
Explore our expert-made templates & start with the right one for you.
Data Management: Schema-on-Write Vs. Schema-on-Read
-
 Upsolver Team
Upsolver Team
- Cloud Architecture
- November 25, 2020
The data management constructs, schema-on-read and schema-on-write are designed to store and prepare data for processing and analysis.
All data management systems can be categorized either as a schema-on-read or a schema-on-write system. In other words, all data management systems belong to one of these two schemas.
What is Data Management?
At the outset of this discussion, let’s look at what data management is. The proper management of data is the raison d’etre for both these schemas. Without these schemas, there can be no data management. And without data, there will be no reason for these constructs to exist.
Techtarget.com provides the answer to this question. Succinctly stated, “data management is the process of ingesting, storing, organizing, and maintaining the data created and collected by an organization.”
Effective data management is a critical aspect of deploying IT systems that run business applications and store the data collected as a consequence of these business processes. Data is also seen as a corporate asset used to make informed business decisions and to optimize and streamline business processes; thereby, reducing costs and increasing output.
Juxtapositionally, the lack of data management leads to incompatible data silos, inconsistent data sets, data swamps instead of data lakes, and data quality problems, resulting in the limited ability of BI (Business Intelligence) and analytics applications to produce correct and viable information.
Thus, it stands to reason that proper data management is crucial in 2020 and beyond, especially within the bounds of Big Data or the massive amounts of data collected by the modern company.
By way of expanding on the “proper data management” principle, let’s look at a comprehensive definition of both schema-on-write and Schema-on-read.
Schema-on-Write: What, Why, and How?
Succinctly stated, this construct is tightly bound to relational database management, including the schema and table creation and data ingestion. The catch-22 here is that the data cannot be uploaded to the tables without the schemas and tables created and configured. Juxtapositionally, a working database framework is not definable without understanding the data’s structure that must be ingested into the database.
One of the most time-consuming tasks when working with a relational database is doing the Extract Transform Load (ETL) work. The raw data is very seldom structured so that it loads into the database without needing transformation to suit the database schema. Therefore, not only must you define the database schema to suit the data, but you must also structure the data to fit the schema. This can be especially challenging when you’re dealing with schema drift and schema evolution.
For instance, let’s assume you have raw data similar to the New York Taxi Trip Record data. And you need to ingest this data into a relational database.
Where do you start?
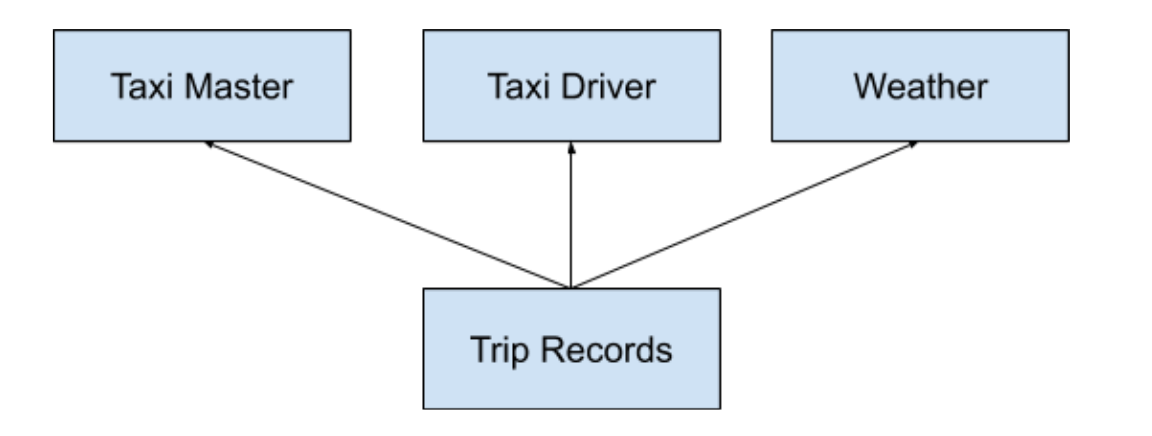
The first step is to define the data entities found in this data. These entities will help you create the database table; ergo, each entity is a table.
Some of the entities or tables needed are:
- The taxi master table – containing the defining features of each taxi.
- The taxi driver master table – containing all the elements of a taxi driver
- The weather master table – the NYC weather plays a fundamental role in the number of trips made over time.
- The trip table – this is a transactional table where information about each trip or journey is kept.
The second step is to define the relationships between each entity.
And the third step is to write a script to create the tables in the database. Let’s define the taxi master table using SQL. In this scenario, the schema name is ny_taxi_trip_records.
CREATE TABLE ny_taxi_trip_records.taxi
(
taxi_id NUMBER GENERATED BY DEFAULT AS IDENTITY
taxi_make VARCHAR2 (50) NOT NULL
taxi_model VARCHAR2 (50) NOT NULL
year_purchased NUMBER
purchase_price FLOAT (10)
PRIMARY KEY (taxi_id)
);
The final step is to write a script containing regular expressions and insert statements to load the data into the database.
This script will change depending on what programming language you use.
Schema-on-Read: What, Why, and How?
The schema-on-read concept counterbalances the schema-on-write construct. The database schema is created when the data is read. The data structures are not applied or initiated before the data is ingested into the database; they are created during the ETL process. This enables unstructured data to be stored in the database.
The primary reason for developing the schema-on-read principle is the exploding growth of unstructured data volumes and the high overhead involved during the schema-on-write process.
One example of a schema-on-read data loading process: Using Upsolver SQLake and Amazon Athena to ingest and analyze raw data stored in an Amazon S3 data lake. Amazon Athena is a SQL engine that runs on top of the S3 data lake; you write SQL statements to query the data in the database:
- The schema is inferred from the raw data, using SQlake to parse and stream the data and Amazon Glue Data Catalog to connect the metadata, schema, and data.
- Athena then runs a SQL query to analyze the data in the data lake.
- As the query runs, SQLake ingests the data based on the schema-on-read principle. The ETL layer creates the database schema based on the schema-on-read. The result: if your data lake contains live data, by using the schema-on-read construct new fields are added to the database schema as the data is loaded.
In this context let’s revisit the example of the taxi:
- The transactional data with details about each trip a taxi driver makes is loaded into an S3 data lake in near real-time. Most of the data is the same.
- At some point new data is added to this feed – for example, weather details for each trip. Until this point, the software application that records trip data only recorded general weather information such as snow, rain, or sunshine. The new data includes the precipitation amount, the time of day it fell, and how long it lasted.
- The schema-on-read process automatically creates new fields in the trip database table and ingests the data.
The Schema-on-Read vs. the Schema-on-Write Constructs
Based on the information described above, it is reasonable to assume that the schema-on-read principle is superior to the schema-on-write principle, especially in an environment where there are large amounts of unstructured data, such as the data that falls within the Big Data ambit.
Not only is the schema-on-read process faster than the schema-on-write process, but it also has the capacity to scale up rapidly. The reason being is that the schema-on-read construct does not utilize data modelers to model a rigid database. It consumes the data as it is being read and is suitable for massive volumes of unstructured data.
Juxtapositionally, the schema-on-write process is slow and resource-intensive. The only time using this principle bears merit is for small amounts of immutable, structured data. As soon as the raw, unstructured data volumes start increasing, the schema-on-read construct is no longer viable.
Upsolver SQLake: Managing Schema Drift Automatically
SQLake, Upsolver’s newest offering, is a declarative self-orchestrating data pipeline platform. SQLake eliminates the data engineering burden of manually re-processing data in reaction to schema drift by auto-detecting the schema of a data source, handling schema drift, and enabling efficient replays (“time travel”) as needed. It adds, deletes, and renames columns and responds when data producers change data types. Data engineers no longer must manage a large number of configuration parameters across multiple systems, or validate performance impact for varying workloads.
SQLake also automatically manages the orchestration of tasks, scales compute resources up and down, and optimizes the output data, so you can deliver high quality, fresh, and reliable data. SQLake enables you to ingest both streaming and batch data with just one tool, using only familiar SQL syntax — making building a pipeline as easy as writing a SQL query.
Try SQLake for free for 30 days. No credit card is required.
To learn more, and for real-world techniques and use cases, head over to our SQLake Builders Hub.
Continue the discussion and ask questions in our Slack Community.
Published in:
Blog
,
Cloud Architecture