
Explore our expert-made templates & start with the right one for you.
Iceberg Performance Benchmarks: Tabular, Snowflake, AWS Glue and Upsolver Compared
-
 Jason Hall
Jason Hall
- Cloud Architecture
- June 26, 2024
Apache Iceberg is a popular open table format that makes it easy to append, update and delete data in object stores, like Amazon S3. Iceberg comes with a set of built-in functions to optimize how data is stored that reduce the size of tables and improve performance of engines querying Iceberg tables.
The Iceberg spec explains how these functions should work and the reference implementation provides code examples for developers to get started. However the actual implementation into core engines like Spark, Trino and even Snowflake is left to the engine developers. This means that even though logically all engines behave in a similar way, efficiency and performance benefits will vary. We decided to see how different engines perform in an objective benchmarking test.
What are we measuring?
Our benchmark compares the implementation of popular solutions from AWS Glue Data Catalog, Tabular (now part of Databricks), Snowflake and Upsolver.
The testing was carried out on three similarly constructed tables representing append-only and upsert workloads. Testing involved compacting and expiring snapshots as the primary way to reduce table size and improve query performance.
For each test scenario, the objective was to measure:
- Ability to efficiently compact small files into larger ones
- Query latency when scanning active partition and entire table
- The cost of optimization and storage
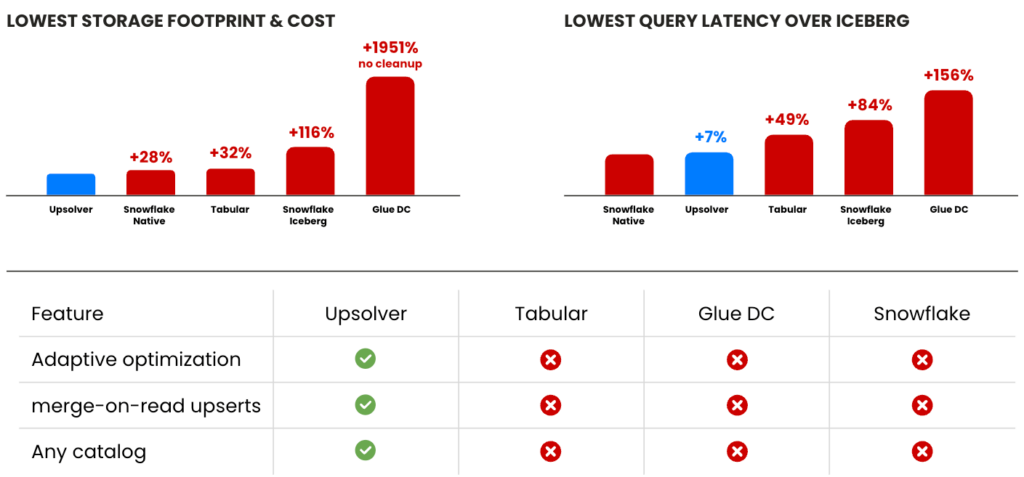
Summary of results
The following table showcases the results of our testing. We’ll get into more detail below.
What data did we use?
Unlike other benchmarks that focus on TPC-x data model and queries, we opted for an event stream that also mimics the reality of CDC streams with lots of small files and frequent changes.
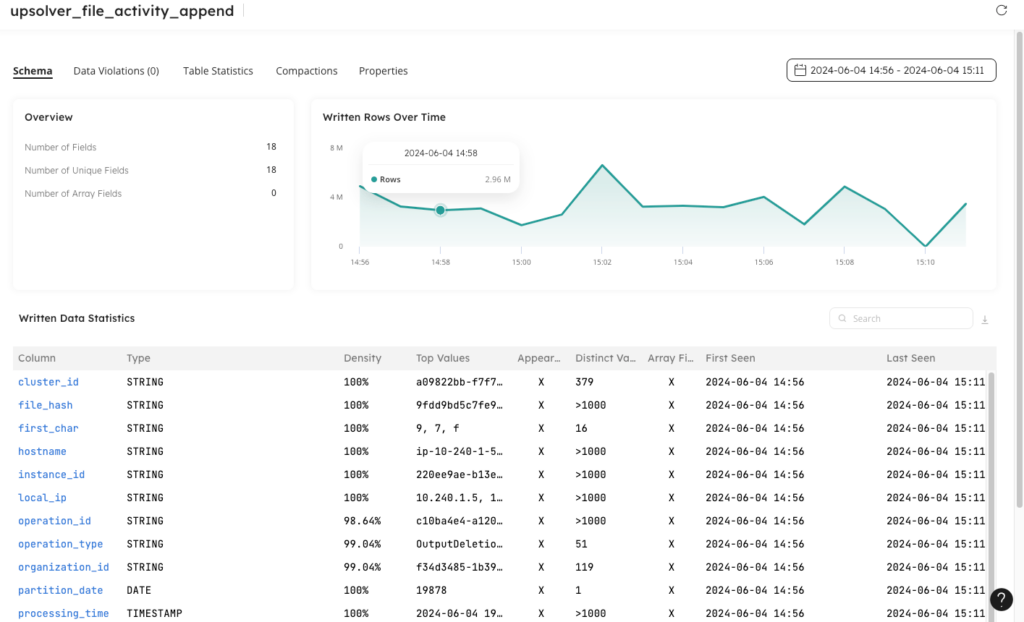
The data source used is an internal Upsolver application event stream that contains information related to file activity associated with data pipelines. Each file based operation is logged as an event, along with metadata to describe the action taken against the file.
This data was streamed into separate Iceberg tables, stored on Amazon S3, over a period of three days. Two separate use cases were tested: an append only use case, and an upsert use case.
Compaction efficiency and query performance for append-only tables
The append only table was configured with daily partitions, and sub partitions mapping to the first character of the hash of each file name. This was done to ensure large enough partitions where files could be fully compacted, with small enough partitions to demonstrate efficiency in performing partition scans. When available, the data was sorted by a string value which represented an IP address that performed a file operation.
The table contains over 5BN rows with new events written at a rate of 2-3M rows per minute.
Below is the append-only table definition:
CREATE ICEBERG TABLE default_glue_catalog.snowflake.upsolver_file_activity_compact_sorted_part_retest( local_ip STRING, partition_date DATE, first_char STRING ) PARTITION BY partition_date, first_char ORDER BY local_ip ASC;
Queries tested
A series of equivalent queries were run using Amazon Athena (v3) against each table to collect performance results. An example of each query is shown below. Queries were run that both included, and excluded the active partitions as to measure the impact that real time compaction had on query performance.
Full table scan minus the active partition:
SELECT operation_type, count(file_hash) as num_files FROM <table> WHERE partition_date < DATE ‘2024-06-05’ AND first_char = ‘0’ GROUP BY operation_type ORDER BY num_files DESC LIMIT 100;
Full table scan including the active partition:
SELECT operation_type, count(file_hash) as num_files FROM <table> GROUP BY operation_type ORDER BY num_files DESC LIMIT 100;
Full table scan filtered by the sort key:
SELECT operation_type, count(file_hash) as num_files FROM <table> WHERE local_ip = ‘xxx.xx.xx.xxx’ GROUP BY operation_type ORDER BY num_files DESC LIMIT 100;
Inactive partition scan:
SELECT operation_type, count(file_hash) as num_files FROM <table> WHERE partition_date = DATE ‘2024-06-04’ AND first_char = ‘0’ GROUP BY operation_type ORDER BY num_files DESC LIMIT 100;
Comparing Upsolver optimization with AWS Glue Data Catalog automatic compaction
Upsolver optimization and AWS Glue Data Catalog automatic compaction were both enabled on separate but similar tables. Queries were run against each table while data was actively being written. Key highlights are:
- Upsolver’s optimization cost 13x less than Glue Data Catalog compaction
- Athena queries on Upsolver optimized tables ran 30-60% faster than equivalent queries against tables optimized with Glue Data Catalog
- Glue Data Catalog did not provide a mechanism to expire snapshots or delete orphaned files, leading to 20x more data stored on S3
- Upsolver provided 2x better storage efficiency on the active table snapshot
Results for compaction and cleanup efficiency of Upsolver and AWS Glue Data Catalog:
| Storage Platform | Table Size | S3 Size | #Files | Avg File Size | Cost |
| Upsolver | 77 GB | 78 GB | 141 | 561 MB | ~$1.66 / day r6g.xl spot$4.8/day on-demand |
| *Glue DC | 144 GB | 1,600 GB | 326 | 452 MB | $23 / single 4hr run w/ 12 DPUs |
*Note (updated July 17 2024): in the original test we found a bug in Glue Data Catalog compaction that resulted in high compute costs. AWS fixed the bug on July 3rd and the numbers shown in the table represent the results after retesting.
As the following query result graphs show, querying the Upsolver optimized tables with Amazon Athena (v3) yields faster queries 30-60% of the time. In particular, including a sort column for the Upsolver managed table results in better compression and faster read performance as demonstrated by the third graph – Table scan, filter by sort key.
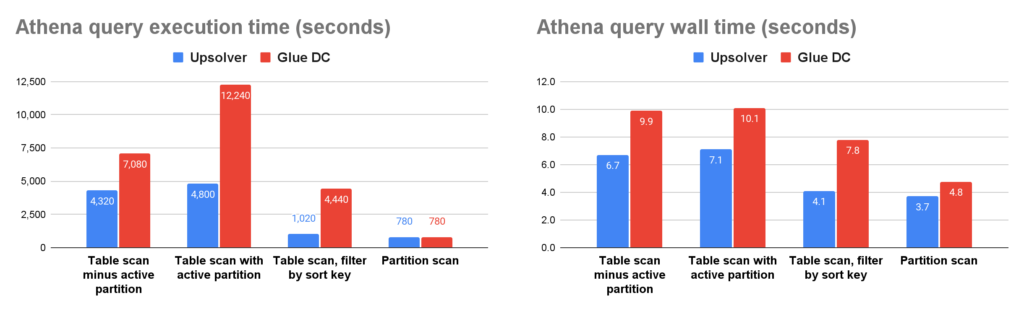
Note that most of the performance improvements are noticeable with the active partition. The active partition is typically the most recent 1 hour of data and is continuously being updated from the source. Older partitions are already optimized and aren’t modified frequently leading to slightly lower performance improvements, but still meaningful.
Comparing Upsolver optimization with Tabular table services
Upsolver optimization and Tabular compaction were enabled on separate tables to avoid conflicts. Test queries were run against each table while data was actively being written to simulate the real world. Key highlights are:
- Upsolver’s continuous optimization provided greater consistency in query performance and storage efficiency.
- Tabular’s compaction takes place, on average, every 2-3 hours. For continuous workloads, like CDC, query performance and storage efficiency were highly dependent on when the compaction triggered and how long it took to complete.
- Athena queries were 25% faster for active partitions managed by Upsolver.
Results for compaction and cleanup efficiency of Upsolver and Tabular:
| Storage Platform | Table Size | S3 Size | #Files | Avg File Size |
| Upsolver | 77 GB | 78 GB | 141 | 561 MB |
| Tabular (before) | 87 GB | 103 GB | 1206 | 74 MB |
| Tabular (after) | 87 GB | 275 GB | 415 | 438 MB |
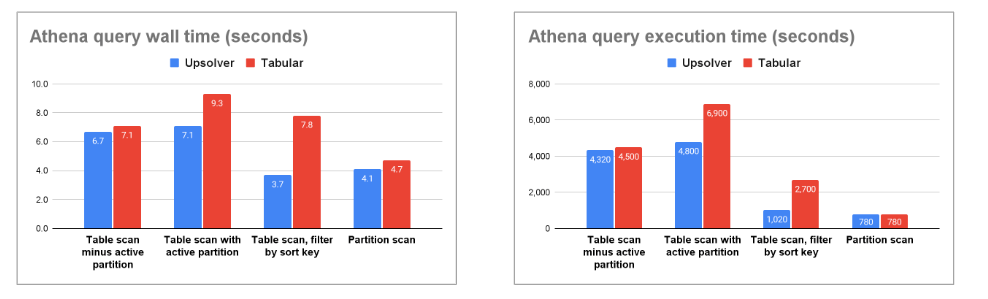
Note that the results list Tabular before compaction and after compaction. Before compaction, the Iceberg table is less optimal with significantly more files and far smaller average file size – not ideal. This remains for at least 2-3 hours before the compaction triggers. Furthermore, expiring snapshots and deleting orphan files only happens once a day, leading to a larger table size (275GB vs. 78GB). After the compaction, the table is far more optimal and comparable to ones managed by Upsolver. However, this behavior results in inconsistent and often poor performance for analytics users working with most recent, fresh data.
This behavior is represented as a sawtooth pattern, graph on the left, compared to frequent and more consistent compaction, Upsolver, as shown by the graph on the right.

The behavior is further evident in the following Athena query execution and total run time graphs. You can see Upsolver managed Iceberg tables with continuous compaction result in 1.3X shorter wall time and 1.4X shorter execution time (query planning and data scan) when querying active partitions.
Comparing Upsolver optimization for Snowflake unmanaged Iceberg tables and Snowflake native tables
In their messaging, Snowflake claims that externally and internally managed Iceberg tables rival the query performance of their own native storage format. This is shown in the graph below from Unifying Iceberg Tables on Snowflake. So we wanted to test this out.
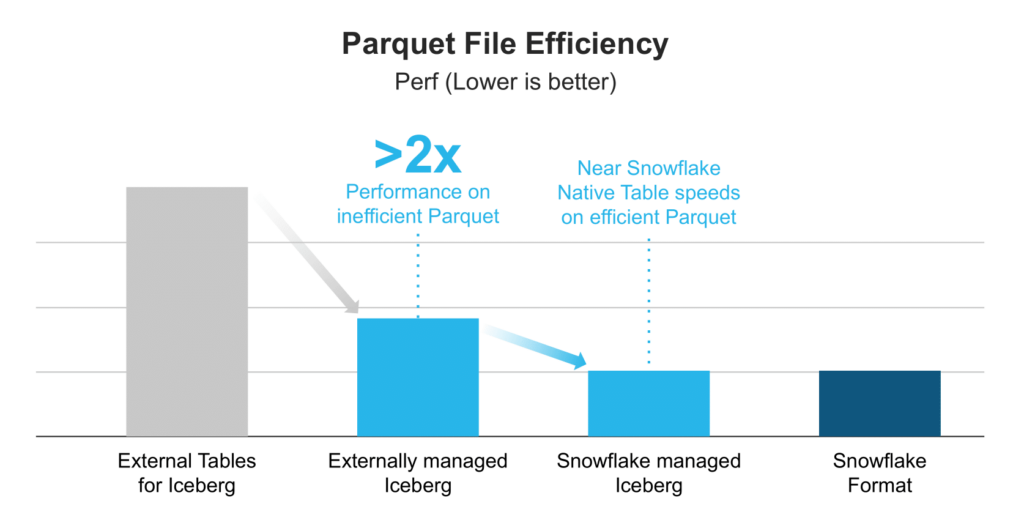
To test this, we create a Snowflake native table (not using Iceberg) using the same data source as the other tables in earlier tests. The performance and efficiency of this native table was compared to a Snowflake External Iceberg table (optimized by Upsolver and using Glue Data Catalog), and Snowflake Managed Iceberg table (optimized by Snowflake and using Snowflake catalog) in clustered and unclustered mode.
When loading data into Snowflake Managed Iceberg tables, we noticed two things:
- Snowflake did not appear to compact files following initial ingestion, as evident by file sizes remaining unchanged.
- When defining a cluster-by key, compactions did seem to occur, although the impact on file counts and sizes appeared to be insignificant.
At the time of this test, Snowflake doesn’t seem to offer a mature and complete set of optimization and cleanup capabilities. The raw data is in the table below.
Key highlights are:
- Querying the active partition of a Snowflake External Iceberg table optimized by Upsolver was on par with Snowflake native table. This is a big deal.
- Performing a full table scan on a Snowflake External Iceberg table optimized by Upsolver was only 1.1X slower than Snowflake native table.
- Querying Snowflake External Iceberg tables optimized by Upsolver was 1.8X faster (clustered) and 1.5X faster (unclustered) than Snowflake Managed Iceberg tables.
- Querying unclustered Snowflake managed Iceberg tables was 5X slower than Snowflake External Iceberg tables managed by Upsolver.
- Snowflake Native and Snowflake Managed Iceberg tables all required ~30% – 219% more storage than the same data in an external Upsolver managed table.
| Table type | Table Size | #Files | Avg File Size | Table scan | Partition scan |
| Upsolver managed Iceberg | 77 GB | 141 | 561 MB | 43 sec | 2.9 sec |
| Snowflake native | 100 GB | N/A | N/A | 39 sec | 2.8 sec |
| Snowflake managed with clustering | 169 GB | 12,843 | 13 MB | 78 sec | 4.7 sec |
| Snowflake managed without clustering | 109 GB | 11,202 | 10 MB | 67 sec | 15 sec |
Comparing Iceberg compaction efficiency and query performance for Upsert tables
Expanding on the append-only setup, we created Upsert tables. That table was defined with a primary key so that each write into the table caused an upsert. With each upsert, existing rows are deleted and then new ones inserted, resulting in the creation of Iceberg delete files. Upsolver generates equality deletes which are ideal for CDC and continuous data changes, instead of the more common positional deletes. More on that later.
The upsert table was configured only with daily partitions. This was done to force a large number of Iceberg delete files to be created in a single partition. Upserts were merged to this table at a rate of 200k-300k per minute. Below is the DDL for the creating the upsert table:
CREATE ICEBERG TABLE partners_glue.iceberg_external.upsolver_file_activity( file_hash STRING, partition_date DATE ) PARTITION BY partition_date PRIMARY KEY file_hash;
Understanding Iceberg deletes & their impact on performance
Before diving into the upsert test result, it’s important to understand how Iceberg manages deleted rows. Iceberg supports two types of delete files – position and equality.
Position delete files include rows, each containing the file path + name and the position of the row to be deleted within that file. For high volume use cases, this creates write amplification and would greatly limit the engine’s ability to keep up with the source.
Equality delete files include rows, each containing a JSON struct with one or more column names and values that identify the row to be deleted, for example {“customer_id” : 5}. Equality deletes are efficient for write-heavy workloads like streaming and CDC, but require proper Merge on Read (MoR) support for good query performance.
You can find more technical detail in Adapting Iceberg for high-scale streaming data.
Not all compaction is created equal
In our testing, Upsolver was the only solution of the four tested that could successfully optimize and compact equality delete files. Both the AWS Glue Data Catalog and Snowflake documentation explicitly stated that equality delete files were not supported in compaction, and while Tabular claimed to be able to compact equality deletes, every compaction we attempted failed.
Without proper compaction, the volume of equality delete files generated during a streaming use case, like CDC, makes the resulting table unusable. However, with Upsolver, CDC and near real-time use cases are possible.
Comparing Merge On Read performance on Upsolver managed tables and equality deletes
Since CDC and continuous data compaction is not supported by Tabular, Glue Data Catalog or Snowflake managed Iceberg tables, we decided to evaluate the performance of MoR in the Trino query engine. Prior to Trino 449, MoR was implemented in an un-optimal manner resulting in poor query performance when large numbers of delete files are present, especially equality deletes. In Trino 449 (and later), Upsolver contributed an enhancement that significantly reduced query time.
Below you can see the results of querying the fully compacted partitions (with no remaining equality delete files) and active partitions (with equality delete files).
Key highlights are:
- Even with fully compacted data, MoR enhancements result in 2.1X faster queries
- The MoR enhancements accelerated queries by 15X on fresh, uncompacted data
| Query | Athena v3 | Trino 449 |
| Table scan without active partition | 17 sec | 7.9 sec |
| Table scan with active partition | 199 sec | 13 sec |
Upsolver’s MoR enhancements were merged into Trino 449 and Presto 286. We hope these are pulled into Athena, Starburst and other compatible engines soon.
Conclusion
Apache Iceberg is an open table format and a critical component of the open data lakehouse architecture. As an open standard it offers reference implementations for managing and optimizing data that improve query performance and reduce storage costs. However, as this benchmark and testing concluded, not all solutions are created equal, even if they claim to offer the same capabilities.
Independent solutions offering table services like Upsolver can provide similar or better performance and efficiency than some closed solutions. This levels the performance and cost saving playing field offering consistent benefits to any Iceberg compatible engine – query or processing.
Get started quickly
If you want to try out Upsolver’s Adaptive Optimization on new or existing Iceberg tables, you can sign up here for free.
Published in:
Blog
,
Cloud Architecture