Explore our expert-made templates & start with the right one for you.
Use SQL Data Pipelines to Unlock the Value of your Cloud Data Lake
Cloud data lakes are reliable, scalable and affordable. However, the complexity of writing code and orchestrating pipelines on raw object storage have held data lakes back from having the impact they should.
Upsolver uses a declarative approach based on SQL transformations to eliminates those barriers, so you get simplicity combined with data lake power and affordability.
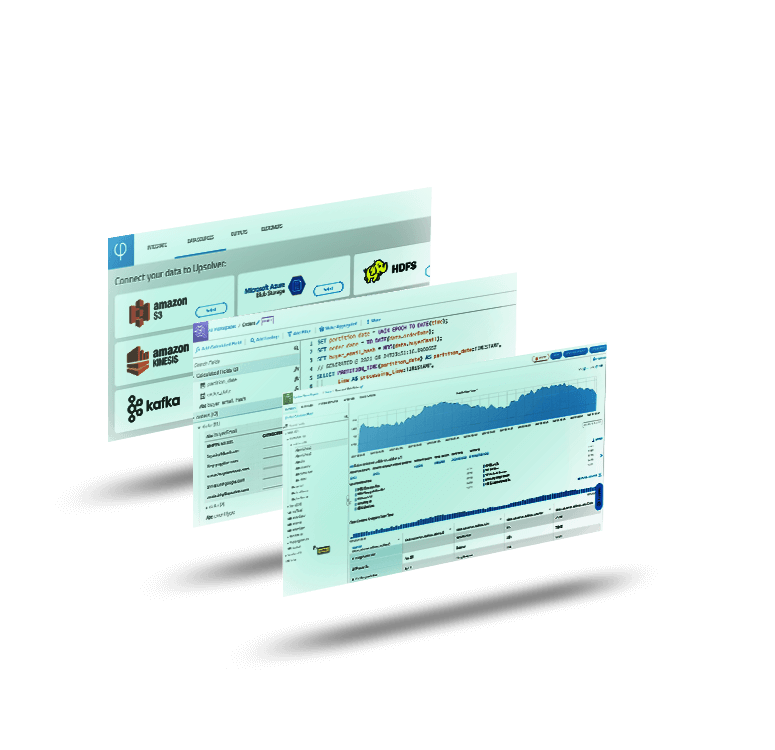
Unblock Data Engineering with Declarative Pipelines and No Orchestration
Build data pipelines in days not months without writing code or manually orchestrating jobs. Eliminate time-consuming pipeline engineering work and leverage SQL to declaratively specify transformations.
Combine Streaming and Historical Batch Data for Real-time Analytics
Continuously deliver up-to-the-minute fresh, analytics-ready tables to query engines, cloud data warehouses and streaming platforms. Even with nested, semi-structured and array data. No more stale analytics based on nightly or weekly jobs.
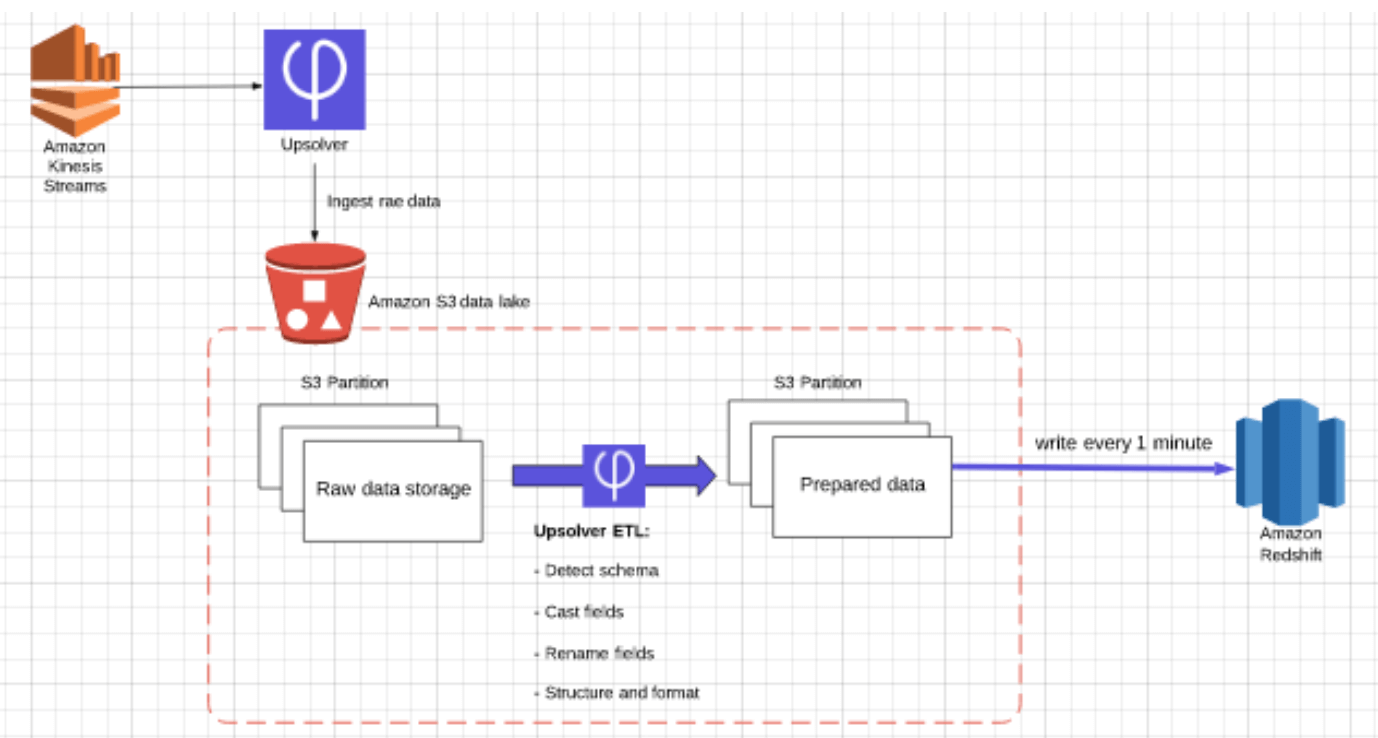
Reduce Cost and Effort vs. Data Warehouse ELT
Process complex, continuous data on your cost-effective data lake for downstream use in your data warehouse. Greatly reduce your data warehouse costs for ingestion, compute and storage. Build pipelines using SQL and automation, reducing your data engineering overhead and time-to-value as well.
Accelerate Queries on Data Lake Tables
Upsolver’s technology makes your query engine respond faster than you could imagine. Easily create tables directly from cloud object storage for use by AWS Athena, Redshift Spectrum, Dremio and other leading engines.
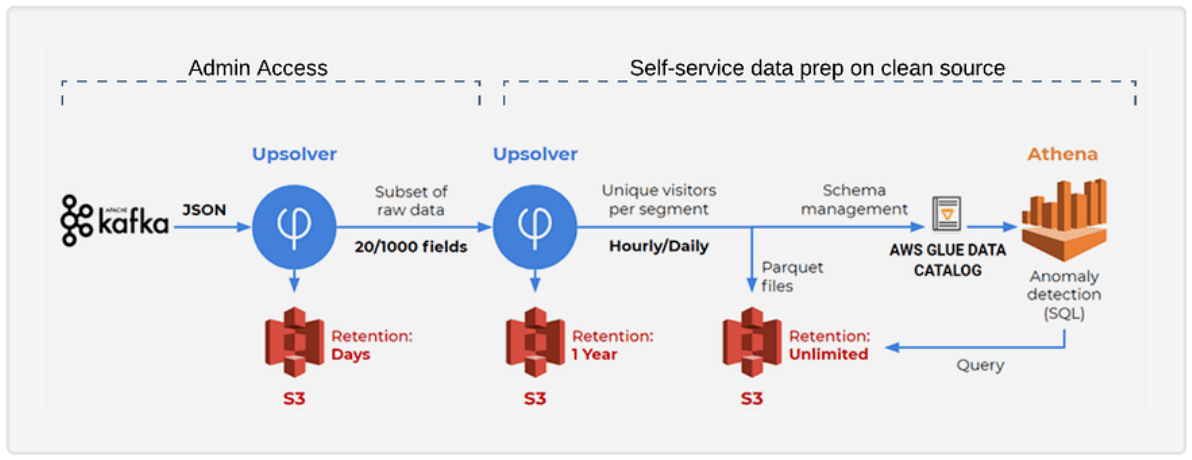
Replicate Databases via CDC
Make the valuable data in your OLTP databases instantly available for data lake analytics in 3 simple steps, using log-based CDC to avoid impacting source database performance.
Additional Solutions by Use Case
Log Analytics
Learn how Upsolver helps analyze log data in near real time.
Data Lake Ingestion
Store event streams as optimized Parquet, in a click.
Kafka to Redshift
Get continuous data into analytics-ready Redshift tables.
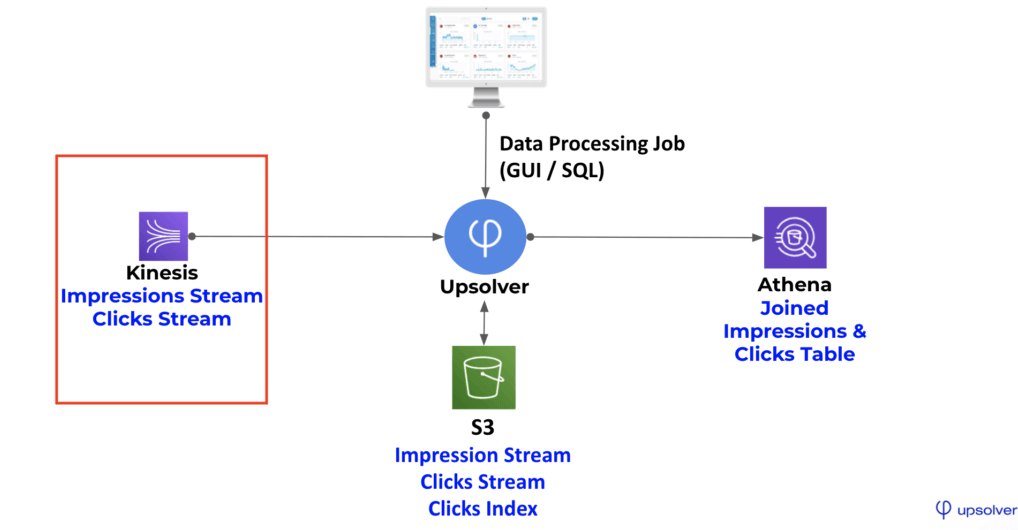
Kinesis to Athena
Simplify storage, reduce query costs, and improve performance.