
Explore our expert-made templates & start with the right one for you.
Real-time Machine Learning: Hype vs Reality
-
 Eran Levy
Eran Levy
- Cloud Architecture
- July 23, 2019
Want to spend more time on feature engineering instead of data engineering? Watch our webinar recording, where Upsolver CTO Yoni Iny presented the data engineering challenges of building data infrastructure for ML, and how to overcome them. Get the recording now!
Is machine learning in your roadmap for the next two years? You’d be hard pressed to find a CTO or CDO in the tech sector who would answer this question with a definite no. The data science bandwagon leaves no man or woman behind – everyone is either doing data science right now, or thinking about doing it in the near future.
However, getting machine learning projects off the ground is often easier said than done, and this is especially true when said project includes an element of online inference with user personalization – i.e., making a prediction in real-time, which would take into account both the user’s behavior the last few seconds / minutes / hours, as well as the ‘historical’ data related to that user from the past few days / weeks / months.
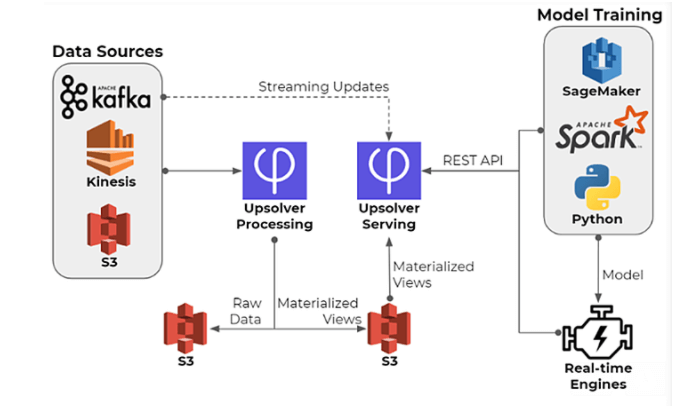
Common scenarios where we might want to combine historical and near-real time data might include:
- Recommendation systems for eCommerce – predicting which product to suggest to a user based on their past behavior in your online store, as well as the current product they are viewing
- Mobile monetization – knowing when to show an app user an ad or an offer to complete in-app purchases, based on their past purchases and current engagement
- Fraud detection – identifying fraudulent financial transactions in real-time, based on both historical and real-time signals, e.g. past purchases and current browser version
The value of these and similar endeavors seems clear – they have the potential to either save costs or increase revenue by solving problems that traditional coding would struggle to handle.
However, before jumping head-first into the deep learning deep end, there are a few realities that you must take into account – and which can often significantly delay the fruition of data science projects, or even thwart them all together. Let’s look at 3 of the major ones.
1. The main bottleneck is data engineering
An endlessly-quoted statistic states that data scientists spend 80% of their time on preparing data for analysis rather than actually… analyzing it. That saying is often inaccurate on many levels, not the least of which is that in 2019, most organizations don’t expect their data scientists to also be data pipeline experts – a task which is instead performed by big data engineering specialists.
However, the 80/20 statement does capture a certain truth, i.e. that data preparation is often the first and foremost obstacle to be overcome before a data science project can get off the ground. The need to deliver data with consistency, low-latency and accuracy, and to enable flexibility in manipulating the data for feature engineering, can require thousands of expensive engineering hours, as well as dedicated hardware and software infrastructure.
2. Timelines and budgets might exceed your expectation
When it comes to real-time machine learning projects, the data preparation challenge is exacerbated by the need to build the same data infrastructure twice – once for offline model training using tools such as Spark and Flink, and another time for online inference using a NoSQL database such as Redis, Cassandra or DynamoDB. This dual architecture needs to be manually coded and constantly monitored to ensure both parts are returning identical results.
One of our clients estimated that solving this problem would require four dedicated engineers working six months. Since salaries are the largest expenditure in a software project, you can imagine what this means for the project’s total cost… And remember – all this is just to build the infrastructure so that data scientists can start testing their models on live data! Luckily, there are alternatives to Spark.
Most businesses, and especially start-ups, aren’t used to operating on these types of timelines. Launching a real-time ML project will require aligning expectation, or finding ways to shorten time to market.
3. Multiple stakeholders need to align
A As a continuation of the previous two points – for any data science project to be successful, the organization needs to understand that success is not the sole responsibility of the organization’s data science department:
- DevOps and infrastructure teams need to prioritize ML pipelines over other mission-critical tasks
- Data engineering teams are doing the heavy lifting – they need to be properly staffed and equipped with the relevant tools and technology to get the job done
- Business executives need to have patience and ensure the project continues to receive the budgetary and human resources it needs over time
Organizations that run successful data science projects are the ones where all parts of the organization are working towards that project’s success, rather than hindering it with limitations and unrealistic expectations. For the others, there’s a famous quote by Dan Ariely:
Want to learn how to do real-time machine learning right?
Check out our webinar on machine learning to discover:
- The engineering challenge of applying online inference based on live data
- Reference architectures for real-time machine learning.
- How to dramatically simplify data science projects and architectures.
- Upsolver vs alternative architectures such as Spark Streaming.
Published in:
Blog
,
Cloud Architecture
