Explore our expert-made templates & start with the right one for you.
Upsolver on Amazon Web Services
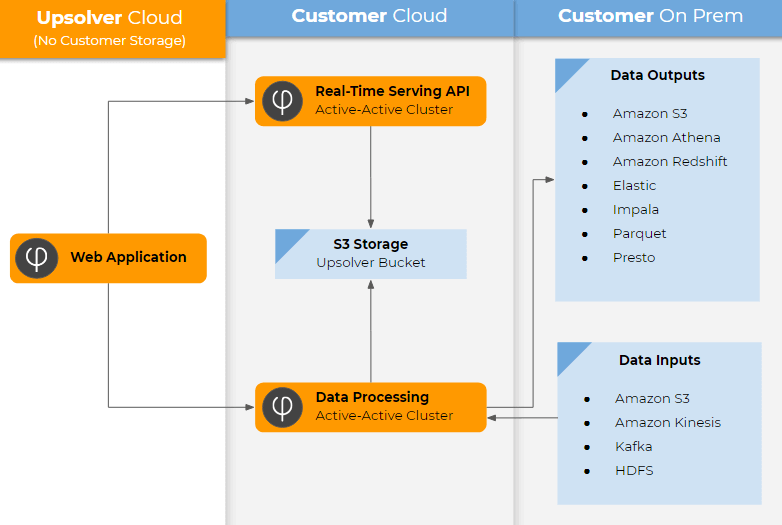
Introduce self-service agility to your AWS data lake by making it easy for data consumers to ingest, manage and structure streaming data.
Get a Demo
The Full-stack Streaming Data Platform, Built for AWS
Empower data consumers to be self-sufficient with event streams.
Create event driven applications on AWS using a simple user interface and stateful stream computations, with fully automated DataOps – pipeline orchestration, scaling, error recovery, replay and more.
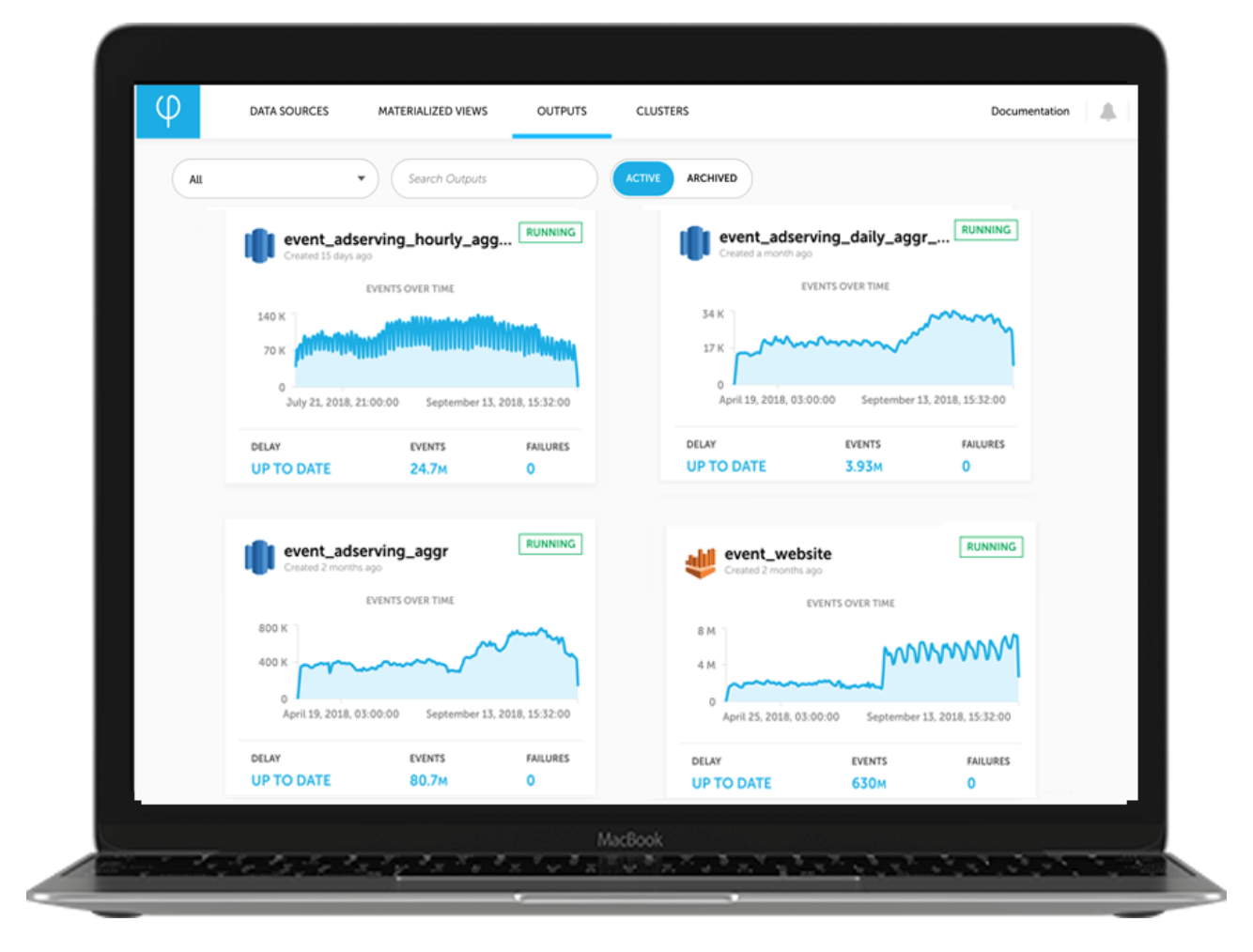
Easily build, manage and create value from your S3 data lake.
Don’t just dump data blindly into S3 – Upsolver’s data lake ingestion tools let you see schema-on-write, statistics and visualization to ensure you’re creating a data lake and not a swamp.
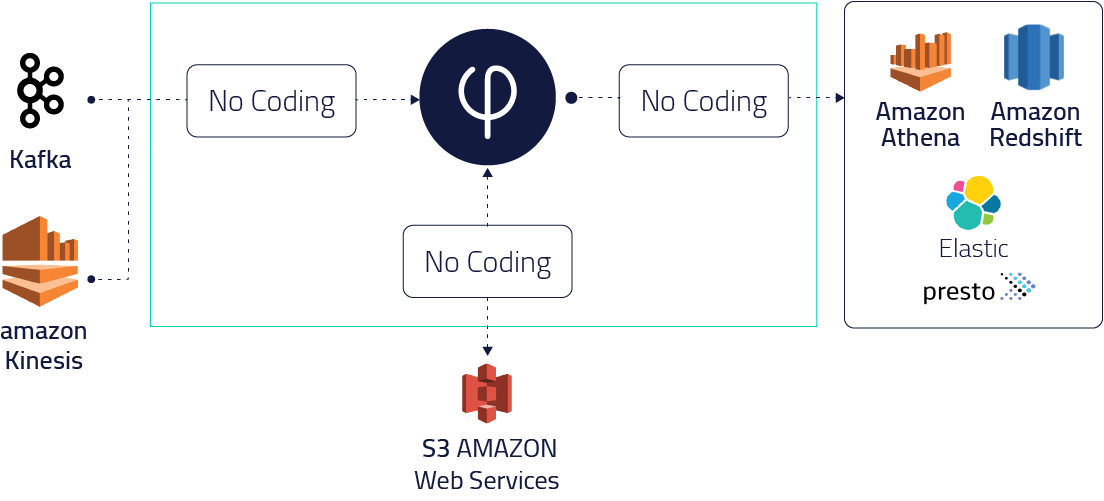
High scale decoupled architecture to reduce costs and improve performance
Upsolver runs in-memory over object stores (no local storage) and scales to 1000s of nodes. Queries in engines like AWS Athena run up to 100X faster using Upsolver data.

Works seamlessly with your existing AWS stack
Get a demo now or start for free on the Community Edition
Operations in Upsolver are translated to SQL and pushed to Git. Data is ingested and stored using open formats like Avro/Parquet.
Output data to your favorite AWS tools and databases – Athena, Redshift, Elasticsearch – to support a wide variety of use cases across your organization.

Deploy securely on public or private VPC
Your data is only persisted to your Amazon S3 storage, with data processing in public or private VPC.