
Explore our expert-made templates & start with the right one for you.
Approaches to Updates and Deletes (Upserts) in Data Lakes
-
 Jerry Franklin
Jerry Franklin
- Data Lakes
- October 29, 2021
Upserts – updates and deletes of records – extend the capabilities of data lakes, and are essential in many business use cases.
Performing updates and deletes is a basic function in OLTP databases. These databases use row-level storage with built-in indices that make it easy to pinpoint a specific record for upserts.
Data lakes and data warehouses, however, store data in a columnar format without indices, which makes it harder to perform record-level upserts and especially streaming upserts.
That’s why updating or deleting data is surprisingly difficult to do in data lake storage. Finding the records to update or delete requires a full data scan. But scanning an entire data store for each upsert is expensive and time-consuming. It can strain IT resources and delay responses to change requests. In the meantime, data practitioners can’t get the consistent view of the data they’d come to expect from databases.
Common Use Cases for Data Lake Upserts (Updates and Deletes)
Updates and deletes are especially mission-critical in cases of:
- Change data capture (CDC) – CDC is a design pattern for database replication based on tracking and upserting changes instead of re-copying the full table anytime there is a change. CDC enables organizations to act in near real-time based on data in their operational databases without impacting the performance of those source databases.
- Responsive dashboards that run on dimension tables – The value of low-latency queries is self-evident. But it’s difficult to achieve if you have to perform a full data scan each time someone runs a query. Upserted data held in dimension tables eliminates the need for full data scans and makes fast queries on data at scale possible.
- GDPR/CCPA compliance – Security and privacy regulations such as these forbid companies from holding on to personally identifiable user data; they must be able to promptly locate and delete this data no matter the scale of the data lake in which it resides.
Alternatives for Facilitating Data Lake Upserts
The alternatives for facilitating upserts to data lakes vary according to the pipeline platform and the data lake table format you use. In this blog, we review the method of Spark pipelines into the Apache Hudi, Apache Iceberg, and Delta Lake file formats. We also review the method of Upsolver pipelines, which enable upserts on vanilla Apache Parquet files that are connected to the AWS Glue Catalog and to the Hive Metastore. We look at all these options in the context of three key areas:
- Compatibility with various data lake query engines
- Write performance with streaming updates
- Read performance
Compatibility with Data Lake Query Engines
It’s impactful to query and gain insight from the very latest data, even while the system continues without pause to process updates and deletes. Having access to data that’s one or more iterations old defeats the purpose of real-time analytics.
Delta Lake, Hudi, and Iceberg each has its own alternative catalog to the data lake standard Hive Metastore (or Glue Catalog on AWS). Those alternatives vary with regard to their compatibility with query engines. As of late 2021:
- Delta is natively supported by Spark and Databricks.
- Iceberg is natively supported by Trino, Starburst (managed Trino), and Dremio.
- Hudi is natively supported by PrestoDB, Impala, Hive, and AWS Athena.
It is possible to integrate their specialized table formats with the Hive Metastore and the AWS Glue Catalog for full query engine compatibility. But doing so requires an additional connector to sync the catalog. This creates a data freshness lag and risks inconsistencies. Also, for Delta Lake, the sync capability is limited to the commercial Databricks edition.
Write performance with streaming updates
For non-append-only use cases, there are 2 approaches for handling updates:
- copy-on-write
- merge-on-read
Copy-on-write (best for read-heavy workloads with infrequent updates) — Each time there is an update to a record, the file that contains the record is rewritten with the updated values. Commits occur only after updates are resolved; the copy operation is deferred until the first write. Writes may run much slower and even sometimes fail, due to lengthy operations that overload commits.
The biggest challenge with copy-on-write is write concurrency (there can only be one writer at a time) and write latency (a write can take hours, and locks the table to other writers). This is mitigated to some extent by allowing parallel writes that fail only if they touch the same files. But in the case of data compaction, it’s an operation that is likely both to be long running and to touch many files that in turn cause other writes to fail (or else it will fail continuously).
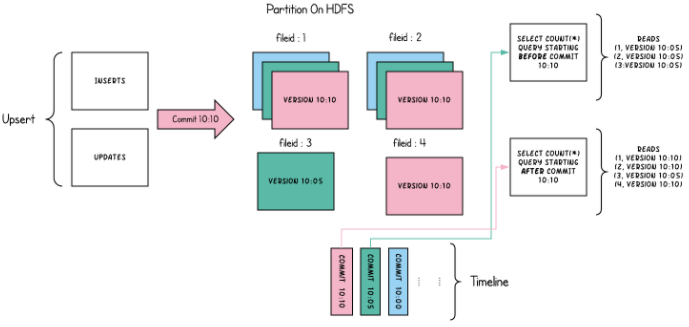
Source: Apache Software Foundation
Merge-on-read (best for write-heavy workloads with frequent updates) — Table updates are written immediately to a write-ahead log, and then upserts are resolved in query time by joining the latest table snapshot with the write-ahead log. This approach works well when the write-ahead log is small since a large scale join will destroy any chance for good query performance. That’s why merge-on-read is usually implemented with a background process (sort of compaction) that continuously commits the upserts in the write-ahead log. This approach is most suitable for streaming ingestion.
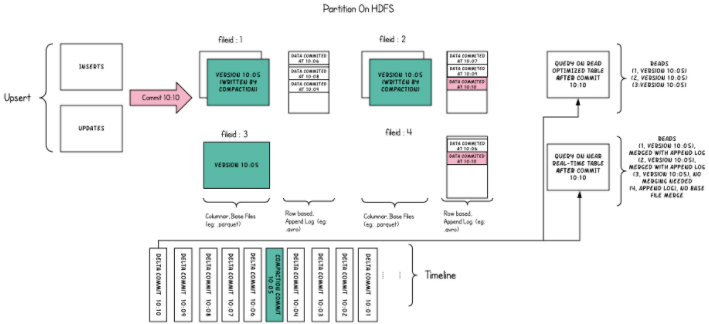
Source: Apache Software Foundation
- Delta Lake and Iceberg only offer support for copy-on-write. As a result, they may not be the best choice for write-heavy workloads.
- Hudi offers support for both merge-on-read and copy-on-write.
Read performance with streaming updates requires compaction
Formats using merge-on-read for writes are more likely to suffer from slow reads, since conflicts are addressed at query time instead of at write time. Therefore, a merge-on-read approach must also offer continuous compaction to keep the write-ahead log small. This doesn’t mean continuous compaction isn’t for formats using copy-on-write. Large datasets create a lot of files and compacting them can affect read performance by an order of magnitude.
- Delta Lake – optimized for reads using copy-on-write approach. Continuous compaction is available only in the commercial Databricks edition of Delta Lake, and it’s limited for tables up to 10 TB. The reason is that Databricks’ continuous compaction creates files of 128MB – 1/8th the 1GB size that’s widely considered preferable. The result is opening 8X more files, which can degrade query performance. So Databricks recommends the use of both continuous and manual compaction. Another important limitation to note is that compaction must run on reserved or on-demand instances, and these are as much as 10X more expensive compared to Spot instances.
- Hudi – a merge-on-read approach and continuous compaction to optimize reads.
- Iceberg – a copy-on-write approach optimized for reads. Compaction can be done manually.
Upsolver’s Approach to Upserts
Upsolver addresses the upserts challenge at the pipeline level, over vanilla Apache Parquet files connected to the broadly adopted Hive Metastore and AWS Glue Catalog. Under the hood, Upsolver commits upserts to a write-ahead log and leverages Hive Views to resolve inconsistencies at query time. Continuous compactions is a significant part of the solution. It’s used for both keeping the write-ahead log small and for optimizing Parquet file sizes.
Let’s review the key criteria for updates and deletes in Upsolver’s case:
- Compatibility: Today, Upsolver creates data lake tables by syncing Apache Parquet files to one or multiple Hive Metastores or AWS Glue Catalogs. That way, it’s possible to query the data from any query engine. Upsolver is planning to extend the catalogs it supports to formats such as Iceberg, which can potentially reduce query time using deeper statistics on columns.
- Write performance: Upsolver data pipelines support merge-on-read, which is best for streaming ingestion because it’s most suitable for upsert-heavy workloads.
- Read performance: Upsolver data pipelines support continuous compaction on Spot instances, generating compressed files of approximately 1 GB that maximize query performance by addressing the issue of small files.
Below is a table summarizing each platform’s characteristics:
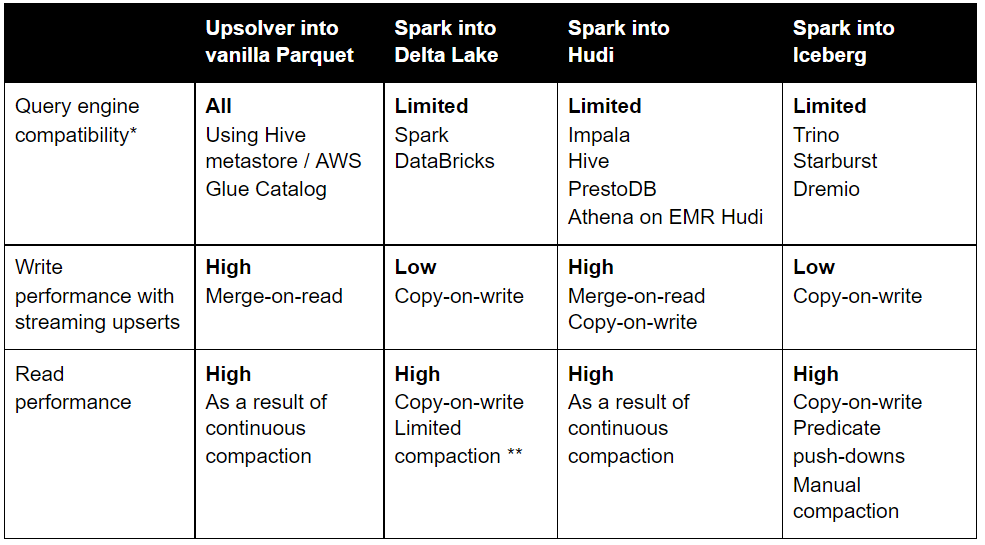
* No connector required to sync metadata between catalogs
** Continuous compaction exists but has numerous limitations that can degrade performance, such as no Z-ordered files; 128MB files instead of 1GB; and manual compaction recommended for tables larger than 10TB. (Z-ordered files are visually overlapping objects, such as windows in a Web application or objects in a drawing application. Z order determines the stacking order in which the objects display.)
Summary
Upserts – updates and deletes – keep data fresh and views consistent for working with data in a data lake. They’re challenging to implement, because the basic data lake model is append-only. But they’re crucial for a variety of use cases.
Methods for accomplishing upserts vary somewhat with specialized table formats by Apache Hudi, Apache Iceberg, and Delta Lake. Upsolver takes a different approach, addressing upserts at the data pipeline level, rather than the data lake table format. Evaluating these approaches on the basis of their query engine compatibility and write and read performance with streaming updates helps you ascertain which one might be most appropriate for your data infrastructure.
More Information
- Peruse the Upsolver Web site for much more information about the Upsolver platform, including how it automates a full range of data best practices, real-world stories of successful implementations, and more.
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo
- See for yourself how to do upserts and deletes in Upsolver.
- Try SQLake for free. SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes
