
Explore our expert-made templates & start with the right one for you.
Airbyte vs Fivetran vs Upsolver – Which is the Best CDC Tool?
-
 Upsolver Team
Upsolver Team
- Building Data Pipelines
- June 19, 2023
As you explore the vast selection of CDC tools, first get a firm grasp on the underlying techniques. We encourage you to read our comprehensive technical paper “5 CDC Techniques for Real-Time Data Warehousing in Cloud Environment,” which offers a deep-dive into critical CDC methods and implementation strategies. Armed with this knowledge, you’ll be better equipped to make an informed choice on the CDC tool that best suits your requirements.
The market for change data capture, and data movement in general, is highly competitive. Dozens of solutions are vying for the chance to extract, transform, and load your data (not necessarily in that order). This creates a highly noisy ecosystem and makes determining which product best fits your needs difficult.
Below we look specifically at change data capture use cases, and see how Fivetran and Airbyte compare to one another, and to Upsolver. We’ve tried to focus on the big picture rather than the feature-by-feature breakdown. Hopefully, this will help you get your bearings and understand the core concepts behind each platform, and to continue your research and evaluation from there.
Fivetran: General-Purpose, ELT, Premium Price Point
Fivetran is a popular data movement and ELT tool that supports hundreds of sources and around a dozen destinations. The most popular use case for Fivetran is to write data from applications (e.g. salesforce.com, Google Analytics) and online marketing sources (e.g. Facebook Ads) into Snowflake or Google BigQuery. Transformations are performed in the data warehouse via FIvetran’s integration with open source dbt Core.
Fivetran has offered ‘homegrown’ database change data capture features for a while, but entered the market more loudly in 2021 with its acquisition of HVR, a dedicated CDC software vendor. However, despite announcements seeming to imply the opposite, HVR has not yet been integrated into the Fivetran interface and requires separate configuration, including installing an agent on the source database and software in your cloud account. So Fivetran HVR can be thought of as a separate application / engine from Fivetran proper.
There are advantages to using Fivetran / HVR. Since this is an article about CDC, we’ll focus on the HVR part of Fivetran. It has a breadth of connectors, from Oracle to SQL Server to MongoDB It is one of the longer-term players in the CDC business, having been founded in XXX. HVR can run on-premises or in AWS or Azure clouds. There may be some advantages to having support and contracting for APIs and databases centralized in a single relationship. Also, Fivetran is a vendor with a large number of customers and substantial funding, though a great deal of that was used to buy HVR.
Potential concerns with Fivetran CDC
Costs can rack up.
Unlike Fivetran proper, HVR is not a cloud-native SaaS offering; it needs to be manually installed into your cloud account, including provisioning resources and an underlying database. It also needs to be actively managed in terms of scaling resources, updating software and the like.
Again, there is little technical integration advantage. Even though you are working with one company, the database and API products have separate technical foundations and thus you cannot infer that a high quality aspect of one product will be reflected in the other.
Maybe the most important downside is that Fivetran’s pricing is based on ‘monthly active rows’, which includes the rows that Fivetran queries for historical data syncs, even if the data hasn’t changed. This is fine for workloads using data from SaaS applications which tends to be smaller volumes, For organizations replicating high volumes of data from an operational database, this can quickly become expensive.For examples, as of the time of writing, replicating 70M ‘active’ rows per month would put your annual bill at $91,757.88 if you’re on Fivetran’s standard plan.
ELT means you’re also paying for data warehouse compute.
Fivetran’s extract and load functionality is not the only cost factor. As mentioned, Fivetran is an EL tool for as part of an ELT architecture, where it handles the E and L, and the T is eventually performed in a cloud data warehouse – typically one of the more expensive compute layers you can choose. If you’re going to perform transformations such as aggregations and joins, you need to factor in significant costs on top of your ingestion costs.
Connector king; streaming data not so much.
Fivetran’s calling card is its wide array of connectors (344 at the time of this writing). This variety is useful for companies ingesting many 3rd party services. In these cases Fivetran helps to automate brittle API connections that would otherwise need to be maintained in-house. However, the focus of the company isn’t on streaming and real time use cases, which present their own set of challenges – mostly around low-latency, data quality and data consistency.
If you have data that falls into the ‘streaming’ category, you might find that you need a tool purpose-built for that challenge, backed by a company that’s more familiar with the data engineering problems relevant to that space.
Airbyte / Debezium: Open Source… But Still All-Purpose ELT
Airbyte is an open-source alternative to Fivetran. It positions itself as a universal data pipeline platform, and also sports hundreds of connectors. However, while Fivetran is a fully managed and closed-source service, Airbyte is open-source – you can download and install Airbyte in your cloud infrastructure without any commercial contract. Alternatively, you can subscribe to Airbyte Cloud, a service hosted and managed by Airbyte (the company).
Airbyte has no CDC connectors in the open source project; Airbyte Cloud supports log-based CDC by running Debezium as an embedded library under the hood. Debezium is a separate open-source distributed platform for change data capture that is specifically designed to monitor databases for changes and propagate those changes to downstream consumers.
Airbyte claims that they are less expensive than “other row-based ELT tools” by which we assume they are referring to Fivetran, but their pricing is opaque, using a credit-based currency as do many data services. According to their cost calculator they seem to charge $120/GB at 50 GB/month, and claim that this is roughly 70% less than other tools.
Airbyte / Debezium is great if you need the source code control and flexibility (build your own connectors) of an open source solution, or simply want to pay less than Fivetran charges for a managed SaaS solution. Keep in mind that while Airbyte claims 3,000 customers, the large majority of these are probably open source downloads, which does not necessarily indicate production use cases. As with any open source tool, there is a trade off involved, and you’ll need to dedicate technical resources to building and maintaining the solution plus managing scale, resilience, and security.
Potential concerns With Airbyte CDC
Community vs. Commercial.
Much like Fivetran, Airbyte is a general-purpose data movement tool with 300+ supported connectors. Because it is open source it provides the ability to build custom connectors. While it has an open source community behind it, the core business problem these tools are built to solve is automating API connectivity. Dealing with high-volume, low-latency streaming ingestion might not be the key area of focus for the team behind Airbyte.
ELT approach can increase costs.
In this sense as well, Airbyte has the same limitation as Fivetran. It does not offer a cost-effective way to transform data, and relies exclusively on the compute engine of its destination warehouse. There is nothing inherently wrong with this, but you need to be aware that this has the potential to increase your overall cloud costs to an extent that dwarfs whatever you are saving on the ingestion side.
Potential scale issues.
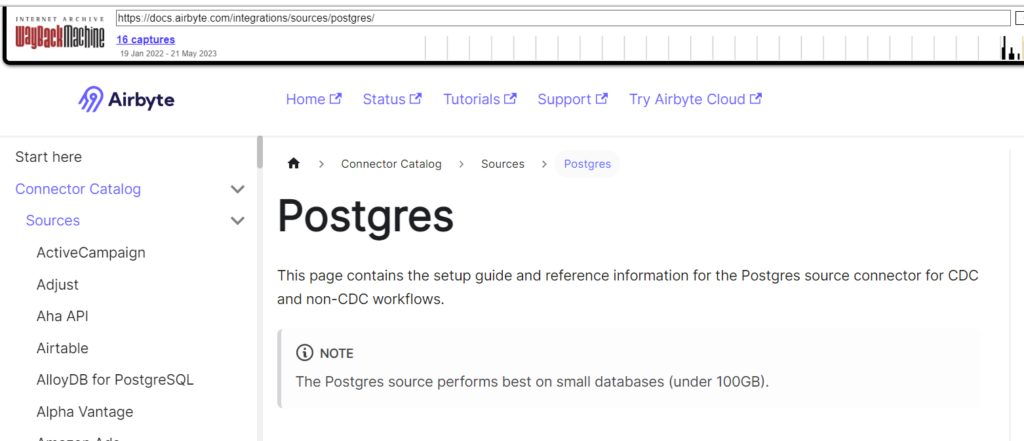
In online discussions on platforms such as Reddit, many users have expressed concerns about Airbyte’s stability in production environments, especially at larger scales. Users have reported issues with Airbyte’s ability to handle large volumes of data, leading to performance degradation. In the context of Postgres CDC, Airbyte’s own documentation used to mention that ‘the Postgres source performs best on small databases (under 100GB)’, although that comment has since been deleted.
Upsolver: Streaming-First Data Ingestion and Transformation
Upsolver is a data ingestion platform purpose-built for big data and streaming data, including database events delivered as CDC streams. Its architecture was designed to overcome the data quality challenges posed by these data types n. Similarly to Airbyte, Upsolver’s CDC relies on open-source Debezium under the hood.
Upsolver keeps your architecture open.
You can use Upsolver to ingest data into data warehouses such as Snowflake or Redshift, or to write analytics-ready files to Amazon S3 with corresponding virtual tables in Hive (Iceberg coming soon). The data you’ve ingested lives on S3 in open file formats and you can access them at any time, with or without Upsolver. This gives you the flexibility to work with data using any tool or architecture – data lake, data warehouse, or anything in between. You can optimize performance and costs by distributing workloads between query engines, rather than going ‘all in’ on a single database vendor.
Upsolver uses efficient compute to reduce transformation costs.
While just ELTing everything sounds attractively simple, it can cause your cloud costs to explode. Upsolver runs a proprietary data engine on EC2 instances, leveraging highly efficient compute on EC2 and dirt-cheap object storage on S3. You can use regular SQL to run large-scale transformations on streaming or batch data, without the complexities of managing Spark jobs, and at a much more attractive price point.
Focus on big data ingestion.
Unlike Airbyte and Fivetran, who try to be everything for everyone, Upsolver is very much focused on ‘big data’ sources: Kafka streams, application and server logs, and database CDC. We have developed a set of technologies and methods to tackle the specific data quality issues associated with these sources – exactly-once event processing, schema drift, small files – and our team solves these issues for customers every single day.
All three tools have free trials – try them for yourself
We’re obviously not going to be the most objective people to ask about which of these tools you should choose. Luckily, all three tools now have very straightforward free trial versions available. We’ve included the links below – go ahead and try them for yourself. (If you’d prefer to talk to our solution architects, you can do that here.)
>> 30 day free trial of Upsolver
>> 14 day trial of Airbyte Cloud
Published in:
Blog
,
Building Data Pipelines