Explore our expert-made templates & start with the right one for you.
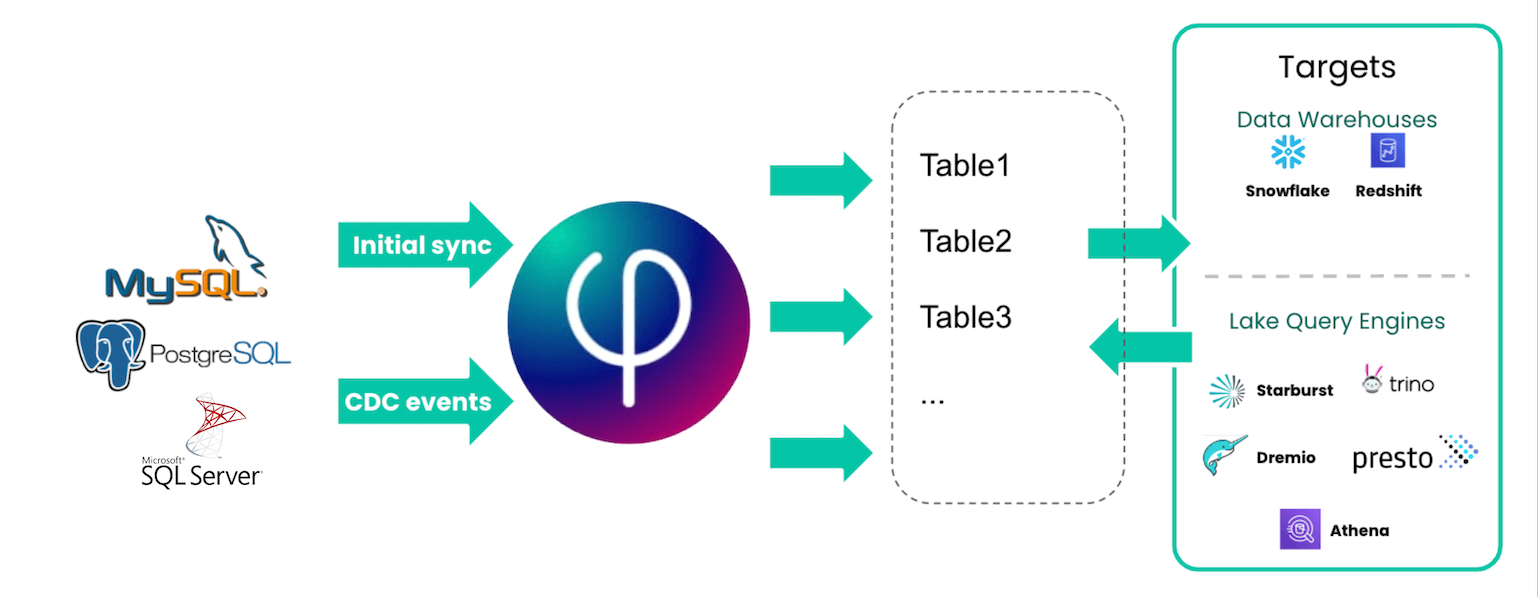
Replicate Databases with CDC
Deliver Live Tables to Multiple Destinations
Make Operational Data Available for Analytics
Businesses need to make information in relational databases broadly available for analysis, data science, BI and ML, without impacting the performance of the source database with resource-consuming queries.
The best practice for doing this is change data capture (CDC), which transmits change events based on database log activity. Upsolver creates and maintains a live database replica in your data lake or data warehouse. You can then access live operational data, with minimal impact on the source database. And you can cleanse and transform the data as you ingest it – mask, normalize, join, aggregate and more.
Make Operational Data Available to Everyone
SQLake replicates your MySQL, Postgres or SQL Server database to your data lake and data warehouse. It performs transformations and outputs live tables to Snowflake, Redshift, query engines such as Athena or Redshift Spectrum, or search engines such as Elasticsearch.
Based on Debezium, but Simpler and More Powerful
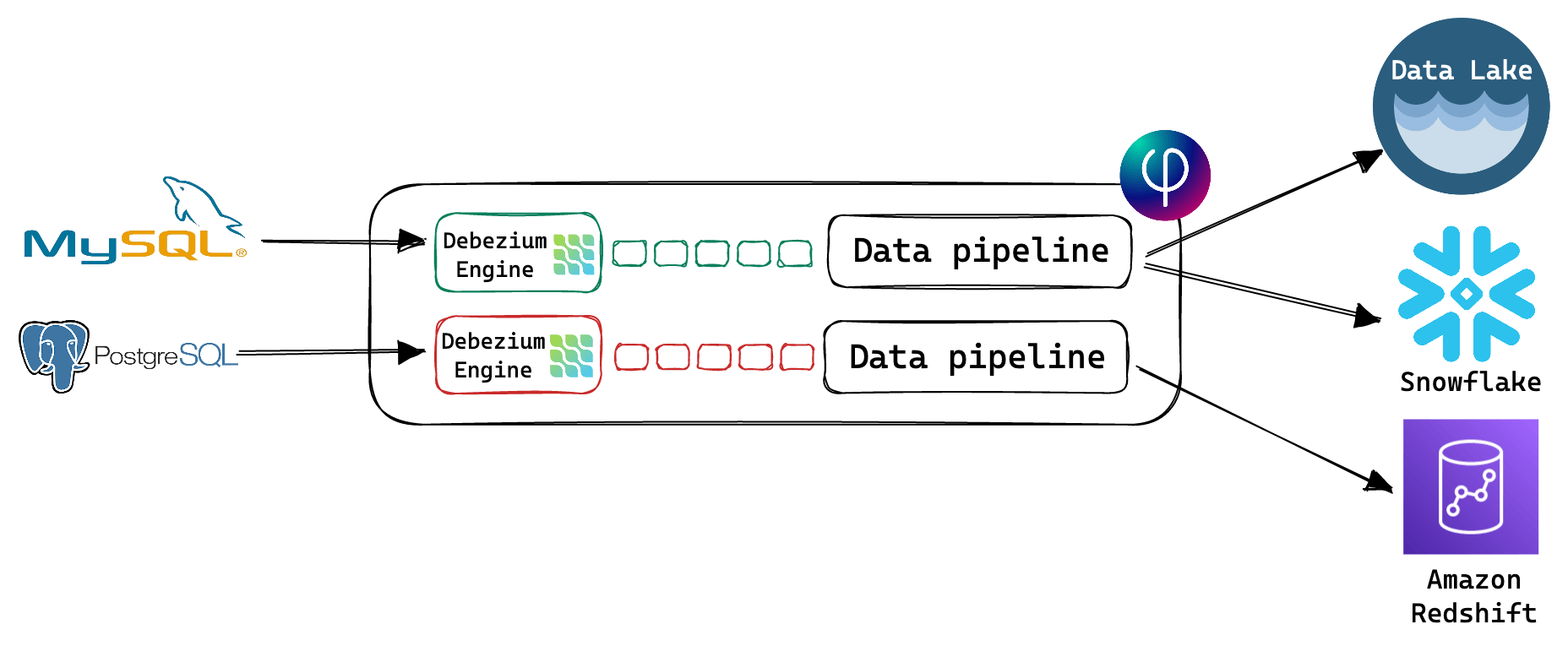
Upsolver’s CDC solution for database replication provides simplicity, data freshness, reliability and cost-effectiveness. It is based on the popular Debezium Engine, but unlike the open source solution, doesn’t require Kafka Connect and a Kafka cluster.
Upsolver stores the initial database snapshot plus raw change events in Amazon S3 as an immutable log, which allows for easy time travel and reprocessing of past data.
CDC support will be expanded to other popular databases such as Oracle Database, Microsoft SQL Server, IBM DB2 and MongoDB in the near future.
Real-Time Transformations - Cleanse, Blend, Aggregate +
Unlike most CDC systems, which focus solely on moving data, Upsolver is a scalable, stateful processing engine that allows you to transform the data in-flow. Some examples of its power include:
- Join CDC event data with streams and tables from other sources
- Enhance and aggregate events, continuously materializing real-time results
- Mask and redact sensitive information
- Track and correlate events using a dynamic session across an adjustable time window
- Time travel and reprocess data from a previous state without impacting the source database
Unlike previous generations of agent- or appliance-based CDC solutions, Upsolver is a cloud-native service that runs in your AWS VPC. Your data never leaves your control, and installation takes only a few minutes.
Upsolver pricing is simple. Start with a free fully-featured 30-day trial. Then stay on board for as little as $99 / TB ingested.
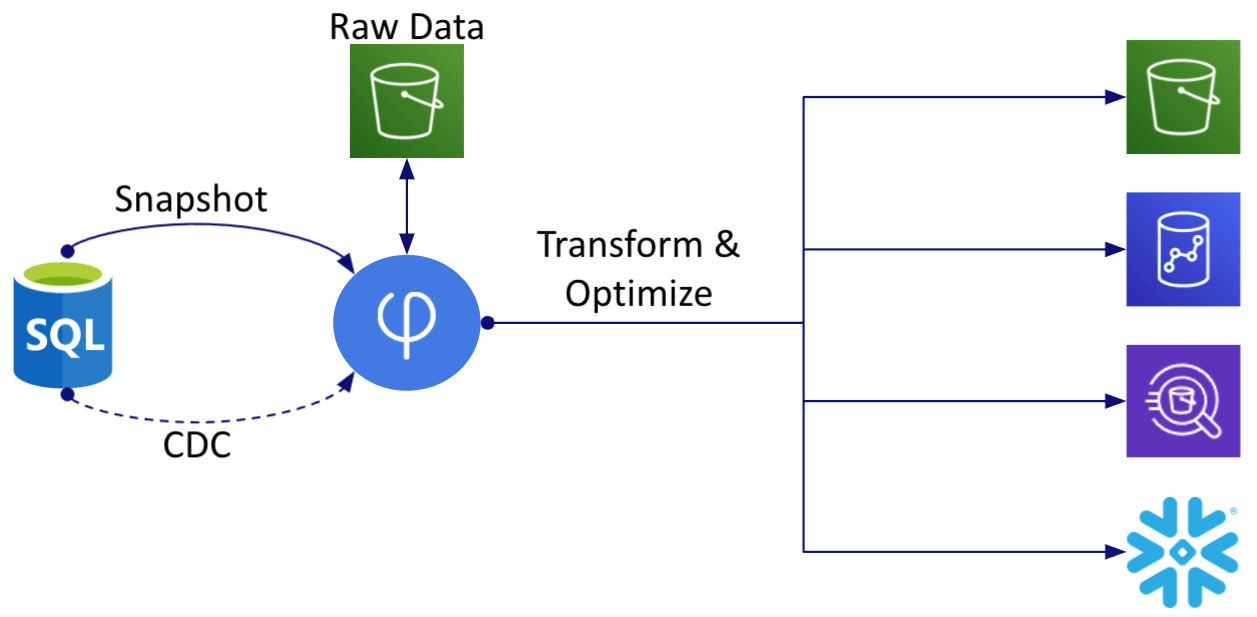
4 Simple Steps to Create a Live Replica
To build a CDC pipeline, you use the Upsolver IDE or CLI to
1) Connect to your source database,
2) Snapshot your database and then ingest change events,
3) Transform (e.g. cleanse, filter, aggregate, enrich, join) the data, and
4) Output live tables (merging changed rows) to one or more destination system.

Check out these additional resources

Webinar | Change Data Capture (CDC) for your Data Lake and Warehouse
Upsolver SQLake Demo | Change Data Capture
See how easy it is to continuously stream change logs for database replication from relational databases.
Guide to Change Data Capture (CDC) in 2023 – Pipelines, Challenges, Examples
What is change data capture (CDC)? Change data capture is a data integration capability available…
Implementing CDC: 3 Approaches to Database Replication
Learn how to create query-able tables from your operational databases with Change Data Capture (CDC)…
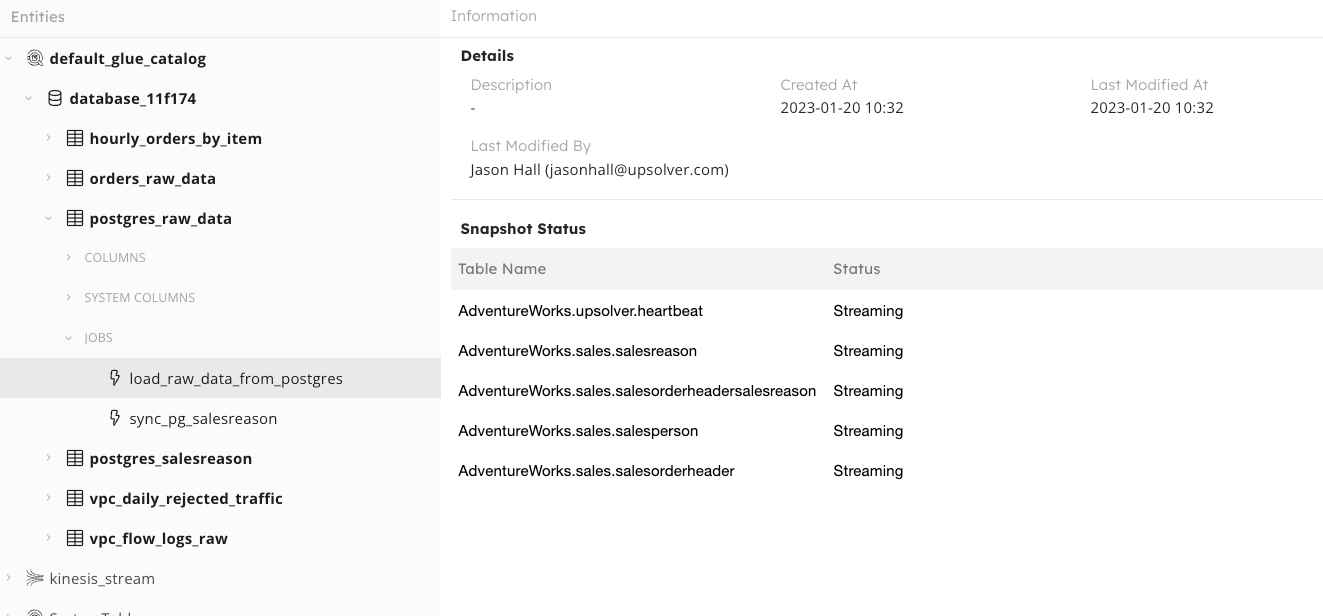
4 steps to Postgres CDC – replicate Postgres changes to your data lake
Change data capture (CDC) enables you to replicate changes from transactional databases to your data…
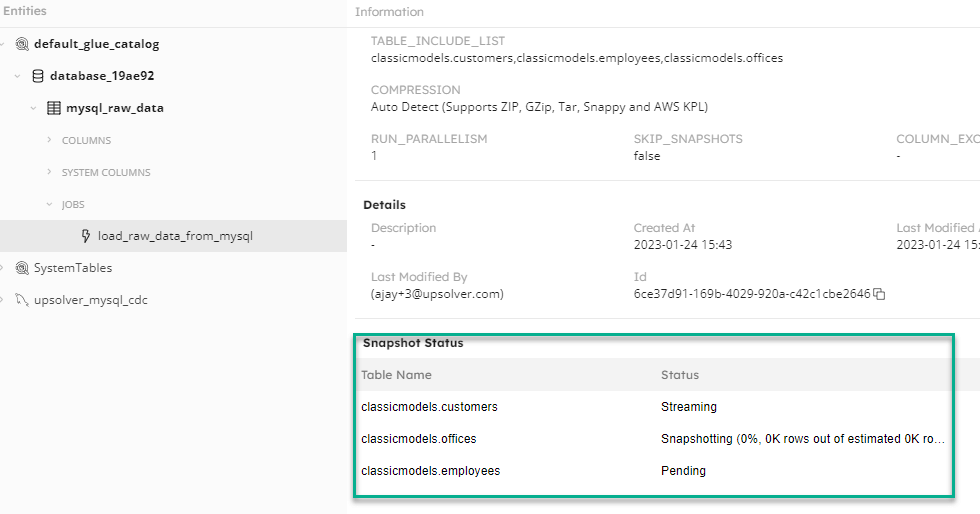
How to build MySQL CDC Pipeline to Lake in Minutes
Learn how to configure your MySQL database to enable CDC, and learn how to build…

Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products