
Explore our expert-made templates & start with the right one for you.
Adapting Iceberg for high-scale streaming data
-
 Santona Tuli, PhD
Santona Tuli, PhD
- Upsolver News
- May 6, 2024
The thing about new technology is that no matter how awesome it is, if it doesn’t fit your use case, you’re better off not adopting it.
Apache Iceberg, and lakehouse architectures more broadly, has been gaining significant traction recently. As we exit an era of choosing between hard to manage lakes and overly expensive warehouses, Iceberg, with its low-cost scalability, openness, and portability, emerges as the best of both worlds. But are these benefits sufficiently compelling?
If your data evolves slowly and ingesting daily batches into your data store is all you have to prepare for, moving to the lakehouse is a no-brainer: it’s cheaper and more versatile than warehouses and easier to manage and query than lakes.
But what about streaming use cases? Where applications await the latest data, which arrives at undetermined cadence and volume, with sporadically evolving schema?
Neither warehouses nor lakes have been particularly suited for such use cases. We’ve always relied on a separate platform and toolkit for incorporating real- and near real-time data into end-user facing products and business decision making. Could the era of the lakehouse be any different?
In order to permanently dethrone its predecessors, in addition to melding lake and warehouse strengths, the lakehouse must unify infrastructures for batch and streaming use cases. It’s a tall order, but good news: While Apache Iceberg wasn’t originally built to handle streaming data performantly, it can certainly be adapted to do so.
We at Upsolver are no strangers to the challenges presented by high volumes of frequently changing data, having amassed a decade of experience with high-scale, streaming data systems. At Upsolver, ingestion and transformation of data in the lake are held to subminute standards to facilitate the high-scale workloads of our clients whose use cases often involve near real-time decision making in production systems. Take Unity for instance, who use Upsolver for data workflows in support of their app content monetization. Without near real-time feedback, how would creators receive adequate and timely compensation for the apps and games they create?
So when we made the decision to provide a fully-managed and optimized Iceberg lakehouse, we knew that bringing streaming-at-scale capabilities to it was non-negotiable. When your users are used to running lightning fast queries against the lake (Upsolver already provides a managed parquet-hive lake with a powerful stream processing engine), hours-long execution times in Iceberg wouldn’t cut it.
This blog tells the story of adapting the Iceberg open table format and its ecosystem to streaming use cases—a massive step forward in making lakehouse the de facto architecture for the next generation of data infrastructure.
The Problem with Streaming Data into a Data Lake
While data lakes offer affordable and flexible storage that enables you to retain any type of data, they come with challenges that are exacerbated when streaming data at scale. Although even a large number of data updates delivered as a batch to the lake is relatively easy to operationalize, when you are streaming changes and have high volume, the resulting high frequency of updates feels insurmountable. Data has to be committed performantly every minute or so in order to support near real-time use cases downstream.
Frequent updates, however, generate a lot of small files. This is problematic because small files create data access overhead that directly impacts data commit and query performances.
Performing frequent updates efficiently in a data lake is by no means easy. The community has been struggling with this since the advent of the lake architecture. The canonical approach to committing updates to a lake is Copy-on-Write (CoW), whereby the data being updated is copied and re-written to a new file including the changes. In most cases, an entire file has to be replaced to incorporate a single updated record, a process which becomes quite compute intensive for frequent updates.
(As an aside, in our parquet-hive lake offering, Upsolver solved this problem by creating a view on top of the underlying table which was to be updated frequently, and merging streaming updates with this view.)
The Iceberg approach to data updates
Fortunately, in Iceberg, the Merge-On-Read (MoR) paradigm for data updates is native, making the small files problem of frequent updates easier to tackle. With MoR, updates are written to a change log, and merged only when data is read from the lake via a query. As there’s less overhead writing to a log file than frequently creating new data files, the MoR approach outperforms CoW for streaming data use cases.
Simply choosing MoR, however, doesn’t guarantee performant streaming data updates in an Iceberg lake. Performance also depends on the change merging techniques employed at read-time. Below we explore techniques for merging data deletes to choose the most efficient one for streaming data in Iceberg.
Data Deletes
As a matter of course, every operation in the lake generates a data sequence number, which gets added to all files associated with that operation. This is how the order of events is tracked in the lake. Data files have data sequence numbers, as do change log files, including data delete files. A change, such as a delete, may be relevant to any data with a sequence number smaller than its own. Therefore, when merging, every delete file in the lake must be applied to every data file with a smaller sequence number. The data and delete files are cross-referenced to determine which records are marked for deletion. These records then are omitted from the query output.
To illustrate, here we have three updates with three data sequence numbers. The second delete file is only applied to the first data file, while the third is applied to both the first and second data files.
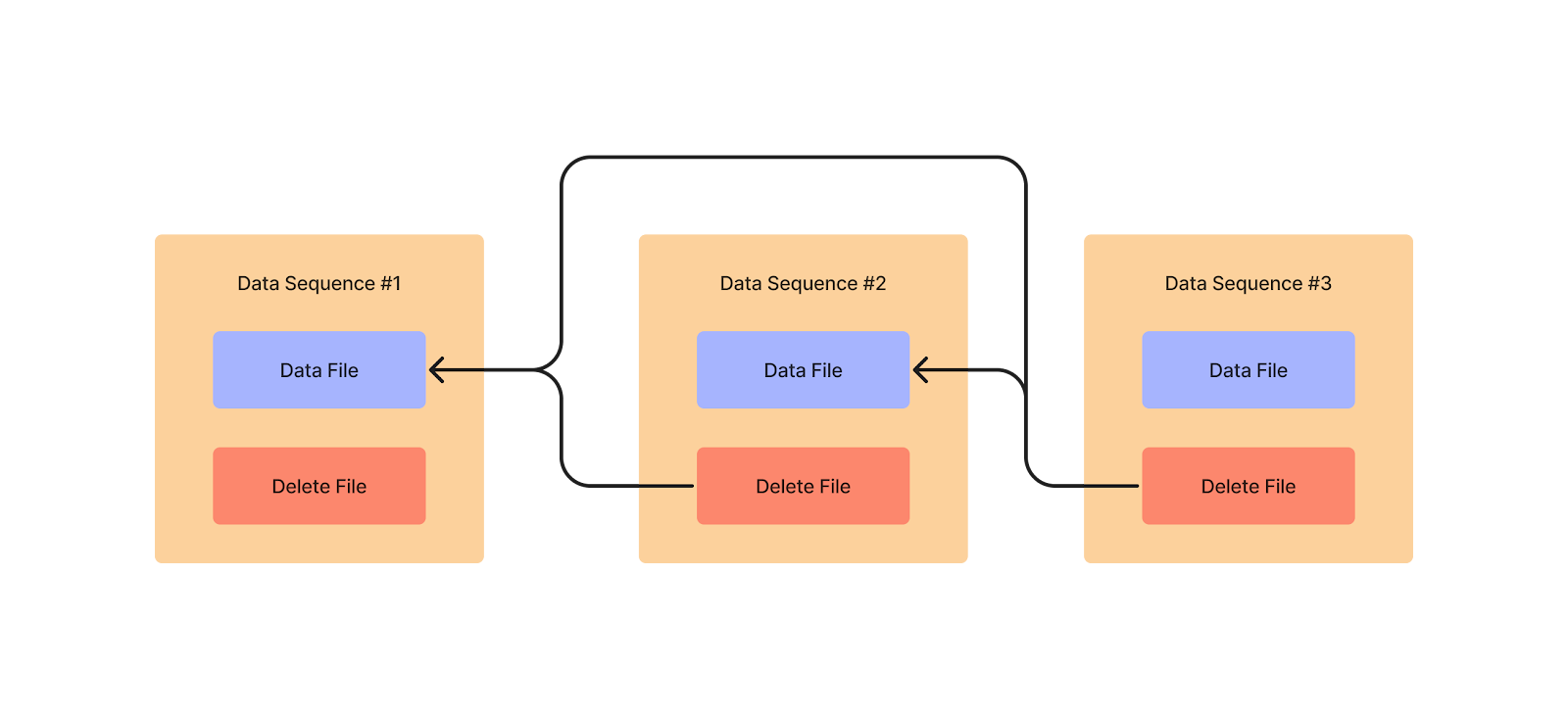
There are two options for deleting data in Iceberg: Position Deletes and Equality Deletes. While position deletes remove rows when their position matches those specified in the delete file, equality deletes match rows based on values in a set of fields known as delete fields which are included in the delete file.
Generating positional deletes for the engine to apply during MoR requires scanning the data to determine the positions of the rows to be deleted within data files in order to add these to the delete file. Thus, while the merging workload is deferred till read-time, a data scan has to be performed upfront each time a positional delete is committed. For high volume streaming data, performing such a scan on all data every time there’s an update becomes extremely inefficient.
Equality deletes are also preferable because they are in fact simple JOIN operations—or more precisely, anti-JOINs. We JOIN the data to the deletes on the equality delete fields, and if the values match, that row is deleted. By default, Upsolver performs equality deletes when updating streaming data in the lake.
Querying Iceberg Tables
Iceberg defers the responsibility of choosing merge strategies during MoR to query engines. So we must approach optimization not only from the Iceberg perspective, but also in query engines. We want to ensure query engines use equality deletes with merge-on-read for streaming updates to an Iceberg lake. Moreover, keeping in mind that frequent data updates means lots of small change files, we can also increase query performance by reading these files efficiently.
Two main open source query engines are used with Iceberg: Presto and Trino. Forked from the same codebase, these query engines share the same implementation for query planning. To begin optimizing query engines for Iceberg, let’s take a look at the anatomy of a query.
When you submit a query against your Iceberg lake, your query engine plans the query path by leveraging Iceberg’s information architecture which details how data, manifests and metadata are stored:
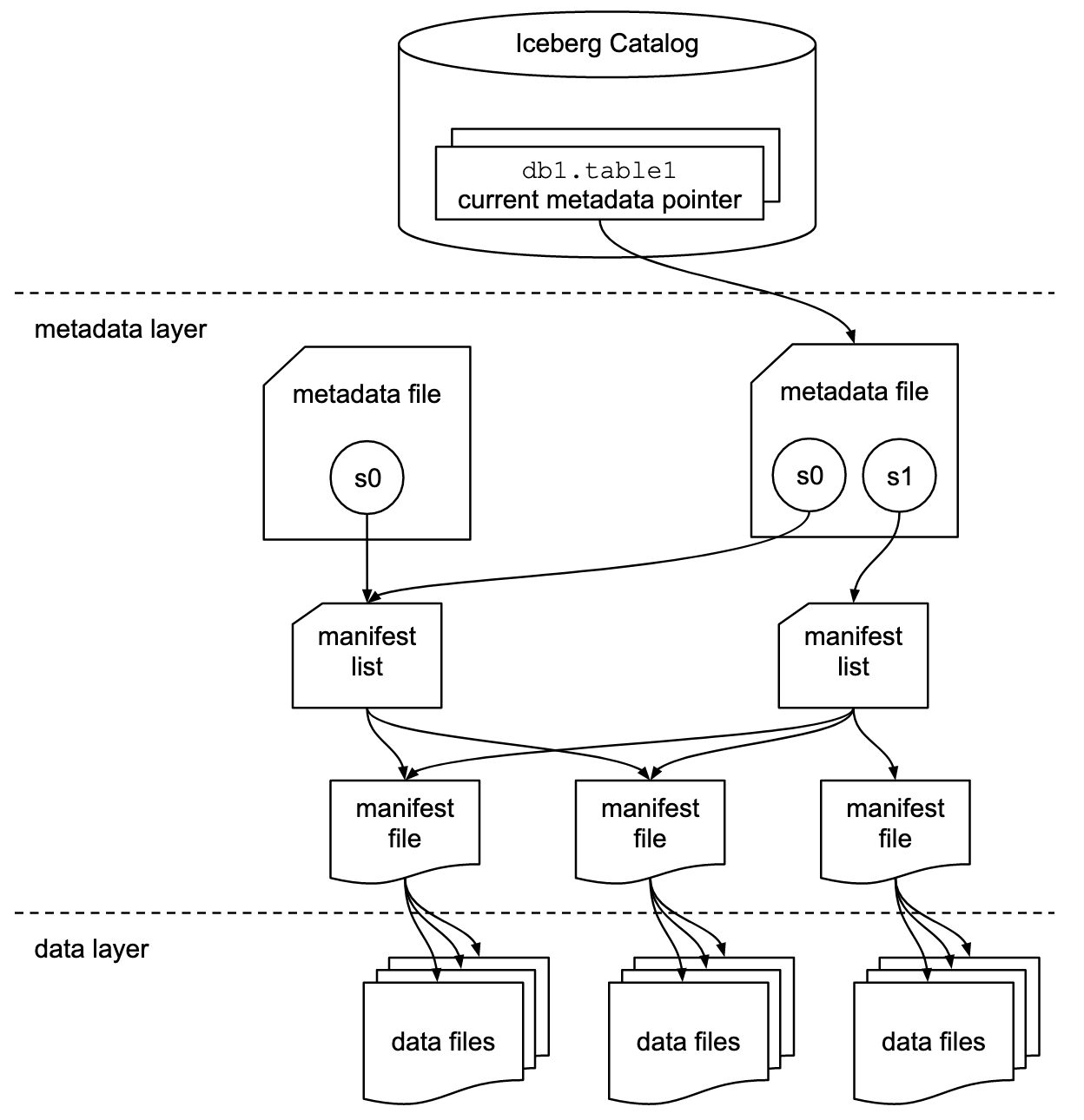
The plan returns a list of files that need to be scanned for the current snapshot of the lake. During execution, the engine navigates this prescribed path, carries out the workload, and, for MoR, merges in updates from change files.
The query plan
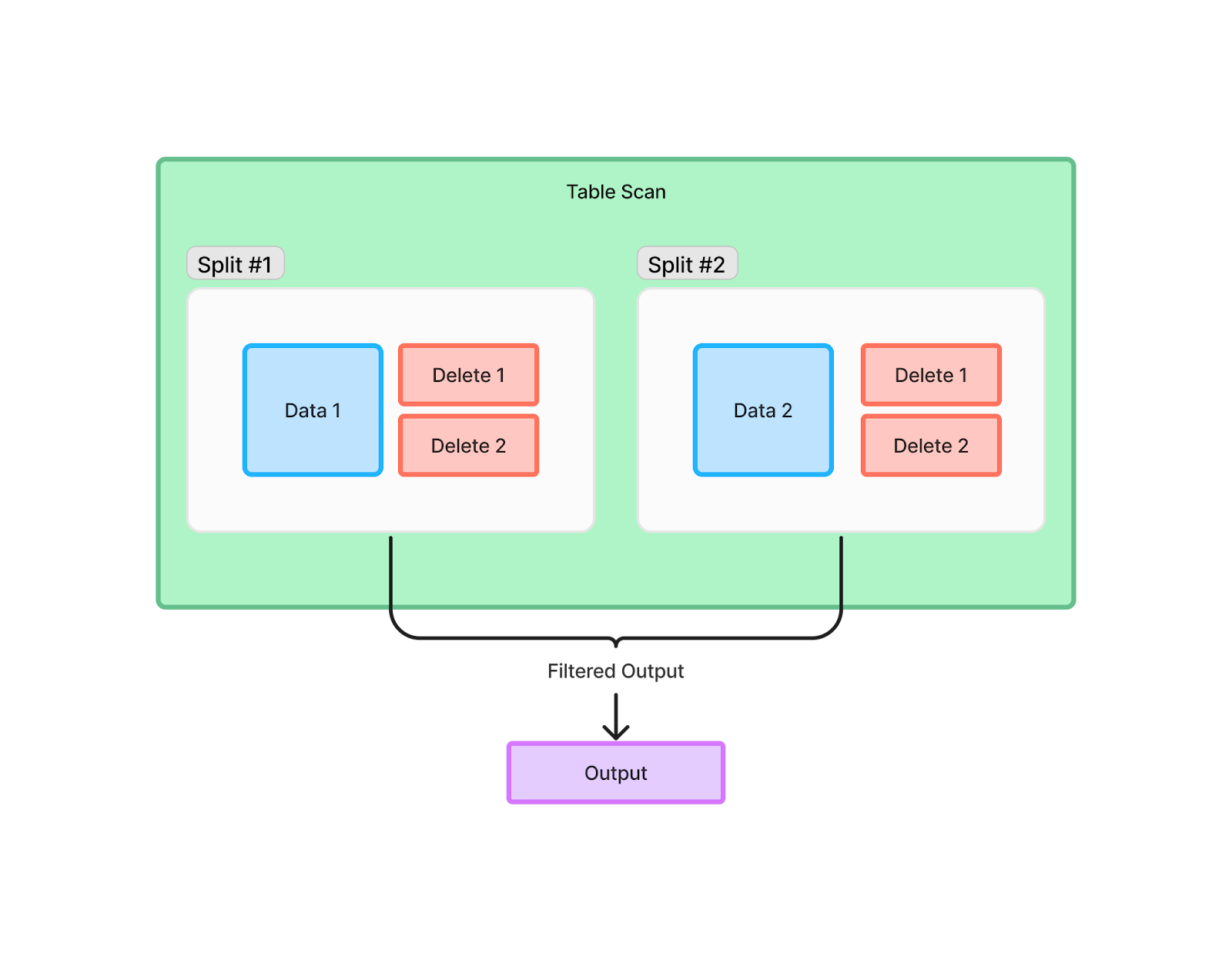
The engine distributes the query into units of work called splits. Let’s illustrate split workload distribution using the example of a query plan that involves MoR deletes from two delete files that apply to four data files.
The query engine generates a split around each data file. It then adds both delete files to each split, since either could contain deletes applicable to the split’s data.
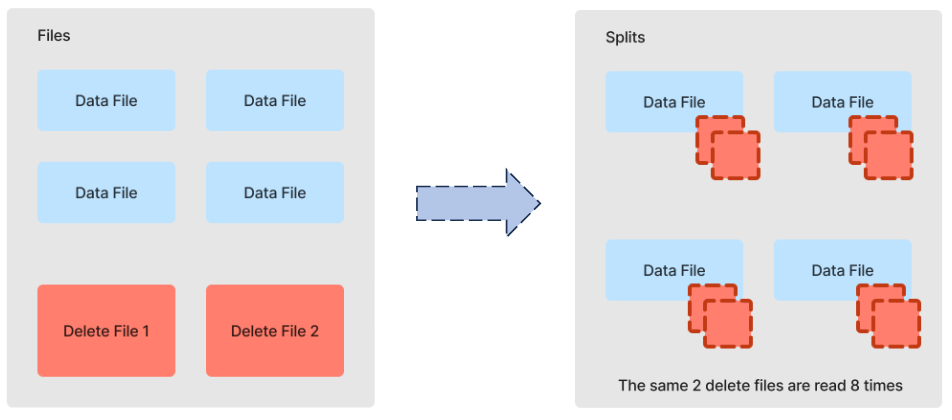
Within each split, the engine reads files, applies deletes, and emits results. The partial results from applying deletes to the four data files are then combined to obtain the final output of the query.
Since the application of deletes is carried out at the split level rather than a global level, the two delete files in this example have collectively been read eight times. Adding a third delete file results in four more file open and read operations:
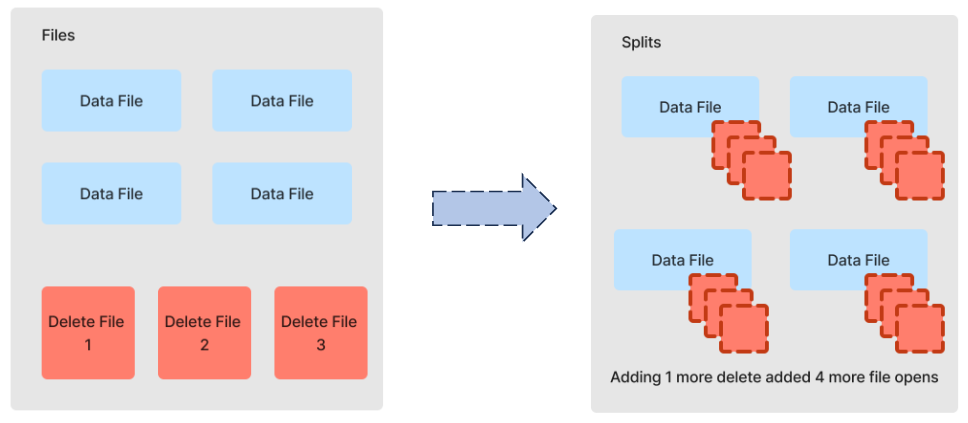
Given that in streaming use cases, most delete files apply to most data files, almost every delete file is opened in every split. If we have 1K data files and 1K delete files (not uncommon for a day’s worth of streaming updates), we end up with 1M I/O operations! The effect worsens, of course, when a single large data file is distributed across multiple splits.
Improving query performance
Knowing that there are deletes to be applied during the execution of a query, we can approach the workload distribution in a more clever way. If we separate the data and delete file table scans from each other, and from the actual application of deletes, we can read each delete file only once and apply its deletes only to the relevant data across all data files.
During delete file scans we can detect, based on the data sequence numbers, which deletes may apply to which data. Armed with this knowledge, we can JOIN only relevant equality deletes and data in a separate workload.
Mechanically, since deletes should be far fewer than rows of data, we perform a broadcast JOIN on the equality delete fields of deletes with data, while filtering out data sequence numbers that are too high. Rows with sequence numbers lower than the deletes’ without a match on the delete fields can be safely emitted to the query result.
Let’s illustrate using the two data file two delete file query execution from earlier. The naive query plan performs the deletes within the splits then combine the results:
Whereas the proposed query plan uses splits for single table scans, then performs the deletes across all data as a JOIN:
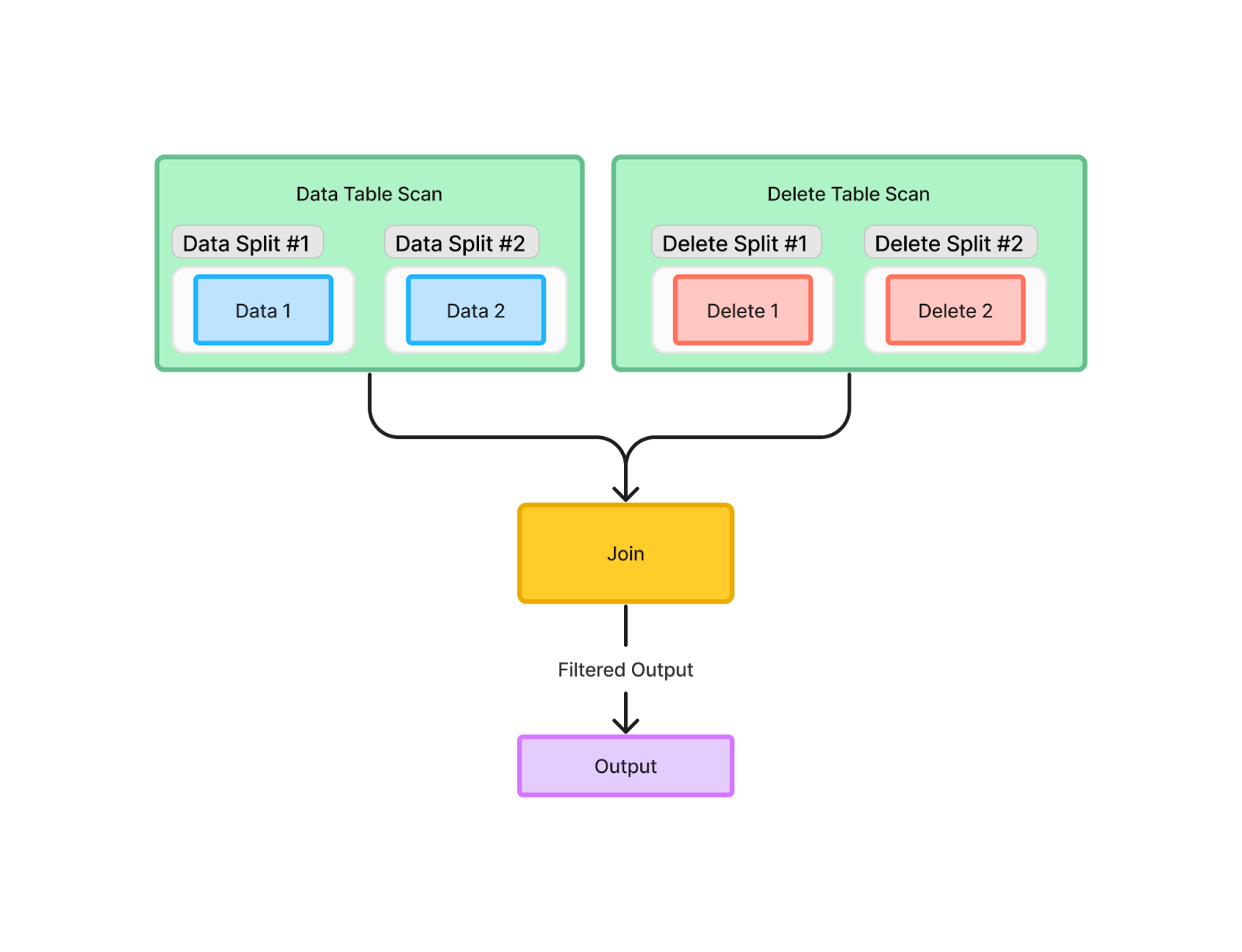
We’ve increased the number of splits, but significantly decreased the number of I/O operations. Let’s see how we can incorporate this strategy in our query engines.
Presto
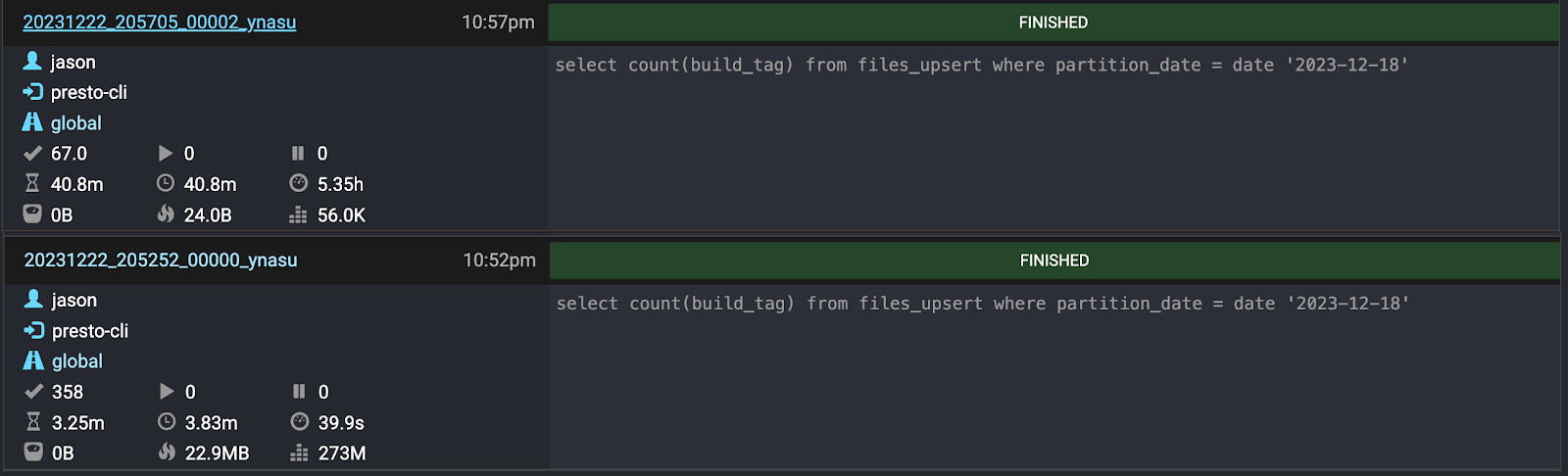
Presto allows its Iceberg connector to optimize query plans dynamically at runtime. So we implemented the method above, allowing the engine to reconfigure the queries involving MoR deletes to perform equality deletes as JOINs between the relevant data and the delete files.
The resulting performance gain for a simple query against an Iceberg partition of about 5 GB of data and 150 delete files: from five and a half hours down to 40 seconds!
Trino
The Trino story is a little different. Trino doesn’t allow external connectors to rewrite its query plan. So we tackled the problem of opening the same file multiple times not by creating scan-only splits, but by updating how splits read and share their files.
The PageSourceProvider is responsible for producing data readers within each split. Due to split isolation, the provider is unaware if the same delete file is being read elsewhere. By making the PageSourceProvider stateful, we can ensure that deletes read in any split can be shared amongst all splits in the execution node. Now each delete file needs to be read only once.
Note that since query workloads on any sizable data will be spread across multiple compute instances which are by definition isolated, some degree of read amplification is unavoidable— but that’s negligible compared to the 1M I/O operations we previously encountered.
Although the implementations for Presto and Trino are different, the effect is the same: equality delete files are read once and their deletes are applied to all relevant data, across split boundaries, drastically reducing file read operations for frequently updating data in the Iceberg lake.
What about writing frequent updates to Iceberg?
Having improved the query performance for Iceberg tables in both Presto and Trino, we need to consider optimizations to the producer side as well. This means improving the performance of writing streaming data into Iceberg tables.
The challenge of writing sequential updates concurrently
The fundamental challenge in committing streaming data is that despite being generated strictly sequentially, consecutive updates can arrive extremely close together, or even in the same payload. To preserve data integrity, updates must be applied in the correct order. Deletes, for instance, must be applied to all previous data but never to future data, or we might end up with duplicate or missing data.
Consider the example where a field, key_1, in the data receives two updates in quick succession, one at time 1, another at time 2. Suppose the committer applies both updates in the same operation, data sequence #2. Because deletes only apply to data of lower data sequence numbers, the delete at time 2 will not apply to the insert at time 1, only to the previous data from data sequence #1:
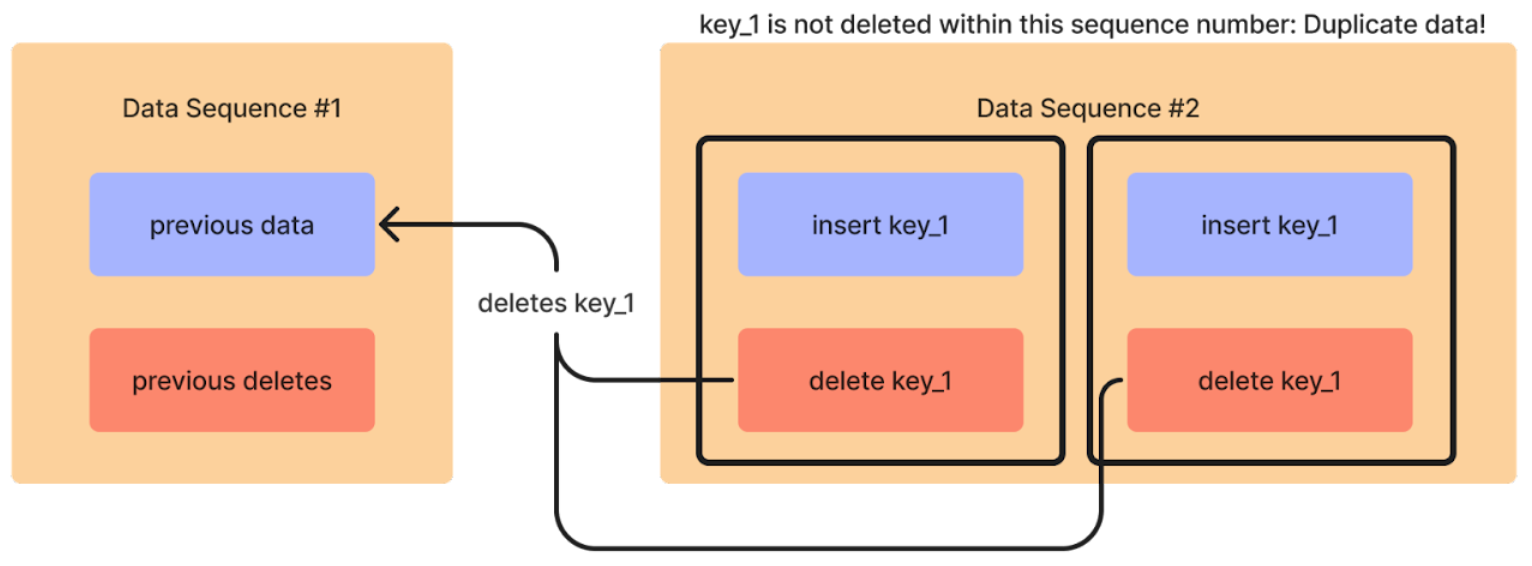
Thus, two inserts are made by the operation at data sequence #2, but only one delete. We therefore end up with two instances of the data identified by key_1, i.e. duplicate data.
To correctly merge the changes, the committer should produce two data sequence numbers, one for applying the update at time 1, and another for the one at time 2.

Here, the operation at data sequence #3 deletes the row from the insert in data sequence #2 as well as data from data sequence #1. So we obtain the desired outcome of only one copy of the data represented by key_1, which matches the insert from the latest update.
Performing updates in separate transactions, however, generates resource waste from repeating overhead tasks such as creating and writing to files. In Iceberg especially, there is a rather involved process associated with each data update.
How Iceberg manages metadata during commits
Although an update comprises an insert and a delete file only, while committing it Iceberg produces several additional files representing metadata changes. First, it creates a manifest file pointing to each file (insert and delete); then a manifest list that points to the manifest files; and finally a metadata file with a new snapshot pointing to the manifest list, manifest files, and data files:
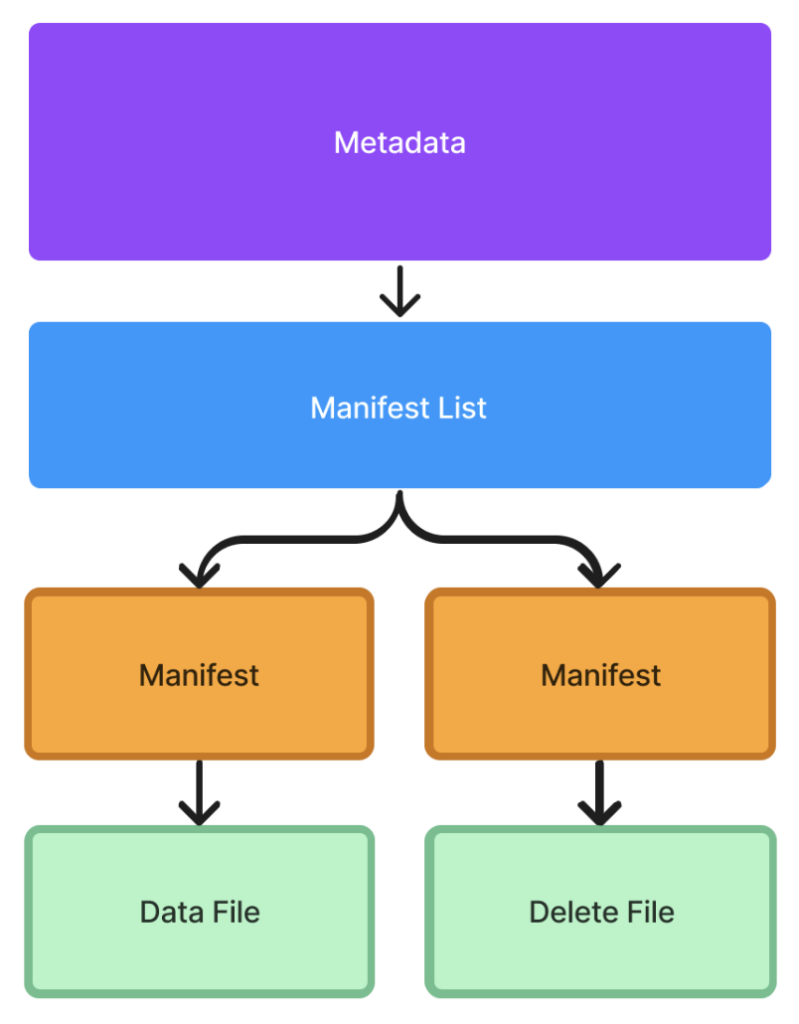
In fact, even if you commit multiple updates in a single transaction, Iceberg still produces one manifest file per insert and delete. Not only does this make data writes slow, it also leaves behind lots of small files that need to be cleaned up afterwards. As always, issues such as these are amplified when dealing with frequent updates.
Improving write performance
To make streaming data commits more performant in Iceberg, we created a Streaming Updates API, which allows you to write updates to multiple data sequence numbers in a single commit. When performed in a single operation, multiple inserts or deletes—each with its own data sequence number—can be represented in a single manifest file. Let’s explore this with an example.
Let’s apply 10 sequential updates to data in an Iceberg lake. Applying them sequentially, in separate operations, we end up with 20 new manifests—10 for the deletes, and 10 for the inserts. In testing, this process took about 24 seconds to complete.
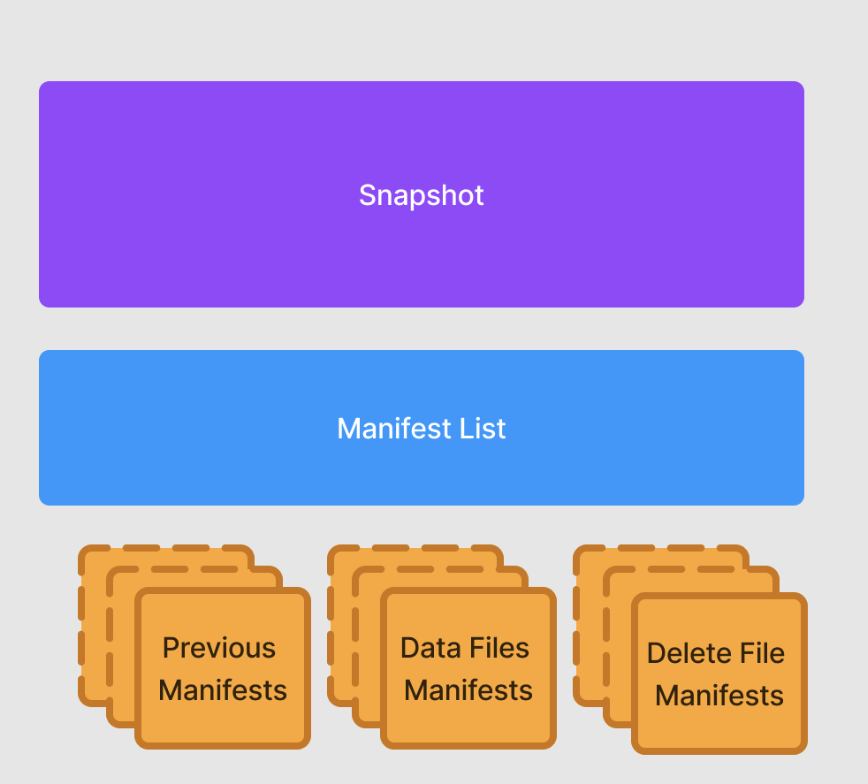
Using the API, all 10 inserts can be written into one manifest file, and all 10 deletes into another. These manifest files will contain all 10 data sequence numbers, so when applying the updates, we can be sure to delete all previous inserts to the same data and avoid the duplicate data scenario we previously discussed. The same 10 updates took only four seconds using the Streaming Data API—another commendable win!
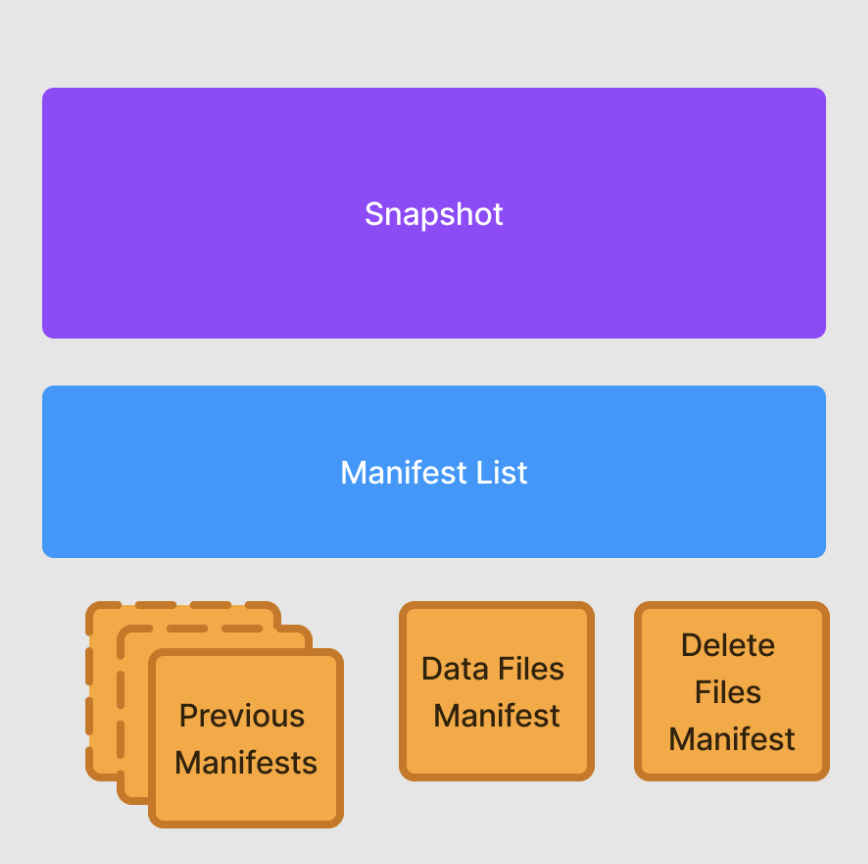
Conclusion
Adapting Iceberg to streaming data has involved several different pieces coming and working together.
- Native support for merge-on-read in Iceberg is a boon for tackling the many small files problem of frequent updates.
- Equality deletes, in contrast to positional deletes, significantly reduce file scan overhead by recasting the application of deletes to a JOIN operation.
- Query engines’ default approach to distributing execution workload results in too many I/O operations for reading deletes—but we were able to fix it.
- Presto queries can be dynamically optimized, a feature we leveraged to create dedicated splits for scanning files when MoR deletes are in order. Delete files can be read once and the output broadcast JOINed with all relevant data.
- By making the PageSourceProvider in Trino stateful, we ensured that delete files could be read once and their contents shared across splits.
- To write frequent updates performantly, we modified Iceberg’s default pattern of creating one manifest file per insert or delete. For concurrent updates, the new Streaming Updates API creates one manifest file for all inserts and one for all deletes to be applied within a commit. This is possible because we can assign different Data Sequence Numbers to updates even when many of them are committed together.
Streaming updates in the lakehouse is new, but not to us. While for the most part data infrastructure remains bifurcated along streaming and batch lines, we at Upsolver have been unifying streaming and batch pipelines for a decade. Equipped with the compaction and optimization patterns we have developed over the years, we adapted Iceberg and its ecosystem for streaming data with remarkable gains. With our improvements to the Presto, Trino and Iceberg open source projects for performantly handling streaming data, the lakehouse is well underway to becoming the de facto data infrastructure for a majority of data use cases, including near real-time ones!
Published in:
Blog
,
Upsolver News
