
Explore our expert-made templates & start with the right one for you.
Improving Athena performance by 380% with Upsolver
-
 Upsolver Team
Upsolver Team
- Use Cases
- July 22, 2020
Amazon Athena is one of the most widely growing services in the Amazon Cloud, often used as part of a cloud data lake for ad-hoc querying, analytics, and data science on both structured and semi-structured data.
In this article, we’ll walk through a few key data preparation best practices that can have a major impact on query performance in Amazon Athena. We’ll also share some benchmarks of how applying these best practices using Upsolver’s data lake ETL platform can result in improved performance and fresher, more up-to-date data in dashboards built on AWS Athena – all while reducing querying costs.
Example use case: IT monitoring dashboard
To understand why Athena performance matters, let’s look at the following example: An IT organization is running servers in different regions and needs to continuously monitor their performance for outages and spikes in resource utilization, which could explode the company’s infrastructure costs.
Since their data consists of log files, we suggest using a streaming architecture where events are processed by Kinesis before being written to S3. When dealing with very high volumes of semi-structured data and wanting to avoid the complex and costly process of ETLing data into a relational database, leveraging S3 as the storage layer rather than a database such as Amazon Redshift makes the most business sense, since Athena allows you to query data directly from S3.
The challenge
The IT managers want access to most up-to-date data and allow them to address issues in near-real time. In addition, they’re interested in reducing the total costs of running analytics.
To address this, let’s first cover some basics about Athena and the unique characteristics of ETL for Athena. From there we can solve the challenge using data preparation for Athena with Upsolver.
How Amazon Athena works
One of the main advantages of Athena compared to a traditional database such as Redshift is that it is offered as a completely managed service: there are no servers to manage, and AWS automatically provisions resources as needed to execute any given query.
You can then use business intelligence tools to visualize and explore the data. Since there is no infrastructure to manage, Athena can be used as the basis for quickly launching new analytical dashboards and applications.
Data preparation for Athena
If you just need an answer to a single query and don’t care too much about the costs or the time it takes, you can run Athena without any kind of ETL. It will generally retrieve the query, even if not in the most efficient way.
However, where things get tricky is when you need Athena to perform consistently at scale. This can be critical for BI data flows — as in our example — and especially when you expect your dashboard to refresh frequently to reflect changes in real/near real-time. In these cases where performance and costs are important factors, you will need to prepare the data before querying it in Athena. Basically, we need ETL.
Because Athena is a compute engine rather than a database, ETL for Athena is different from database ETL. Since we don’t have things like indexes, upserts, or delete APIs, we’ll need to do the ETL separately over the data stored on S3.
ETL for Athena can be done using Apache Spark running on Amazon EMR or similar solutions. In this case, we will be using Upsolver to ingest data to S3 and continuously optimize the data for querying in Athena (as well as other databases and analytics tools such as Redshift and Redshift Spectrum).
While there are many best practices you can use to improve Athena performance, we’ll focus on the ones that give us the most ‘bang for our buck’ and can produce dramatic improvement in query performance and costs. We’ll then go through some benchmarks that quantify said improvements. Upsolver automatically applies these data preparation best practices as data is ingested and written to S3, but theoretically you could code a similar solution in Spark manually if you have the prerequisite expertise in Scala and time to continuously maintain pipelines.
Improving Athena query performance by 3.8x through ETL optimization
Returning to our initial reference architecture, streaming data from the various servers is streamed via Amazon Kinesis and written to S3 as raw CSV files, with each file representing a single log. In order to improve the performance of our Athena queries, we’ll apply the following data preparation techniques:
- Partitioning: Folders where data is stored on S3, which are physical entities, are mapped to partitions, which are logical entities, in the Glue Data Catalog. Athena leverages partitions in order to retrieve the list of folders that contain relevant data for a query. We used Upsolver to partition the data by event time.
- Compression: We compressed this data using Snappy. While data will need to be decompressed before querying, compression helps us reduce query costs since Athena pricing is based on compressed data.
- Converting to Parquet: Rather than query the CSVs directly in Athena, we used Upsolver to write the data to S3 as Apache Parquet files — an optimized columnar format that is ideal for analytic querying.
- Merging small files (compaction): Since streaming data arrives as a continuous stream of events, we’ll eventually find ourselves with thousands or millions of small files on S3. The need to perform separate reads for small files and their attached metadata is one of the main impediments to analytical performance and a well-documented issue in the Hadoop ecosystem — one that is surprisingly difficult to solve.
In this case, we used Upsolver’s automatic compaction functionality to continuously merge small files into larger files on S3. You can read more about how Upsolver deals with small files in the link. - Pre-aggregating data: After applying the previous optimizations, we created a fourth version of the same data. In this case, we pre-aggregated the data in the ETL layer (using Upsolver) so that data is processed as a stream and stored by key. Aggregations are updated as Upsolver processes additional events, which means data stays consistently up-to-date.
Athena pricing and reducing your costs
Athena is priced at $5 per terabyte scanned. To reduce the costs of Athena, we want to reduce the amount of data scanned. Upsolver uses compaction, partitioning, columnar storage and compression to achieve this. In the examples below, reducing the amount of data scanned translates to an equivalent reduction in costs.
Benchmarking the difference
In order to understand how each of these factors affects the performance of our queries, we’ll look at some “before and after” benchmarks for each of the queries that power the resource utilization dashboard.
The results
Performance
Running on raw CSV, Athena queries returned in 12-18 seconds. This was improved to 2.75 – 5.47 seconds in the most optimized version of the data. On average, queries running on the most optimized version of the data returned 3.8 times faster than on the raw CSV.
Costs
Optimizing the data had a significant impact on the amount of data scanned, which translates into cost savings for scanning larger volumes of data. The largest change was from CSV to Parquet, which cut down the amount of data scanned from gigabytes to a few dozen megabytes for most queries, andre-aggregating the data further cut down this figure to less than 1 megabyte.
The step-by-step SQL queries
Below are each of the SQL queries and the corresponding performance we achieved with Athena when running that query on:
- raw CSV
- the same data converted to Apache Parquet
- the same data converted to Parquet and compacted
- the pre-aggregated version of the data.
In all cases except the CSVs, the Upsolver platform partitioned the data by time and compressed it using Snappy.
Query 1: Daily host count
This is the original SQL we ran in Athena:

These are the results after optimizing the data:

Query 2: CPU host hours per day
The SQL we ran in Athena:

Results after optimizing the data:

Query 3: Daily host count per AWS region
SQL we ran in Athena:

Results after optimizing the data:

Query 4: CPU host hours per AWS region & date
SQL we ran in Athena:

Results after optimizing the data:

Query 5: Clusters per AWS region
SQL we ran in Athena:

Results after optimizing the data:

Query 6: Total CPU host hours per AWS region
SQL we ran in Athena:
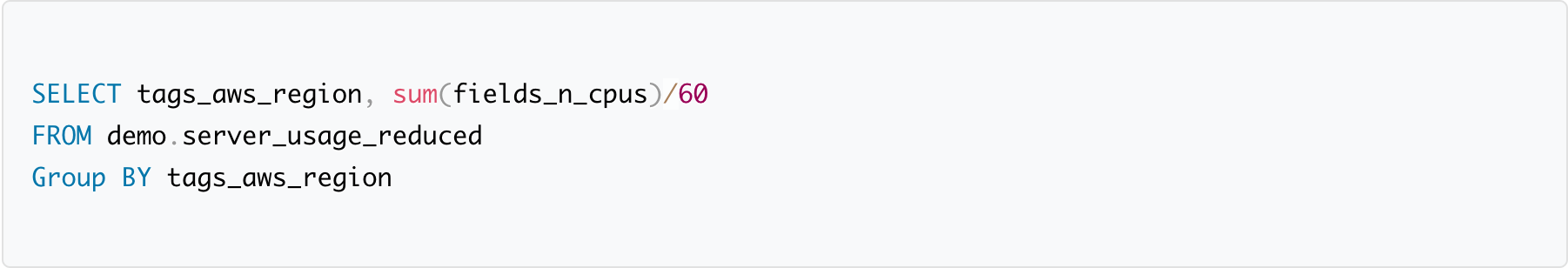
Results after optimizing the data:

Learn more
Want to unlock the value of Amazon Athena with the power of Upsolver? Try a personal demo today.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.