
Explore our expert-made templates & start with the right one for you.
Joining Streams and Big Tables on S3: NoSQL vs UpSQL vs Spark
-
 Eran Levy
Eran Levy
- Use Cases
- November 13, 2019
One of the biggest challenges when working in a data lake architecture is that you’re essentially dealing with files sitting in a folder. That folder can be in the Cloud (Amazon S3, Azure Blob) or on-premises (HDFS), but the basic principle remains the same. This means you don’t have many of the familiar comforts of databases – consistent data models, SQL access and database indexes.
The lack of index can be particularly challenging when trying to perform joins. In this article we’ll see how to address this challenge within the framework of a data lake built on Amazon S3, using our own data lake indexing technology called Upsolver Lookup Tables. We’ll use the example joining between streaming and historical big data to create a unified view of a single user.
The scenario: ad click prediction
Let’s take a problem we’ve discussed before – joining impressions and clicks. We would like to predict which users are more likely to click on an online advertisement based on their past behavior. In order to do so, we want to take a click-stream from Amazon Kinesis, and to be able to enrich this stream with all the times each user that clicked has seen an ad before. Impression data is coming in from a Kafka stream and stored on Amazon S3.
Both data sources contain a ‘user_id’ field which will be our join key. We would like to create a dataset containing all the impressions associated with a particular click from the past 90 days, with the idea being that we can use this data as the basis for predicting which users are more likely to click on ads in the future, and when.
How would we go about creating our dataset?
Big joins without indexes are slow and cumbersome
If we were performing this join in a database, we could have easily created indexes to support joins. This would allow the database to quickly retrieve all the relevant values associated with the user_id key, minimizing reads and enabling the query to perform at low latency.
However, if our data is stored in a data lake – as one would typically do with large volumes of historical advertising data – there is no index. This means that finding every impression event containing a particular user_id will require a full table scan as our query engine ‘checks’ every single event for relevant values.
Full table scans are resource-intensive, expensive and slow when you’re working with big data, but are they just a fact of life in data lake architecture? Let’s proceed to look at 3 types of solutions we can choose to implement.
Solution 1: Unindexed Join Using Spark
The first way to perform this join is to accept the lack of index and run a Spark ETL job that would ‘brute force’ the join by performing a full table scan. If you only want to join the data once in order to answer an ad-hoc question, or if you’re dealing with relatively small volumes of data, this could be satisfactory.
However, problems begin when you need to perform this join on a regular basis, such as in order to feed a specific analytics dashboard or machine learning model, while the underlying data changes or grows. Since data needs to be loaded into RAM to perform the join (as it is a stateful operation), and RAM is a limited and expensive resource, the ETL developer needs to either constantly resize the EC2 instance to ensure the dataset stays available, continuously partition the data on S3, or both.
The need to monitor servers and Spark code creates overhead and leads to a fragile solution that can easily break due to memory limitations or a wrong partitioning strategy.
Solution 2: Using a NoSQL Database
The most common way to bypass the lack of indexes is to use a NoSQL database such as Cassandra, Redis or DynamoDB as a key-value store for stateful operations. You would perform the join using this database and then write the dataset back to your lake. Here’s what this type of architecture would look like, taken from a post on the AWS blog:
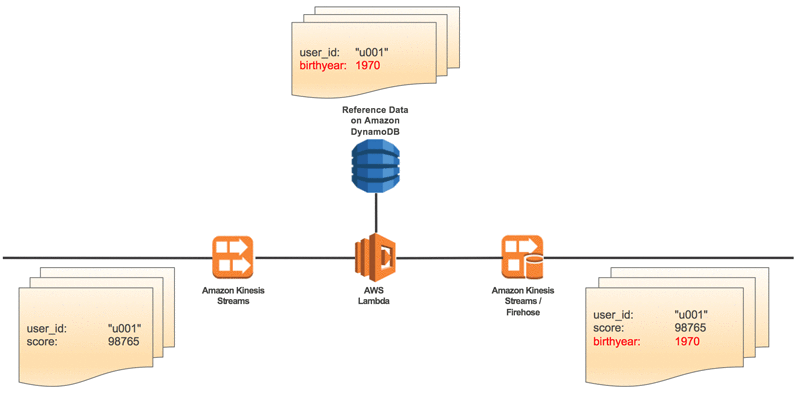
While NoSQL databases will get the job done and are built for low-latency performance, this is by no means an easy or plug-and-play solution. Expect to invest a lot of engineering time – one of our customers estimated the effort involved as “6 months of work by 4 data engineers.”
The challenge stems mostly from problems that you wanted to avoid in the first place by moving to a data lake: a closely coupled architecture, complex ETL flows and schema management, and extensive DBA work – including constant cluster resizing as indexes grow. Basically you’ve got a new, IT-centric database to maintain, and it comes with all the traditional database pains that your tech team will need to deal with.
Solution 3: Using UpSQL
UpSQL is Upsolver’s SQL-based streaming and batch ETL system and provides a simpler way to join between two streams, or between streams and big tables, by bypassing the need to spin up and manage a separate NoSQL database.
Joins in UpSQL leverage Lookup Tables – data lake indexes created in SQL and stored on Amazon S3. This means you stay in a fully decoupled architecture and don’t need to manage clusters or make large investments in compute resources, but everything is as easy and familiar as a relational database:
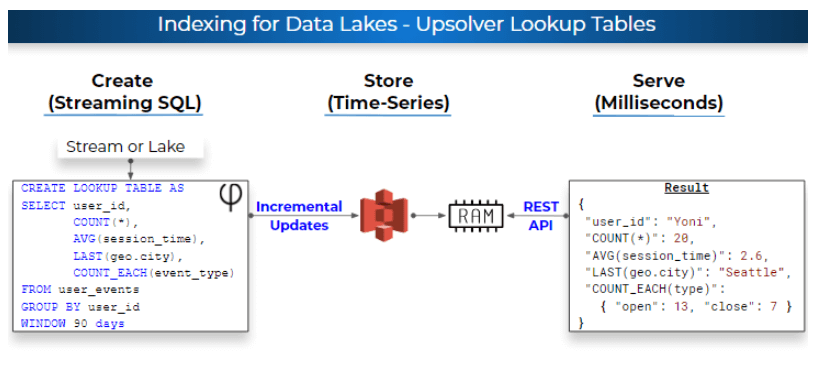
Upsolver’s breakthrough compression technology enables the platform to store compressed indexes in RAM, and to query by key while the data is still compressed, thus storing 10X-15X more data in RAM compared to alternatives. Big join with 1B keys is a non-issue.
Joining the data
Upsolver implicitly indexes the data and creates a Lookup Table, and we can then proceed to use UpSQL to create our dataset with a simple SQL JOIN statement:
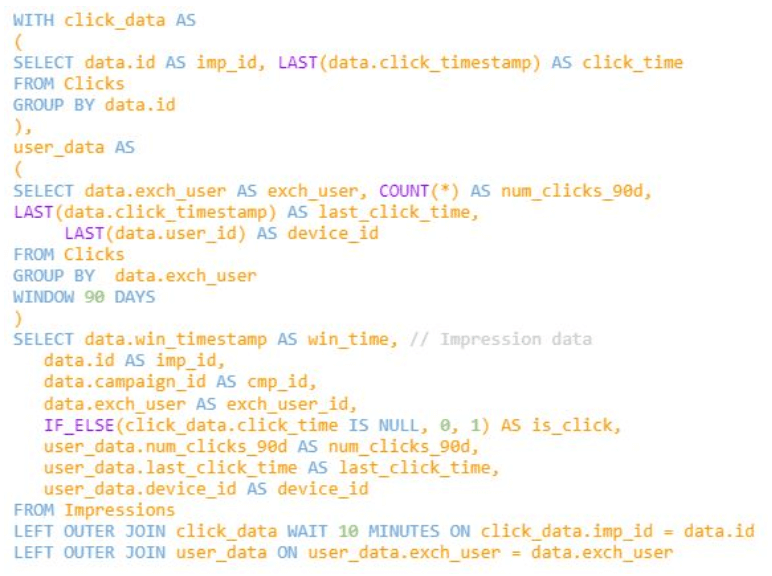
This SQL references the Lookup Table which acts as an index, allowing the operation to complete quickly and efficiently. You can read more about what’s happening in this example in our previous article on the same topic.
Once we’ve written our SQL, that’s it – it will run continuously and continue returning data even as the underlying sources change over time. It’s all done from within Upsolver, without the need for any external tools, coding or configuration.
Summary and next steps
In this article we presented the challenge of performing JOIN operations without indexes, and reviewed two alternative solutions for joining live and semi-static data stored in an AWS data lake – using Spark, a NoSQL database, or UpSQL. We presented the benefits of UpSQL for reducing friction, complexity and costs.
If you want to learn more, check out the following resources:
- Learn how Upsolver works under the hood in our technical white paper.
- Read about other alternatives to Spark by use case.
- Schedule a demo for a deeper explanation of UpSQL by one of our solution architects.