Explore our expert-made templates & start with the right one for you.
Table of contents
Data lakes are key to scalable, open data architectures – but they can pose challenges to data engineering teams. Efficient data integration is the difference between a bunch of log files sitting in Amazon S3 or Azure Storage and a high-performance data lake that provides real value to analytics, data science and engineering teams.
In this guide we will cover some of the essential best practices and guidelines on how to make your data lake analytics-ready using cloud data processing and integration tools.
Principles and Practices in Data Lake Architecture and Design
How do you design a data lake to serve the business, and not weigh down your IT or DevOps department with technical debt and constant data pipeline rejiggering? Keep the following principles and best practices in mind to help stay on track.
Use event sourcing to ensure data traceability and consistency
With traditional databases, you maintain and manage the database state in the database itself, and maintain and manage the transformation code separately. This makes it challenging to ensure the consistency and traceability of data throughout the development lifecycle. For example, in a typical development process, you have data transformation code running and constantly changing, which causes your database to be updated over time. Then one day you must restore the entire system to a previous revision to recover from error or test new code. The transformation code, which is probably backed up in a version control system such as Git, can be easily restored. But your database state has already changed since the time that transformation was running. It’s difficult to restore it to the exact required state without having a backup of the database for each version of your transformation code.
That’s why, in a data lake architecture where compute and storage are separated, you use event sourcing.
In an event sourcing architecture, the approach is “store now, analyze later.” First, maintain an immutable log of all incoming events on object storage, such as Amazon S3. When analytics use cases present themselves, you can create ETL jobs to stream the data from the immutable log to a data consumption platform. This does three things:
- reduces the cost of expensive databases
- enables data teams to validate their hypotheses retroactively
- enables operations teams to trace issues with processed data and fix them quickly by replaying from the immutable log.
Unlike with databases, where the previous state isn’t easily accessible (only backups), event sourcing enables you to “go back in time” and retrace your steps to view the exact transformation applied on your raw data, down to the event level. If there’s an issue in your ETL code, you can easily fix it and run the new code on the immutable original data.
Layer your data lake according to your people’s skills
A data lake is meant to serve many different consumers across the organization, including:
- researchers analyzing network data
- data scientists running predictive algorithms on massive datasets
- business analysts looking to build dashboards and track business performance
An efficient data pipeline ensures each of these consumers gets access to the data using the tools they already know, and without relying on manual work by data providers (DevOps, data engineering) for every new request. Data scientists might want access to almost all fields within the raw data to serve as fodder for neural networks, while business intelligence teams might prefer a much thinner and more structured version to ensure reports are cost-effective and perform well.
In a data lake, you can store multiple copies of the data for different use cases and consumers. By automating the ETL pipelines that ingest the raw data and perform the relevant transformations per use case, you can prevent the data engineering bottleneck that might form if instead you rely on coding-based ETL frameworks such as Apache Spark.
Keep your architecture open
Keeping data accessible means avoiding vendor lock-in, or overreliance on a single tool or database (and the gatekeepers that come with it). The idea behind a data lake is to have all your organizational data in one place while also enabling ubiquitous access to the data with a wide variety of tools, and by a broad range of services.
To create an open architecture:
- Store your data in open formats like Avro and Parquet, which are standard, well-known, and accessible by different tools (rather than proprietary file formats built for a specific database such as Delta Lake).
- Retain historical data in object storage such as Amazon S3. This helps you cut costs compared to storing your data in a database/data warehouse. Storing your data in an object store makes your data available for you no matter the platform you use to manage your data lake and run your ETLs.
- Centralize all your metadata in a metadata repository such as AWS Glue or Hive. This enables you to manage all your metadata in a single location, reducing operational costs in infrastructure, IT resources, and engineering hours. Here, too, it’s advisable to use open-source based storage to avoid vendor lock-in.
Plan for performance
To ensure high performance when querying data, apply storage best practices to make data widely available. For example, in an AWS data lake, you’d use Amazon Athena to query and retrieve data directly from lake storage on Amazon S3. Or you might wish to use databases such as Redshift or Elasticsearch on top of your lake. Regardless, here’s what to keep in mind:
- Every file stored should contain the metadata you need to understand the data structure. Your data lake is being queried by various query engines such as Amazon Athena and Apache Presto. These engines require a schema for querying.
- Use columnar file formats such as Apache Parquet and ORC. Storing your data in columnar format enables you to create metadata for your data, which in turn enables you to understand the structure of your data when querying it. With columnars formats, you can query only the columns you need and avoid scanning redundant data.
- Build an efficient partitioning strategy to ensure queries run optimally by only retrieving the relevant data needed to answer a specific analytical question.
- Keep your data in optimal file sizes (compaction). Consider implementing a Hot/Cold architecture:
o hot – small files for good freshness
o cold – merging small files into bigger files for better performance
Best practices in data lake design
With these principles in mind, here are the best practices we’ve found to help guide you and smooth the path as you design the best data lake for your organization.
Note: While we mostly refer to Amazon S3 as the storage layer, these best practices also apply to a data lake built on a different cloud or using Hadoop on-premises.
Make several copies of the data
A key reason for adopting a data lake is to store massive amounts of data with a relatively low investment – both financially and in engineering hours – since you’re storing the data unstructured and decoupling storage from compute. Take advantage of these newfound storage capabilities by storing both raw and processed data. You can query your database replica on your data lake using a SQL engine such as Athena, Dremio, Starburst, or your cloud data warehouse’s external tables feature (Redshift Spectrum, Snowflake external table).
Keeping a copy of the raw historical data, in its original form, can prove essential when you need to replay a past state of affairs – for example, for error recovery, tracing data lineage, or exploratory analysis. However, this is data you access on an ad-hoc basis; the data you use in analytic workflows should be stored separately and optimized for analytic consumption to ensure fast reads.
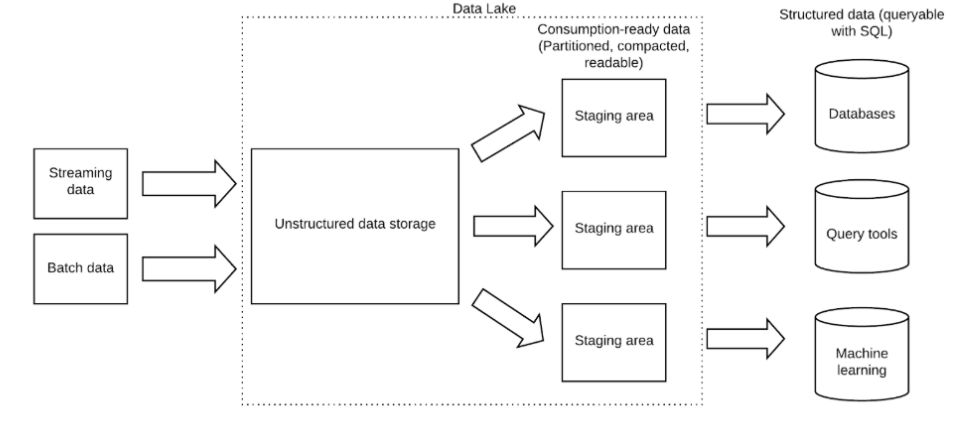
Remember – data lakes aren’t databases. Storage is cheap, there are no clusters to resize, and compute is separate.
Set a retention policy
Inexpensive storage notwithstanding, just because you CAN store some data for longer periods of time doesn’t mean you should store ALL of your data forever. The main reasons to delete some data include:
- Compliance – regulatory requirements such as GDPR might dictate that you delete personally identifiable information after a certain period of time, or at an individual’s request.
- Cost – data lake storage is cheap, but it’s not free; if you’re moving hundreds of terabytes or petabytes of data each day, your cloud bills will escalate.
You also need a way to enforce whatever retention policy you create. This means you must be able to identify the data you wish to delete (as opposed to the data you wish to store for the longer term) and know exactly where to find this data in your object storage layer.
Understand the data you’re ingesting
You must have the ability to understand the data as it is being ingested – the schema of each data source, sparsely populated fields, and so on. Gaining this visibility on read rather than trying to infer it on write saves you a lot of trouble down the line by enabling you to build ETL pipelines based on the most accurate and available data.
Partition your data
Partitioning your data helps reduce query costs and improve performance by limiting the amount of data query engines such as Amazon Athena need to scan in order to return the results for a specific query. Partitions are logical entities referenced by Hive metastores, and which map to folders on Amazon S3 where the data is physically stored.
Data is commonly partitioned by timestamp – which could mean by hour, by minute or by day – and the size of the partition should depend on the type of query we intend to run. If most of our queries require data from the last 12 hours, we might want to use hourly partitioning rather than daily in order to scan less data.
Create readable file formats
Columnar storage makes data easy to read, which is the reason to store the data you plan to use for analytics in a format such as Apache Parquet or ORC. In addition to being optimized for reads, these file formats have the advantage of being open-source rather than proprietary; you can read them using a variety of analytic services.
In the same vein, you must decompress the data before reading. Applying compression to your data makes sense from a cost perspective, but be sure to choose compression that is relatively weak to prevent wasting unnecessary compute power.
Merge small files
Data streams, logs, or change-data-capture typically produces thousands or millions of small event files every single day. You could try to query these small files directly. But doing so negatively impacts your performance over time. That’s why it’s important to merge small files.
Establish data governance and access control
Some CISOs are reasonably suspicious of the idea of dumping all their data into an unstructured repository, making it difficult to set specific row, column, or table-based permissions as in a database. But modern cloud data lakes include a range of governance tools that give you control over who can see what data. For example, Amazon cloud’s Lake Formation creates a data catalog that enables you to set access control for data and metadata stored in S3.
Data Lake Components: Ingestion, ETL and Storage
Okay. With principles and guidelines in mind, and a design in place, it’s time to start building. But just as with conceptual design, there are best practices you can put in place to help ensure you build not just what you’re envisioning now, but what will support organizational growth going forward. That’s in the next two sections.
While storing all your data on unstructured object storage such as Amazon S3 might seem deceptively straightforward, there are many pitfalls to avoid. The way your data is ingested and delivered can dramatically impact the performance and utility of your data lake.
Get the Ingestion Right: 7 Guidelines for Ingestion
Data ingestion is a key component of big data architectures. But data not ingested and stored according to best practices becomes very difficult to access. Mistakes made early on can harshly restrict data lake utility. And it’s very difficult to “reorganize” data once it’s in the lake.
Blindly dumping data into S3 is a bad strategy. So it’s critical to formulate a project plan fo ingesting data before you begin. Be flexible, enable experimental use cases, and understand what you intend to do with the data, what types of tools you may wish to use, and how best to store your data for these tools to work properly.
For example, if you’re going to be run ad-hoc analytic queries on terabytes of data, you’ll likely use Amazon Athena. Optimizing lake storage can dramatically impact the performance and costs of your queries in Athena.
Here are 6 best practices for data ingestion – from strategic principles down to the more tactical (and technical) issues to keep in mind when building ingest pipelines and creating a high-performing and widely-accessible data lake.
Note that enforcing some of these best practices requires a high level of technical expertise – if you feel your data engineering team could be put to better use, you might want to look into an ETL tool for Amazon S3 that can automatically ingest data to cloud storage and store it according to best practices.
For the purposes of this section we assume you’re building your data lake on Amazon S3. But most of the advice applies to other types of cloud or on-premises object storage including HDFS, Azure DLS, or Google Cloud Storage; they also apply regardless of which framework or service you’re using to build your lake – Apache Kafka, Apache Flume, Amazon Kinesis, Firehose, and so on.
1. Visibility upon ingest
Don’t wait for data to actually be in your lake before knowing exactly what it is. Maintain visibility into the schema and a general idea of what your data contains even as it is being streamed into the lake, especially if your schema changes frequently. This removes the need for “blind ETL” or reliance on partial samples for schema discovery later on. You could write ETL code that pulls a sample of the data from your message broker and infer schema and statistics based on that sample. Or you could use a tool that automates the process.
2. Lexicographic ordering on S3
Use a lexicographic date format (yyyy/mm/dd) when storing your data on S3. S3 lists fiiles in lexicographic order, so failing to store them in the correct format causes problems when retrieving the data in the future.
3. Data compression
Yes – storage on S3 is cheap. But when you’re processing terabytes or petabytes of data on a daily basis, it still gets costly. So it’s still important to compress your data.
When choosing the compression format, note that very strong compression might actually increase your costs when querying the data since you’ll have to uncompress the data before you query it. This incurs compute costs that are greater than what you may be saving on storage. And using super-strong compression such as BZ2 makes your data lake unusable.
Instead, opt for weaker compression that reads fast and lowers CPU costs – Snappy and GZip are two examples – to reduce your overall cost of ownership.
4. Reduced number of files
Even before you run your compaction process, reduce the number of events you’re ingesting in a single write. Kafka producers might be sending thousands of messages per second; storing each of these as separate files increases disk reads and degrades performance.
5. Compaction
It’s crucial for optimal performance to merge small files when you define an output to Athena. Best practices suggest an optimal file size of approximately 500 MB; a good compaction frequency is approximately every 10 minutes.
6. Self-describing file formats
Every file you store should contain the metadata needed to understand the data contained in that file. That makes analytic querying far simpler. For optimal performance during query execution, use a columnar format such as Parquet or ORC. For the ETL staging layer, use row-based Avro or JSON.
7. Exactly-once processing
Duplicate events or missed events can significantly hurt the reliability of the data stored in your lake. Exactly-once processing is difficult to implement, since your storage layer is only eventually (not instantly) consistent, especially with streaming events. But whether coding your own solution or relying on an automated tool, exactly-once processing is critical for preserving the integrity of the data in your lake.
Get the ETL Right: 6 Guidelines for Evaluating Tools
To ensure your data lake works optimally for analytics or machine learning, build ETL flows that transform raw data into structured datasets you can query with SQL.
There are many options for data lake ETL – from open-source frameworks such as Apache Spark, to managed solutions offered by companies like Databricks and StreamSets, and purpose-built data lake ETL tools such as Upsolver. (More on these options later in this eB00k.) Evaluate these tools within the context of the unique challenges of data lake ETL compared to traditional database ETL, and choose a platform that addresses these specific hurdles.
Let’s look at the top 6 considerations when evaluating a data lake ETL platform. We’ll often clarify by contrasting with a relational database, which isn’t designed for streaming or very high volumes of data.
1. Stateful transformations – ETL vs ELT
The ability to perform joins, aggregations, and other stateful operations is core to analyzing data from multiple sources, and it’s a basic feature available in traditional ETL frameworks. But in a decoupled architecture it’s also difficult to implement.
Data warehouses typically rely on an ELT (extract-load-transform) process in which data is sent to an intermediary database or data mart. Stateful transformations are performed using SQL, historical data already accumulated, and the database’s processing power, and then loaded to the data warehouse table.
But relying on a database for every operation defeats the data lake purpose of reducing costs and complexity via decoupled architecture. So when you evaluate data lake ETL tools, choose a transformation engine that can perform stateful operations in-memory and support joins and aggregations without an additional database.
2. Support for evolving schema-on-read
Databases and SQL are designed around structured tables. But data lakes are typically used as repositories for raw data in structured or semi-structured form (such as log data in JSON format) or unstructured form. Since it’s impossible to query data without some kind of schema, data lake ETL tools must extract schema from raw data and update it as new data is generated and the data structure changes. Ideally you should be able to query arrays with nested data, though many ETL tools struggle with this.
3. Optimized object storage for improved query performance
A database optimizes its file system to return query results quickly. Trying to read raw data directly from a data lake results in terrible performance (up to 100-1000x higher latencies). Data must be stored in columnar formats such as Apache Parquet and small files must be merged to the 200mb-1gb range to ensure high-performance. The ETL framework you have in place should perform these processes on an ongoing basis.
Traditional ETL tools are built around batch processes in which the data is written once to the target database. Data lake ETL tools should write data to the lake multiple times to continuously optimize the storage layer for query performance.
4. Integration with metadata catalogs
Data lakes are meant to be flexible and open. They store metadata separately from the engine that queries the data. This makes it easy to replace query engines or use multiple engines at the same time for the same copy of the data.
For example, you can use Hive Metastore or AWS Glue Data Catalog to store metadata, then query using Apache Presto, Amazon Athena, and Redshift Spectrum – with all queries running against the same underlying data.
A data lake ETL tool should support this open architecture via tight integration with the metadata catalog. Metadata is both stored in the catalog and continuously synced with every change (location of objects, schema, partition), so data remains easily queryable by various services.
5. Enabling “time-travel” on object storage
Data lakes are based on an event sourcing architecture where raw data is stored untouched. To test a hypothesis, data practitioners stream historical data from object storage for quick validation. Data lake ETL must reduce the friction of orchestrating such ad-hoc workloads and make it easy to extract a historical dataset, without creating large operational overhead.
This is difficult to achieve in databases, which store data in a mutable state. In many cases this prohibits testing a hypothesis on historical data. Other cases are prohibitively expensive due to the performance stress and costs of running such a query, creating tension between operations and exploratory analysis.
6. Ability to update tables over time
While databases typically support updates and deletes to tables, data lakes are composed of partitioned files based on an append-only model. This makes it difficult to store transactional data, implement CDC in a data lake, or delete specific records for GDPR compliance.
Modern data lake ETL tools should instead enable upserts in the storage layer, as well as in the output tables used for analytic purposes.
Next, do you build your data lake infrastructure yourself? Use an end-to-end proprietary platform? Or rely on an open lakehouse platform? The next section touches on this choice.
Navigating Data Pipeline Platform Options
In this section:
- Build it Yourself
- Use a Proprietary Managed Platform
- Use an Open Lakehouse Platform
As you evaluate with whom to partner to implement your data lake, you have several choices.
- Build it yourself entirely with open source
- Use a proprietary managed platform
- Use an open lakehouse platform
Build it yourself using Spark
While Apache Spark itself is open-source and so does not come with any direct licensing costs, the overall cost of a Spark deployment tends to be very high, with the major cost factors being hardware and personnel. As robust as it is, Spark is still only part of a larger big data framework demanding a wide array of specialized skills with tools such as Flink, Airflow, NoSQL databases, and more. For example:
- Building data transformations in Spark requires lengthy coding in Scala.
- Much custom development and manual tuning is required indefinitely for a Spark pipeline to continue to perform well at scale.
- Every new dashboard or report that requires a new ETL flow, or changes to an existing pipeline, must go through the DevOps or IT silo before going into production, creating delays and friction with the business analyst and data scientist end users.
Finally, it’s extremely difficult to use Spark to process streaming data, effectively ruling out the possibility of real-time or near-real-time analytics. More details on using Spark to build a data lake.
Use a proprietary managed platform
Managed platforms, such as Databricks, handle most of the infrastructure creation and management. And they can be efficient. The primary hurdle here is the proprietary nature of these systems. You are effectively locked in to their technology and tools for SQL analytics, streaming, machine learning, text search, and so on – tools which may not be what your data practitioners are familiar with or desire.
For example, Delta Lake tables are a combination of Parquet based storage, a Delta transaction log, and Delta indexes which can only be written to or read by a Delta cluster. This strictly limits your choice of tools, especially query engines, for getting value from your data lake. Should you change your mind, it’s expensive to get your data out of these systems and reformat it to get it into a different system. You also can grow your system only at the vendor’s pace; you risk missing out on some of the innovation occurring in the data lake space.
Finally, these services aren’t turnkey; some manual coding remains necessary. For example, in Databricks you still must write and maintain code in Scala (or Java, or Python) to prepare the data you wish to store.
Use an open lakehouse platform
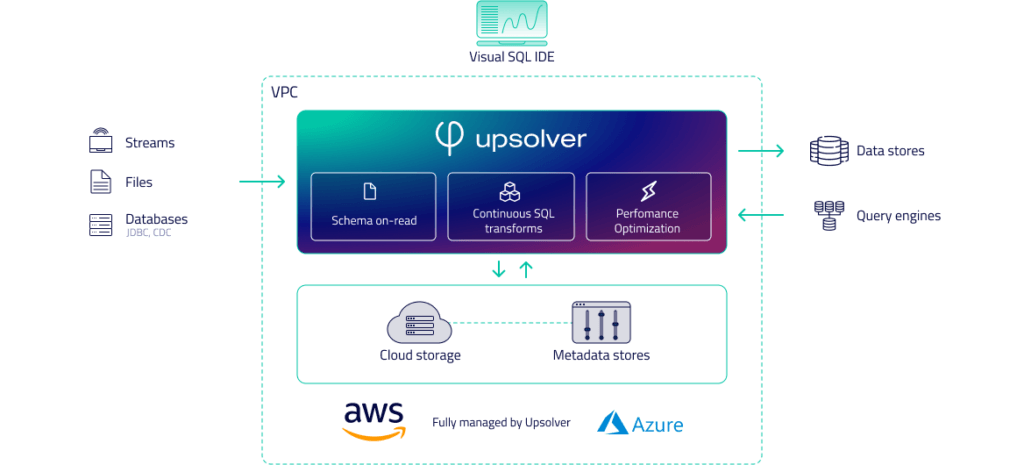
An open lakehouse platform can give you the best of both worlds – a fully-managed service that also preserves your ability to create an architecture consisting of just the components you wish. In Upsolver’s case, in addition to providing a platform designed for streaming data and real-time analytics, the platform also automates the coding-intensive processes associated with building and managing the cloud data lake. It simplifies and automates the process of preparing data for consumption, and enforces best practices for optimized query performance as data is ingested and then stored in the data lake for later analysis.
By leveraging open standards in a data lake, you can choose to query data directly from tables in the data lake or distribute the prepared data out to the systems of your choice.
Below are brief descriptions of how Upsolver addresses the challenges of building a modern cloud data lake:
- No-code, low-code, or high-code. Build and manage a data lake declaratively, defining your business logic and tables and processing data using a visual IDE and SQL rather than code. Any data practitioner familiar with ANSI SQL can use the IDE, including DBAs, data architects, analysts, data scientists, product managers and big data engineers. Upsolver’s data transformation language is based on SQL and is extensible with Python.
- Elastic Scaling. Upsolver runs on fully managed clusters (dedicated per customer) and never stores data on local servers. Processing scales elastically according to workload.
- Data privacy –Deploy Upsolver in your VPC or in Upsolver’s, Upsolver clusters read data from S3, process it in-memory and write back to the S3 bucket. Upsolver never store any of your data; you just choose where our processing, serving, and streaming clusters reside.
- Create visibility upon ingest – Use the visual IDE to preview all data pipelines to maintain schema visibility.
- Exactly-once processing from Kafka or Kinesis via idempotent operations to prevent duplicate or missed events.
- Stateful transformations – performs stateful operations in-memory and supports joins and aggregations without an additional database.
- Support for evolving schema-on-read – extracts schema from raw data and update it as new data is generated and the data structure changes, ideally including querying arrays with nested data.
- Optimized object storage for improved query performance – Writes data to the lake multiple times to continuously optimize the storage layer for query performance. Enforces performance-tuning best practices as data is ingested and stored in the lake, including:
- data partitioning
- merging of small files
- data compaction (to create optimal file sizes for fast querying)
- columnar formats such as Parquet or ORC for query execution; row-based Avro or JSON for the ETL staging layer
- Weak file compression with Snappy or GZip
- Integration with metadata catalogs – stores all metadata in the catalog (Hive or Glue), and continuously syncs it with every change (location of objects, schema, partition)
- Enabling “time-travel” on object storage – orchestrates ad-hoc workloads:
- data practitioners can test hypotheses by streaming historical data from object storage for quick validation
- DevOps can “replay” events for data traceability and troubleshooting.
- Ability to update tables over time – enables upserts in the storage layer, as well as in the output tables used for analytic purposes. Continuously stream CDC logs from any on-premises or cloud MySQL database; streaming data remains up to date as data and even schema changes.
Upsolver reference architecture