
Explore our expert-made templates & start with the right one for you.
Amazon Data Pipeline and Amazon Glue – Evaluating, Comparing, and Contrasting
-
 Jerry Franklin
Jerry Franklin
- Streaming Data
- April 26, 2022
Need inspiration for your next big data pipeline? Check out this recorded webinar to learn how Proofpoint built a big data pipeline for real-time network traffic (with 1 developer in 3 weeks), including the details of the real-time streaming architecture they built using Kinesis, S3, Athena, Upsolver and Elasticsearch. Watch now
There are many apps and services in the Amazon Web Services ecosystem, and often there’s overlap. Amazon Glue and Amazon Data Pipeline both primarily move data – so what’s the difference, and which do you use, when? We compare and contrast these two technologies, including providing tables for at-a-glance comparison.
If you want a faster solution to building data pipelines on an AWS data lake, consider Upsolver SQLake, our all-SQL data pipeline platform that lets you just “write a query and get a pipeline” for batch and streaming data . It automates everything else, including orchestration, file system optimization and infrastructure management. You can execute sample pipeline templates, or start building your own, in Upsolver SQLake for free.
What is AWS Data Pipeline?
Below we define and explain AWS Data Pipeline.
AWS Data Pipeline is intended to enable you to focus on generating insights from your data by making it simpler to provision pipelines and minimize the development and maintenance effort required to manage your daily data operations. It provides a managed data workflow service that offers flexibility in terms of the execution environment; access and control over the compute resources that run your code; and access and control over the data processing code.
Glossary terms mentioned in this post
- Amazon Kinesis – a service for processing data streams in real-time
- Data pipeline – a process for moving data between source and target systems.
- Data lake – an architectural design pattern in big data.
Using Data Pipeline, you define:
- the dependent processes to create your pipeline, comprised of the data nodes that contain your data
- the activities, or business logic, that will run sequentially, such as EMR jobs or SQL queries
- the schedule on which your business logic executes
AWS Data Pipeline runs on a highly reliable, fault-tolerant infrastructure. It manages the lifecycle of the EC2 instances on which it runs, launching and terminating them when a job operation is complete.
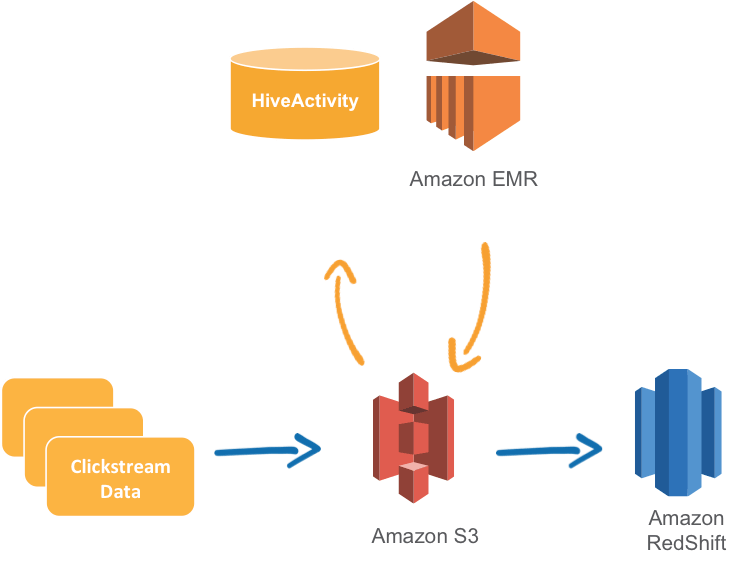
Here’s an example: To move clickstream data stored in Amazon S3 to Amazon Redshift, you would define:
- a pipeline with an S3DataNode that stores your log files
- a HiveActivity to convert your log files to a .csv file using an Amazon EMR cluster and store it back to S3
- a RedshiftCopyActivity to copy your data from S3 to Redshift
- a RedshiftDataNode to connect to your Redshift cluster.
You can then pick a schedule to run at the end of the day.
What is AWS Glue?
Below we define and explain AWS Glue.
AWS Glue consists of multiple discrete services that combined provide both visual and code-based interfaces to simplify the process of preparing and combining data for analytics, machine learning, and application development:
- The AWS Glue Data Catalog is a central metadata repository for quickly finding and accessing data.
- AWS Glue Studio provides data engineers with a visual UI for creating, scheduling, running, and monitoring ETL workflows. It handles dependency resolution, job monitoring, and retries.
- AWS Glue DataBrew enables data analysts and data scientists to visually enrich, clean, and normalize data without writing code.
- AWS Glue Elastic Views give application developers the ability to use familiar SQL to combine and replicate data across different data stores.
Upsolver is a data pipeline platform that replaces Glue Studio. It enables you to build pipelines using only SQL and automates pipeline orchestration, so that a SQL-savvy data practitioner can use Upsolver to quickly build and deploy an at-scale streaming-plus-batch data pipeline in their AWS account.
When do I Use AWS Glue, and When do I Use AWS Data Pipeline?
Below we compare common use cases for AWS Data Pipeline and AWS Glue.
There is considerable overlap between the two services. Both can:
- move and transform data across various components within the AWS cloud platform
- natively integrate with S3, DynamoDB, RDS, and Redshift
- assist with your organization’s ETL tasks
- deploy and manage long-running asynchronous tasks
Basically, Glue is more of a managed ETL service, and Data Pipeline is more of a managed workflow service. Glue handles your underlying compute resources, ostensibly freeing you up to focus on data properties, manipulation, and transformation and readying your data for querying. Data Pipeline provides a flexible execution environment and control over your compute resources, as well as control over the execution code.
Glue is serverless. Data Pipeline launches compute resources in your account, giving you access to Amazon EC2 instances or Amazon EMR clusters.
Perhaps the most pronounced difference is in the underlying technology. Glue is built upon Apache Spark, so its ETL jobs are Scala- or Python-based.
When should I go with AWS Glue?
Below we recommend when using AWS Glue makes the most business sense.
Use AWS Glue to discover properties of the data you own – structured and semi-structured – then transform it and prepare it for analysis. You get a unified view of your data via the Glue Data Catalog that is available for ETL, querying, and reporting, using services like Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum. Glue automatically generates Scala or Python code for your ETL jobs that you can further customize using tools with which you may already be familiar. You can use AWS Glue DataBrew for UI-based data preparation (light transformations) to visually clean up and normalize data without writing code. Use AWS Glue Elastic Views to combine and continuously replicate data across multiple data stores in near-real time.
Use Glue for:
- Running jobs on serverless Apache Spark-based platforms.
- Processing streaming (requires AWS Lambda), such as IoT event streams, clickstreams, and network logs.
- Designing complex ETL pipelines, including joining streams, and partitioning the output in Amazon S3 based on the data content.
- Enriching records with information from other streams and persistent data stores, then loading records into a data lake or warehouse.
When should I go with AWS Data Pipeline?
Below we recommend when using AWS Data Pipeline makes the most business sense.
Use AWS Data Pipeline to schedule and manage periodic data processing jobs on AWS systems. Data Pipeline can replace simple systems that may be managed by brittle, cron-based solutions. But you can also use it to build more complex, multi-stage data processing jobs.
Use Data Pipeline to:
- Move batch data between AWS components, such as:
- Loading AWS log data to Redshift
- Data loads and extracts (between RDS, Redshift, and S3)
- Replicating a database to S3
- DynamoDB backup and recovery
- Run ETL jobs that do not require the use of Apache Spark or that do require the use of multiple processing engines (Pig, Hive, and so on).
AWS Glue vs. AWS Data Pipeline at a Glance
Below we drill down and provide line-by-line comparisons of key aspects of AWS Data Pipeline and AWS Glue.
Below are tables that compare aspects of each application in 4 categories:
- Key features
- Supported data sources
- Data transformation
- Pricing
AWS Glue vs. AWS Data Pipeline – Key Features
Glue provides more of an end-to-end data pipeline coverage than Data Pipeline, which is focused predominantly on designing data workflow. Also, AWS is continuing to enhance Glue; development on Data Pipeline appears to be stalled.
| Feature | AWS Data Pipeline | AWS Glue |
| User interface | Drag-and-drop; Web-based management console; CLI | Visual and code-based |
| Batch/streaming | Batch | Batch and streaming |
| Scaling | Scalable to 106 files | Scales on demand. Serverless; use AWS Database Migration |
| Cloud-based / on-premises | AWS cloud or on-premises | Service to work with on-premises databases. |
| Template library | Yes, for specific use cases. | Yes, via AWS Cloud Formation. |
| Orchestration | Yes – scheduling, dependency tracking, error handling | Yes. Manages dependencies between jobs. Uses triggers either on a scheduler or job completion, or from an external source such as AWS Lambda function. You can also create a workflow manually or via AWS Glue Blueprint. |
| Indefinite retries | No | No – configurable up to 10 retries |
| Custom jobs | Supports custom pipelines | Supports custom jobs |
| Orchestration | No | Yes, via Glue DataBrew |
| CDC | No | Glue ElasticViews monitor for changes to data in your source data stores continuously; provides updates to your target data stores automatically. |
AWS Glue vs. AWS Data Pipeline – Supported Data Sources
Both systems support data throughout the AWS ecosystem. Glue provides broader coverage and greater flexibility for external sources.
| Feature | AWS Data Pipeline | AWS Glue |
Native integration / support | S3, DynamoDB, RDS, Redshift | Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum. Natively supports data stored in Amazon Aurora, Amazon RDS, Amazon Redshift, DynamoDB, Amazon S3. Natively supports JDBC-type data stores such as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in your Amazon Virtual Private Cloud, plus MongoDB client stores (MongoDB, Amazon DocumentDB). |
| Other integrations | Configurable to integrate with a wide variety of other data sources ranging from AWS Elastic File System to on-premises data sources to run Java-based tasks | Kafka, Amazon Managed Streaming for Apache Kafka (MSK), Amazon Kinesis Data Streams, Apache Flink, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda. |
AWS Glue vs. AWS Data Pipeline – Transformations
Again. Glue provides broader coverage, including out-of-the-box transformations and more ways to work with ancillary AWS services. However, it’s more complex to deploy and maintain.
| Feature | AWS Data Pipeline | AWS Glue |
Built-in transformations | No | 16 built-in transformations (Join, Map, SplitRows, for example). AWS Glue DataBrew includes more than 250 prebuilt transformations to automate data preparation tasks, such as filtering anomalies, standardizing formats, and correcting invalid values Also, predefined scripts for common data transformation tasks, which simplifies the overall process to build and run a job. |
| Other built-in activities | Some, including copying data between Amazon S3 and Amazon RDS, or running a query against Amazon S3 log data. | Developers can also bring their own scripts if they need flexibility outside of the prebuilt options. |
Complex transformation handling | Supports a variety of complex expressions and functions within manually-coded pipeline definitions; pipelines can contain up to 100 objects. (AWS offers support for more.) | Integrates with AWS Step Functions to coordinate serverless workflows across multiple AWS technologies. |
| Configurable transformation parameters | Yes | You can edit transformation scripts via the AWS Glue Console. |
| Transformation workflow | Automatically schedules, assigns, and (if necessary) re-assigns transformation activities. Task runners perform the transformation activities (plus the Extract and the Load) according to your defined schedule. | Build workflows via AWS Step Functions. Also, you can create a workflow from an AWS Glue blueprint, or you can manually build a workflow one component at a time using the AWS Management Console or the AWS Glue API. |
| Libraries included | No. Use an AWS SDK to interact with AWS Data Pipeline or to implement a custom Task Runner. | Includes libraries; enables custom code development. You can also write custom Scala or Python code and import custom libraries and Jar files into your AWS Glue ETL jobs to access data sources not natively supported by AWS Glue. |
| Transformation output | Outputs results to data nodes for storage and further access | Streaming ETL jobs support JSON, CSV, Parquet, ORC, Avro, and Grok. For writing Apache Parquet, AWS Glue ETL supports writing to a governed table by specifying an option for a custom Parquet writer type optimized for Dynamic Frames. |
AWS Glue vs. AWS Data Pipeline – Pricing
There are many more variations on pricing for AWS Glue than there are for Data Pipeline, due in part to the former’s multiple components. For more information, please see the AWS Glue pricing page and the AWS Data Pipeline pricing page.
| Feature | AWS Data Pipeline | AWS Glue |
| Upfront investment | None | None |
| Basic charges | Billed based on how often your activities and preconditions are scheduled to run and where they run (AWS or on-premises). | Hourly rate, billed by the second, for crawlers (discovering data) and ETL jobs (processing and loading data). |
| Minimums | None; no charge for no activity | 10-minute minimum duration for each crawl, though you can avoid Crawlers and instead populate the AWS Glue Data Catalog directly through the API. Spark jobs using Glue version 2.0 have a 1-minute minimum billing duration. Spark jobs using Glue version 0.9 or 1.0 have a 10-minute minimum billing duration. Minimum 2 Data Processing Units (DPUs), hourly rate billed by the second, both for Spark jobs run in AWS Glue and for Glue development endpoints. |
| Other | High-frequency (> 1/day) activities or pre-conditions and low-frequency activities or pre-conditions (<= 1/day) both charge flat monthly fee per activity, varying based on frequency and whether they’re run on AWS or on-premises. Inactive pipelines also charged monthly flat fee. | Glue Data Catalog: monthly fee for storing and accessing the metadata (first million objects and accesses are free). DataBrew: billed per interactive session and per minute per job Glue ElasticViews: charges based on resources used (compute, memory, network, and I/O). |
Upsolver SQLake and the AWS Ecosystem
SQLake is Upsolver’s newest offering. SQLake is a declarative data pipeline platform for streaming and batch data. With SQLake you can easily develop, test, and deploy pipelines that extract, transform, and load data in the data lake and data warehouse in minutes instead of weeks. SQLake simplifies pipeline operations by automating tasks like job orchestration and scheduling, file system optimization, data retention, and the scaling of compute resources.
AWS and Upsolver partner to provide an integrated solution that simplifies data pipelines for every data engineer. SQLake integrates with many AWS Services including S3, Athena, Kinesis, Redshift Spectrum, Managed Kafka Service, and more. Upsolver also is the only AWS-recommended partner for Amazon Athena as it substantially accelerates query performance.
You can:
- Lower the barrier to entry by developing pipelines and transformations using only familiar SQL.
- Improve reusability and reliability by managing pipelines as code – pipelines are versioned and testable with best practices applied automatically.
- Integrate pipeline development, testing, and deployment with existing CI/CD tools using a CLI.
- Eliminate complex scheduling and orchestration with always-on, automated data pipelines.
Try SQLake for free for 30 days. No credit card required. Build your first pipeline today using SQL with our pre-built templates.
Visit SQLake Builders Hub, where you can consult an assortment of how-to guides, technical blogs, and product documentation.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
More Information on AWS Data Architecture
- How to connect Upsolver to the Glue Data Catalog.
- Essential resources around building, maintaining, and managing an AWS Data Lake.
Published in:
Blog
,
Streaming Data
