
Explore our expert-made templates & start with the right one for you.
AWS Glue – Features, Components, Benefits & Limitations
-
 Upsolver Team
Upsolver Team
- Cloud Architecture
- October 21, 2020
Data integration and ETL tasks are a challenge for almost any data app or dashboard. Among the many tools and frameworks available, AWS Glue is a managed service offered by Amazon for large-scale data integration, usually in preparation for querying the data using another AWS-native service such as EMR.
Here is how Gitika Vijh, Sr. Solutions Architect at AWS, describes the role of Glue within a modern data architecture (taken from our recent webinar on streaming data pipelines):
In this article we’ll review how AWS Glue works, what are the key components you need to be aware of, use cases where it could be a good fit, and places where you’d be better off using another ETL tool.
AWS Glue Core Features
Here are the features that make AWS Glue useful:
AWS Glue Data Catalog
The AWS Glue Data catalog allows for the creation of efficient data queries and transformations. The data catalog is a store of metadata pertaining to data that you want to work with. It includes definitions of processes and data tables, automatically registers partitions, keeps a history of data schema changes, and stores other control information about the whole ETL environment. Data catalog is an indispensable component and thanks to the data catalog, AWS Glue can work as it does.
Automatic ETL Code Generation
One of the most notable features is automatic ETL code generation. The user can specify the source of data and its destination and AWS Glue will generate the code on Python or Scala for the entire ETL pipeline. Desired or necessary data transformations and/or enrichments will be handled by the generated code as well. The code is compatible with Apache Spark, which allows you to parallelize heavy workloads.
Automated Data Schema Recognition
AWS Glue is capable of automatically recognizing the schema for your data. To do this, it uses crawlers that parse the data and its sources or targets. It is convenient because users don’t need to design the schema for their data individually due to many complex features of the ETL processes and features of data sources and destinations.
Explore resources related to AWS Glue:
- On-demand webinar: How to Build & Manage Data Pipelines for Streaming Data on AWS
- Blog: Amazon Data Pipeline and Amazon Glue – Evaluating, Comparing, and Contrasting
- Blog: Approaches to Updates and Deletes (Upserts) in Data Lakes
- Blog: How to Build a Real-time Streaming ETL Pipeline
- Documentation: Connect Redshift Spectrum to Glue Data Catalog
Data Cleaning & Deduplication
Data cleaning and deduplication are important preprocessing steps prior to data analysis. AWS Glue uses machine learning algorithms to find duplicates of data. All users need to do is to label a small sample of data. The model will then be trained on the labelled sample and become ready to be included in the ETL job.
Endpoints for Developers
We have already pointed out the ability to generate code for ETL pipelines. Besides this, users can modify code according to their needs. Convenient endpoints are provided for developers that they can use to work with the code. It is also possible to create custom libraries and publish them on the AWS Glue GitHub repository to share with other developers.
Running Schedule for AWS Glue Jobs
You can set up the schedule for running AWS Glue jobs on a regular basis. Users can choose to trigger ETL transformations in response to certain events or on-demand. A job can restart if there are errors and write logs to Amazon CloudWatch since these services are integrated between each other.
Streaming Support
Working with data streams is a paradigm that is becoming more and more popular nowadays. AWS Glue supports a streaming approach as well. We have already mentioned that the job scheduler can be set up to trigger jobs when certain events occur. This means that each time the event occurs, the data is processed in the ETL pipeline. It resembles the streaming processing because events can be perceived in a stream. But besides this ability, it also works well with streaming data sources, for example, Apache Kafka or Amazon Kinesis. When working with such data sources, AWS Glue can ingest, process, enrich, and save data on-the-go. So, it is possible to set up, for example, the ETL pipeline from Apache Kafka to Amazon S3. Moreover, you can work simultaneously with multiple data sources, including streaming and batch.
Main Components of AWS Glue
Let’s briefly explore the most important components of the AWS Glue ecosystem.
We have already mentioned the AWS Glue data catalog. This is the component that stores metadata needed for the system to work efficiently. All necessary information about data, data sources, destinations, required transformations, queries, schemas, partitions, connections, etc. is stored in the data catalog. It is an indispensable element of the system.
Data Crawlers and Classifiers
How is the data catalog filled? This is the responsibility of data crawlers and classifiers. They explore data in different repositories and decide what the most suitable schema for the data is. Then the meta-information is saved into the data catalog.
AWS Glue Console
AWS Glue console is required to manage the system. Using the management console you can define jobs, connections, tables, etc., set up the scheduler, specify events for triggering jobs, edit scripts for transformation scenarios, search for objects, and so on. In turn, internal APIs endpoints are used to programmatically interact with the backend.
Job Scheduling System
The job scheduling system is a component that allows users to automate ETL pipelines by creating an execution schedule or event-based jobs triggering. It also allows chaining ETL pipelines.
AWS Glue ETL Operations
ETL Operations is an element of the system that is responsible for automatic ETL code generation on Python or Scala. This component also supports the customization of the generated code.
Look at the schema below to better understand how the components are related to each other.
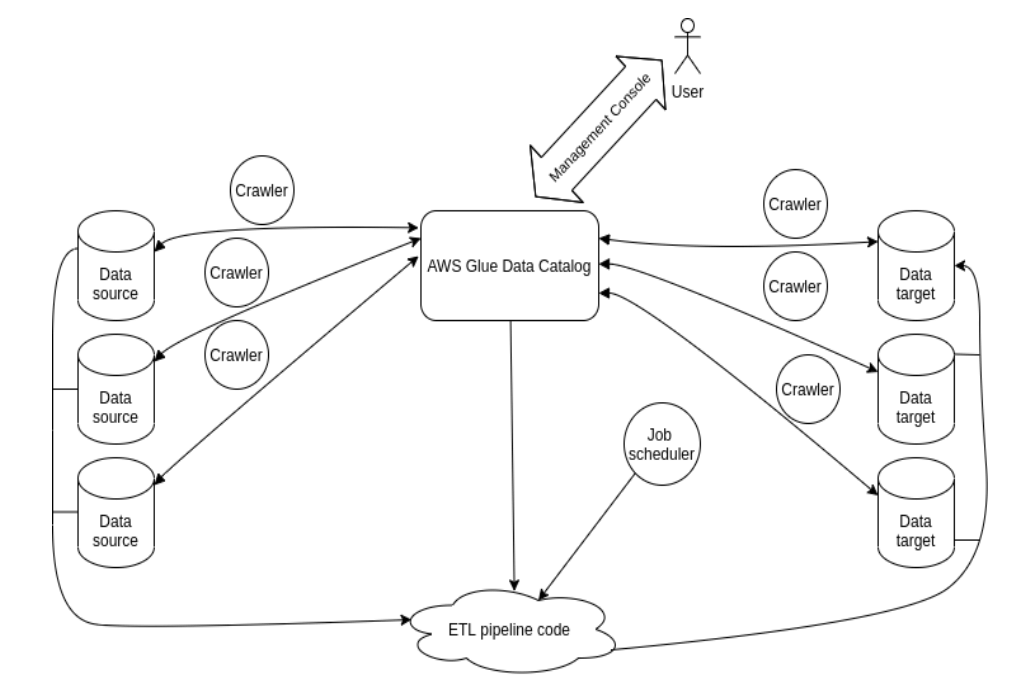
From the left side of the image, you can see data sources. Data crawlers analyze data sources and targets and extract necessary information about them. This metadata is stored in the data catalog. Users can interact with the system via the management console. Using metadata from the data catalog, code is generated for ETL pipeline. This code is responsible for all transformations of data all the way from data sources to data targets. The ETL job can be triggered by the job scheduler. Eventually, the ETL pipeline takes data from sources, transforms it as needed, and loads it into data destinations (targets). This is a bird’s-eye view of how AWS Glue works.
When to Use and When Not to Use AWS Glue
The three main benefits of using AWS Glue
- Orchestration. You don’t need to set up or maintain infrastructure for ETL task execution. Amazon takes care of all the lower-level details. AWS Glue also automates a lot of things. You can quickly determine the data schema, generate code, and start customizing it. AWS Glue simplifies logging, monitoring, alerting, and restarting in failure cases as well.
- Work well with other AWS tools. So, data sources and targets such as Amazon Kinesis, Amazon Redshift, Amazon S3, Amazon MSK are very easy to integrate with AWS Glue. Other popular data storages that can be deployed on Amazon EC2 instances are also compatible with it.
- Only pay for the resources you use. Glue can be cost effective because users only pay for the consumed resources. If your ETL jobs require more computing power from time to time but generally consume fewer resources, you don’t need to pay for the peak time resources outside of this time.
Limitations of using AWS Glue
- Reliance on Spark. AWS Glue runs jobs in Apache Spark. This means that the engineers who need to customize the generated ETL job must know Spark well. The code will be on Scala or Python, so, in addition to Spark knowledge, developers should have experience with those languages. This means that not all data practitioners will be able to tune generated ETL jobs for their specific needs.
- Spark is not very good at performing high cardinality joins. But they are needed for certain use cases, such as fraud detection, advertising, gaming, etc. There will need to perform additional actions to make such joins efficient. For example, implement an additional database to store temporary states. It makes ETL pipelines more complicated.
- Difficult to combine stream and batch. It’s possible to combine stream and batch processing in Glue, but it is not an easy task. AWS Glue requires stream and batch processes to be separate from each other. This means that the same code should be generated and fine-tuned twice. In addition, a developer should be sure that there are no contradictions between batch and stream processes. All listed above make combining stream and batch processing a complex thing in AWS Glue. This creates a limitation of its using for such cases.
- Limited to AWS ecosystem. While Glue is optimized for working with other AWS services, it lacks integrations to products outside the AWS ecosystem, which could limit your choices when building an open lake architceture.
Conclusion
In this article, we explored AWS Glue – a powerful cloud-based tool for working with ETL pipelines. The whole process of user interaction consists of just three main steps. First, you build the data catalog with the help of data crawlers. Then you generate the ETL code required for the data pipeline. Lastly, you create the schedule for ETL jobs. AWS Glue simplifies data extraction, transformations, and loading for Spark-fluent users.
Need better, self-service ETL for streaming data on Amazon S3? Check out Upsolver’s SQL pipeline platform.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Cloud Architecture