

Explore our expert-made templates & start with the right one for you.
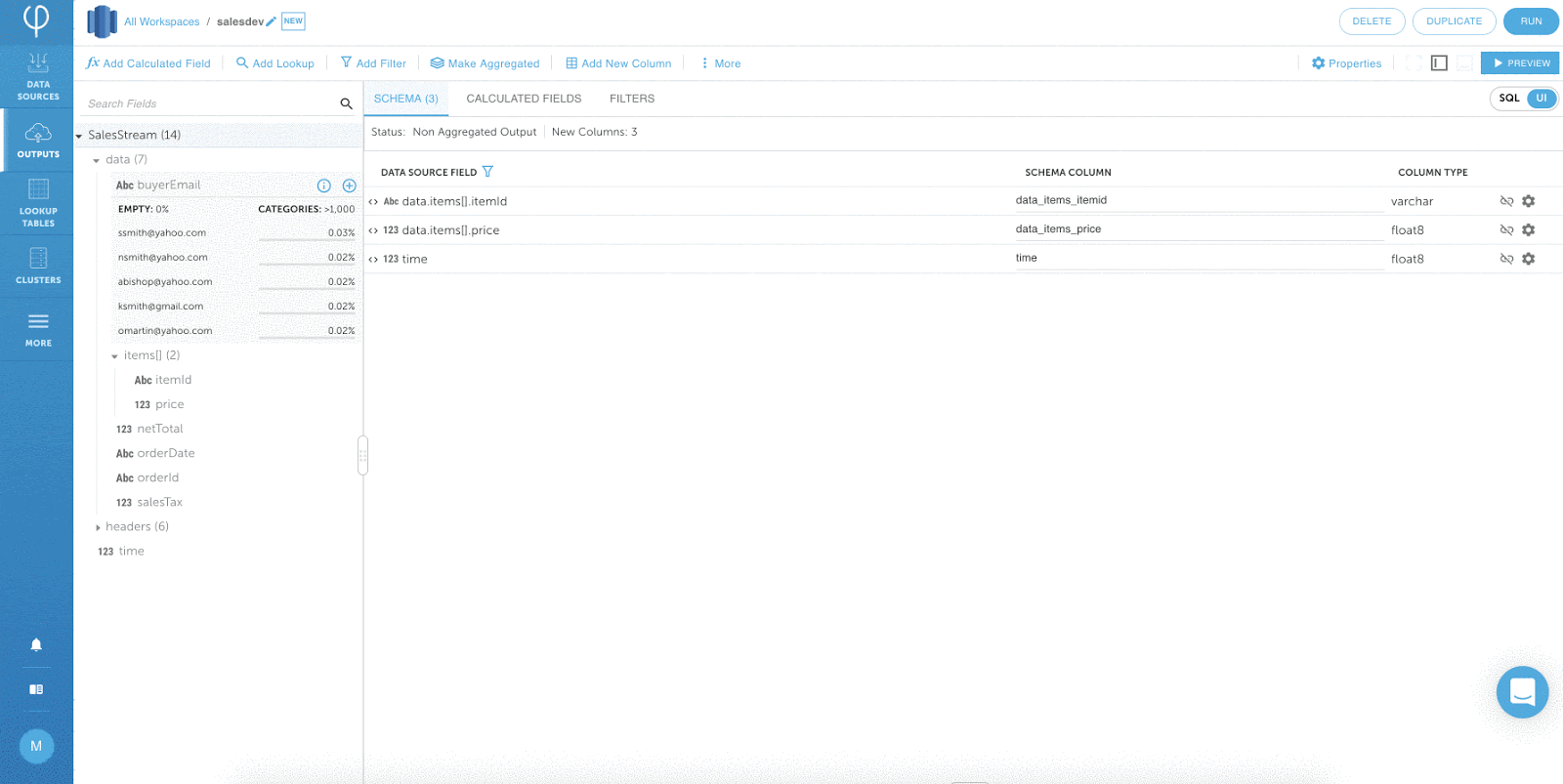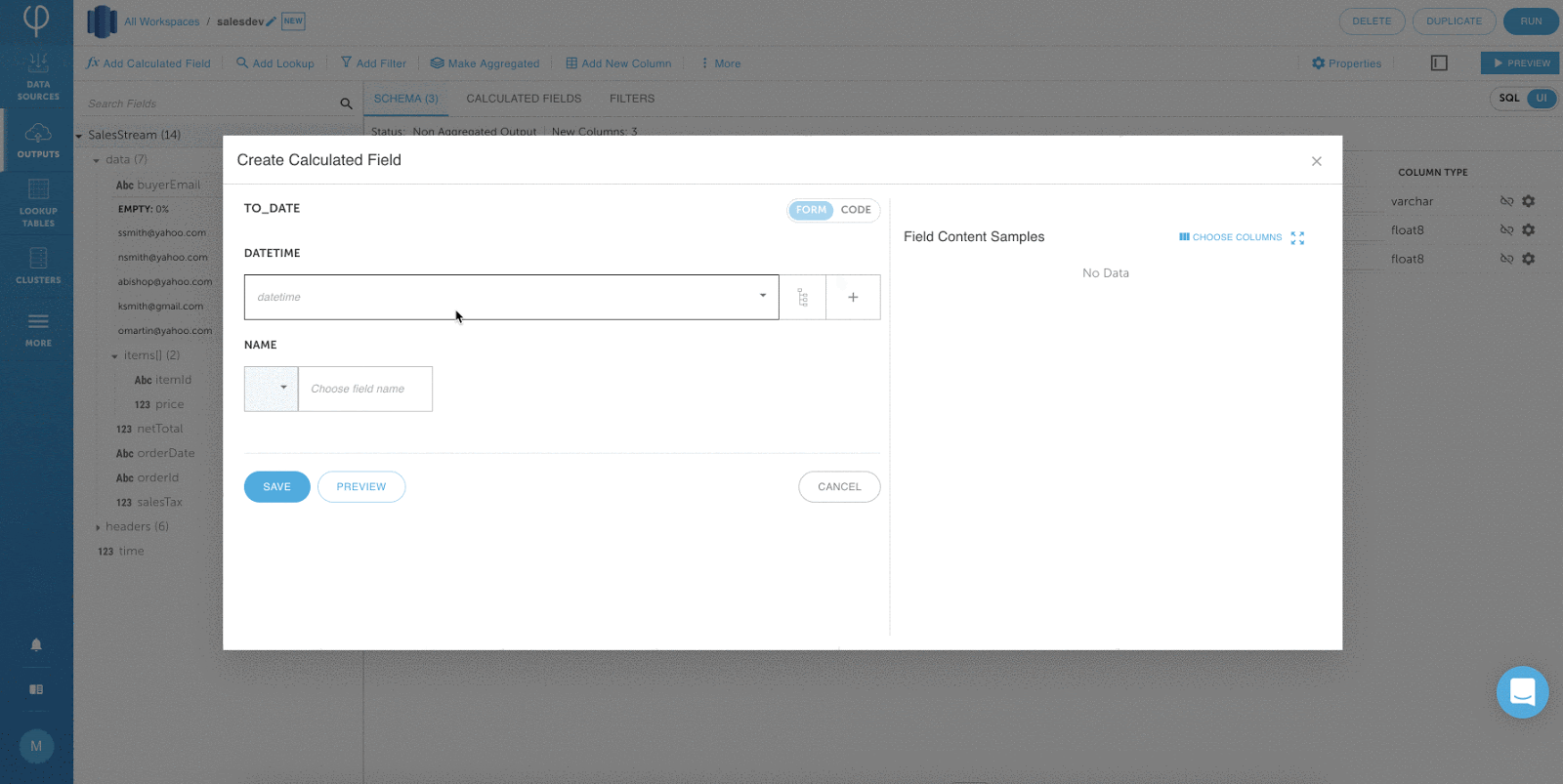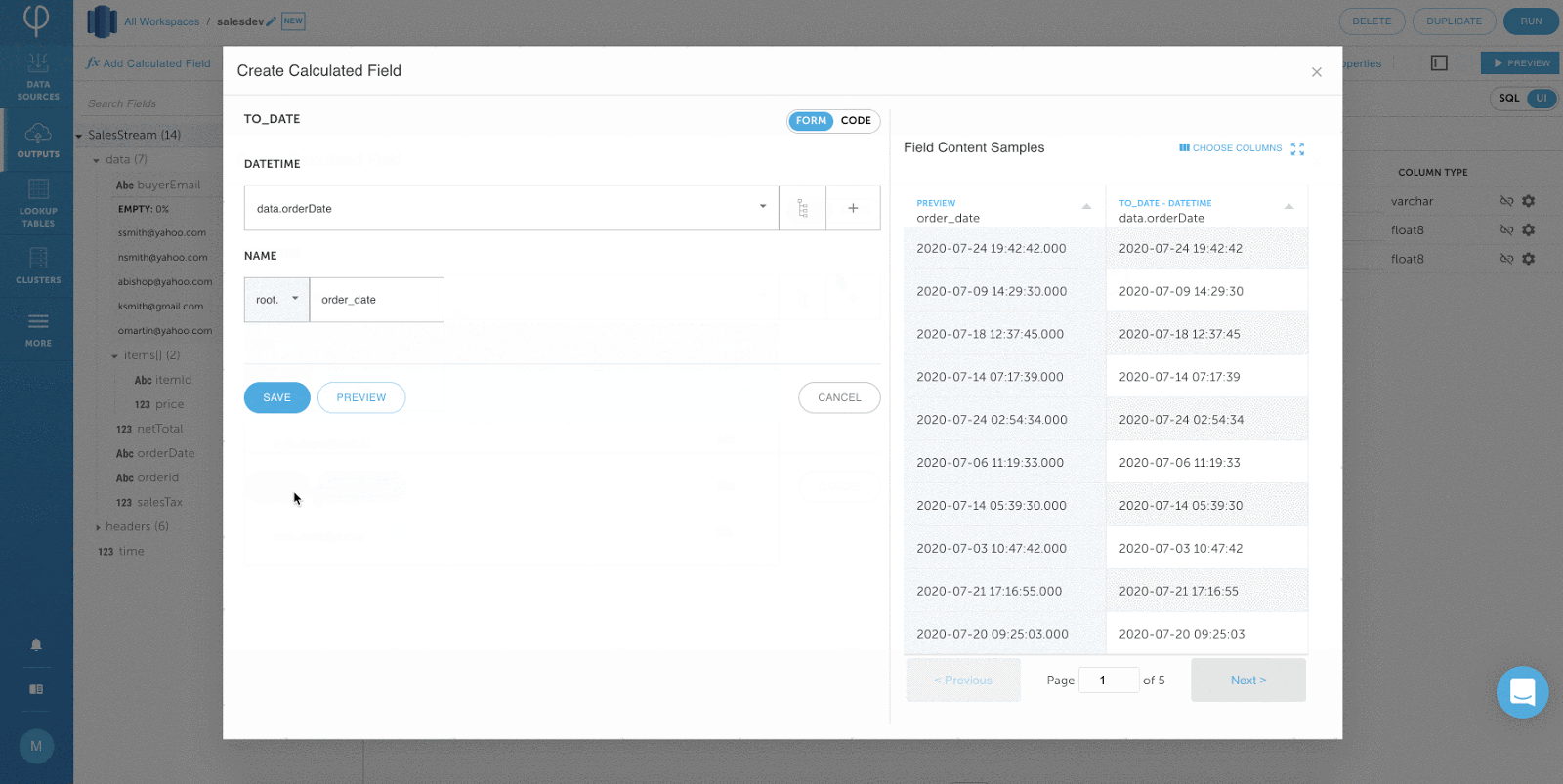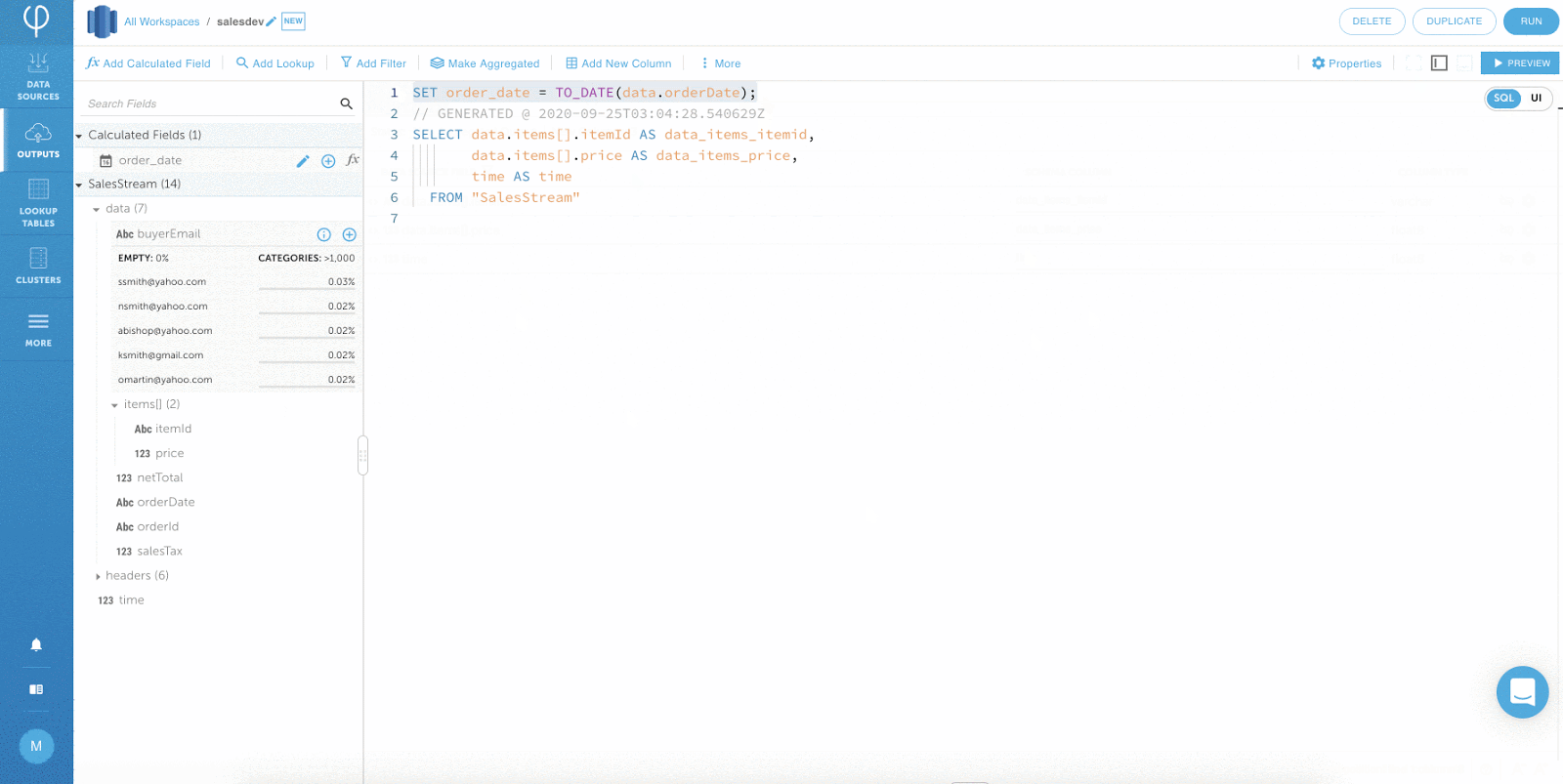
Moving Data from Kafka to Redshift?
Your continuous SQL pipeline is ready.

Simplify Your Kafka Pipelines
Amazon Redshift is the go-to for running your BI and reporting workloads, but storing raw Kafka streams in Redshift can be complex and expensive.
Upsolver lets you instantly launch a continuous data pipeline that transforms data from Kafka and writes it to analytics-ready Redshift tables, while storing the raw data on your S3 data lake for resilience, replay and cost reduction.
Key Features and Benefits
Get your continuous data into Redshift
Easily deploy and manage Kafka pipelines that just work, with data that’s always structured and fresh. Set it and forget it – no data plumbing required.
Build low-code pipelines using SQL and automated orchestration
Forget complex Scala coding and stop struggling with Airflow workflows. With Upsolver, building high-performance data infrastructure is as simple as SQL.
Control data warehouse costs
Avoid the high costs of storing and transforming streaming data in-warehouse by leveraging S3 storage and Upsolver’s efficient transformation engine
Focus on analytics, not pipelines
Don’t waste your top engineering talent on writing Spark pipelines. Ingest, transform and move data into Redshift in a fraction of the time and cost
Scale to petabytes easily
Upsolver’s continuous SQL pipelines scale to petabytes without skipping a beat, allowing your data platform to scale as fast as your business does.
Streaming joins, transformations and ingestion made easy
Upsolver makes all your biggest data engineering pains disappear: from exactly-once processing to dealing with small files to joining two streams in-flight.
Trusted by Data-Intensive Companies



“We want to minimize the time our engineering teams, including DevOps, spend on infrastructure and maximize the time spent developing features. Upsolver has saved thousands of engineering hours and significantly reduced total cost of ownership, which enables us to invest these resources in continuing our hypergrowth rather than data pipelines.”
Seva Feldman, VP of R&D

See a live pipeline example in our interactive, end-to-end demo.
- Play with an SQL data pipeline instantly
- Learn how to address common challenges
- Get unlimited access to the Upsolver Community Edition (no CC required)