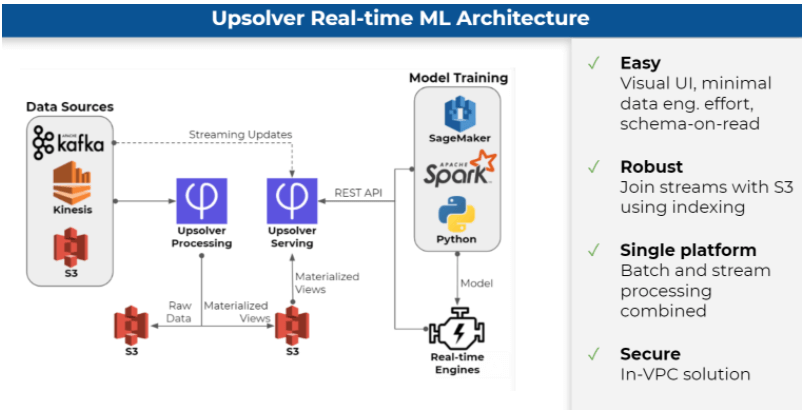
However, when we developed our data lake ETL platform, our idea was to make the process simpler and give data scientists more capabilities to work with event streams, while freeing up data engineering resources to develop features rather than maintain pipelines. One of the ways we do this is by combining both the offline batch ETL and the online streaming ETL into a single platform, which you can use without writing any code (except SQL).
In Upsolver we focus on the online portion – the entire platform is built on a streaming framework, so that the offline is just running the streaming framework faster. This eliminates all of the manual coding, removes the data plumbing and almost all of the DevOps work, and essentially gives the data scientist the ability to define their dataset using streaming production code.
Once you’ve built your dataset, there aren’t any additional steps – you’re ready to productionize it. You don’t need to synchronize it with anyone. You don’t need the big data engineer involved. This helps companies build their machine learning systems while avoiding the complexities we covered above altogether.
Want to learn more? Watch the webinar now for a live demo of building an end-to-end data science pipeline in Upsolver, read more about how Upsolver helps with machine learning on Amazon Web Services, or check out our comparison between data lake ETL and Delta Lake.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Cloud Architecture