Explore our expert-made templates & start with the right one for you.
Reduce Cost and Effort vs. Data Warehouse ELT
Get a Demo
Cloud data warehouses have become the go-to store for business intelligence reporting and ad hoc analytics on structured data. However, cloud data warehouses are built for serving end-user queries on batch data sets. When it comes to continuous data preparation they are too slow and expensive.
Also, they are full-stack solutions that include a closed storage layer and captive query engine, which locks you into a single platform and limits your future analytics options, restricts data availability and stifles innovation.
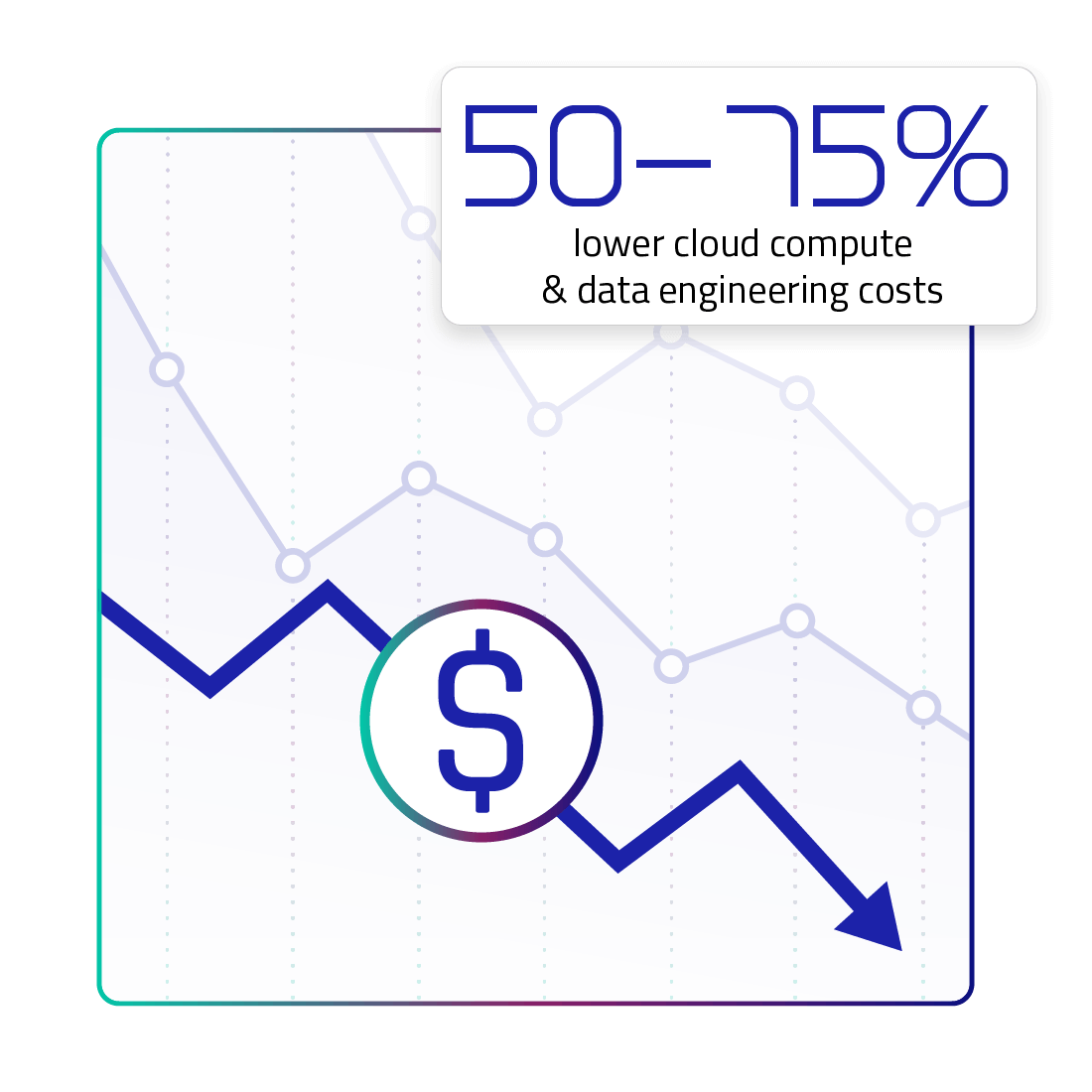
Cut Transformation Costs in Half using Incremental ETL on the Data Lake
By using Upsolver pipelines to transform your continuous data on the data lake, you greatly reduce your compute costs while maintaining data freshness for consuming end-users and apps.
50%+ Reduction in Transformation Costs
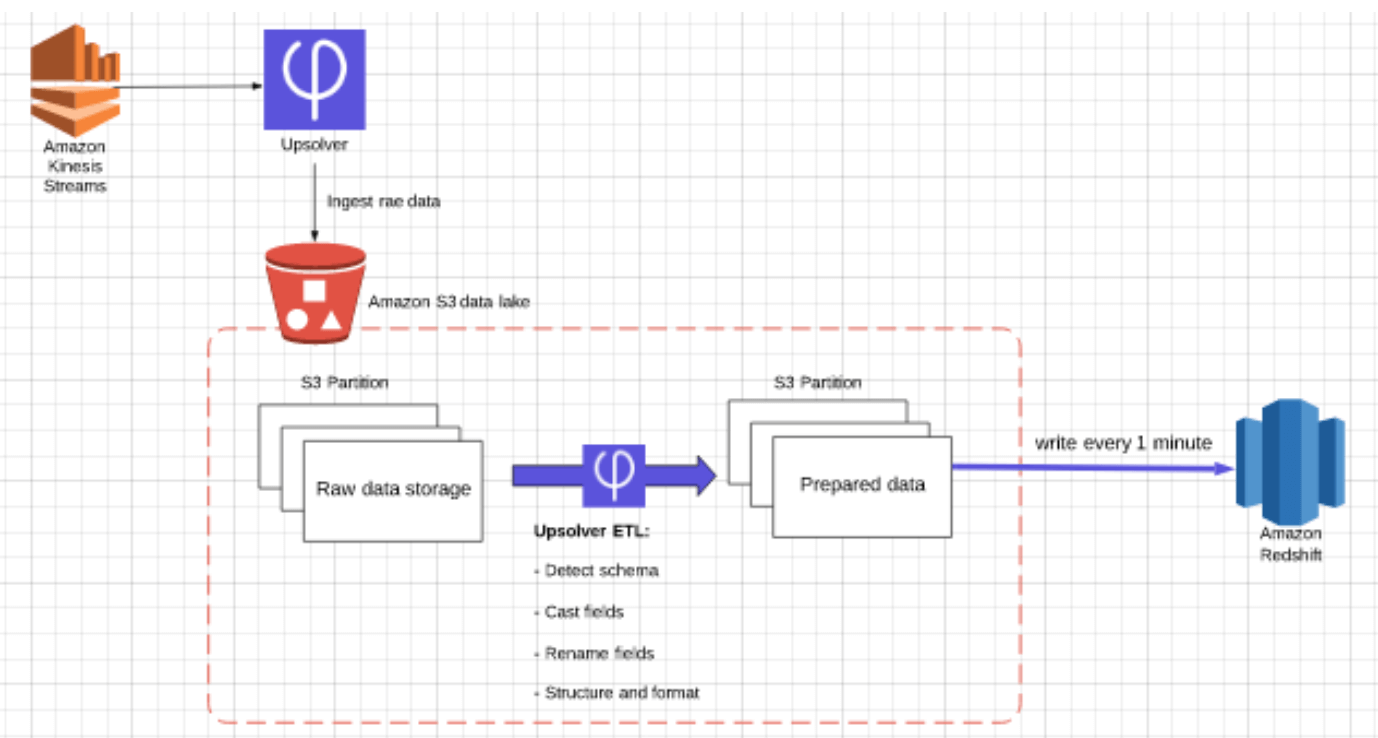
- Transforms data on your data lake.
- Uses Spot instances for 90%+ savings vs. a cloud data warehouse.
- Employs incremental ETL techniques to minimize the processing required for continuous data.
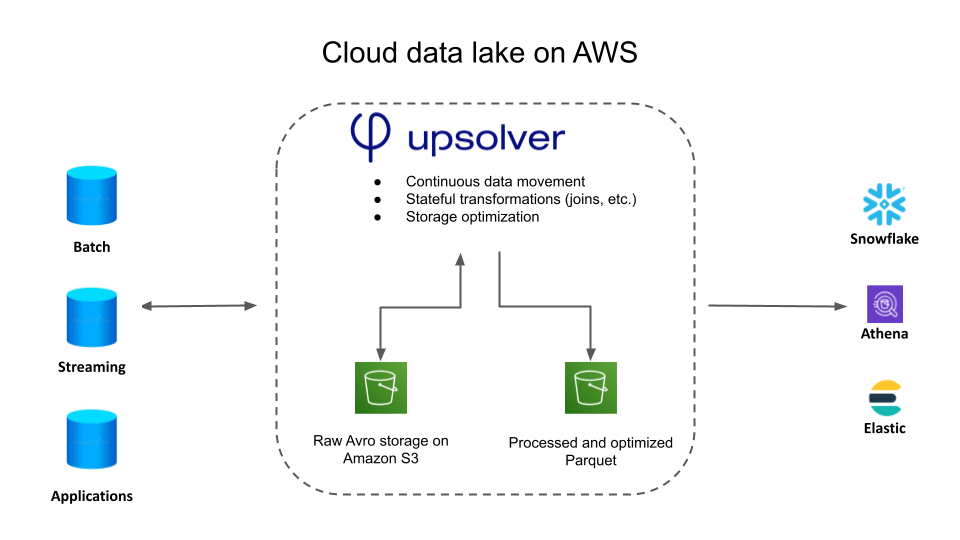
Stateful Transformations at Scale
- Combine streaming, fast batch and historical batch data.
- Continually run aggregations, joins, window functions and more.
- Upsolver is in high-throughput production at 100,000s events/second.

SQL Simplicity and Pipeline Automation Liberates Data Engineers
No need to hand code ingestion as Upsolver comes with connectors for a variety of data source types:
- The Upsolver IDE lets you connect data sources, profile incoming data, and preview, run and monitor pipelines visually.
- Write transformations in SQL - allow any practitioner to build pipelines.
- Pipeline engineering is eliminated - Upsolver automates file/table management, ingestion and orchestration.
- You can focus scarce data engineering resources on higher value work.

Deliver Query-ready “Live” Tables to your Data Warehouse
- Delivers and updates processed target tables in your data warehouse using pre-built connectors - Redshift, Synapse and Snowflake are all supported.
- Keeps output tables up-to-date via automated UPSERTs.
- Raw data remains available in cloud object storage for time travel to a previous state, replay and reprocessing.








Explore Upsolver your way
Try SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience.
Talk to a Solutions Architect
Schedule a quick, no-strings-attached with one of our cloud architecture gurus.
Customer Stories
See how the world’s most data-intensive companies use Upsolver to analyze petabytes of data.
Integrations and Connectors
See which data sources and outputs Upsolver supports natively.