
Explore our expert-made templates & start with the right one for you.
How Apache Iceberg is Reshaping the Data Lake
-
Rachel Horder
- Data Lakes
- January 18, 2024
This article is based on our recent technical Iceberg webinar. Watch it for free here
Data lakes are a cost-effective solution for storing raw data, but in order to extract meaning and value, we need to track and organize the files landing in our data lake. While data lakes deliver cheap and virtually unlimited storage of any file format, this inherent flexibility brings complex problems around managing our files and data.
In this article, we will reflect on the history of storage and access to files in the data lake, and explore the reasons why Apache Iceberg has emerged as the new industry standard for managing files and accessing data.
The Problems with Storing Files in the Data Lake
In this section:
- Data lakes lack inherent organization, making it difficult to identify and access specific datasets among thousands of files.
- Updating data in lakes is problematic, often requiring entire partition updates and potentially leading to inconsistent results across partitions.
- Querying data in lakes is resource-intensive, involving reading through multiple directories and files, which can increase costs due to additional compute power needs.
- Without proper cataloging and guidance on data layout, users may inadvertently perform full table scans, negatively impacting performance.
- Data lakes provide storage but lack built-in tools for relational mapping, making it challenging to turn stored data into actionable insights without additional warehouse-like functionality.
To understand why Iceberg is creating a huge ripple in the data lake, we need to identify the problems that led to its inception. If you have worked with a traditional database or data warehouse, you will know that a “dataset”, aka a dimension or entity in data, is stored in a structured relational table, which, in most cases, the database engine can manage for us without much intervention. Nice and simple, right? In a data lake however, you may have thousands of files that collectively comprise a dataset, mixed in with numerous other files pertaining to other datasets. How do you know which files you need to access to retrieve the specific dataset you need for a given use case?
In the early days of data lakes, MapReduce emerged to help manage the data in your Hadoop cluster, but it involved writing complex JavaScript code to run operations on your files to define which files belonged to each dataset. Then Hive came along – born out of a need for Facebook to manage its massive data – and enabled data professionals to write SQL that would be translated into a MapReduce script under the hood. But we still needed a way to recognize tables: Hive took a directory-based approach, determining that all files in one folder – or directory – were part of the same dataset, and subfolders contained the partitions. In essence, a folder represented a relational table.
This provided methodical data access, because you could organize your files into partitions, such as years and months, and then query just the files in the sub folder, rather than performing a full scan. However a major disadvantage emerged when making small updates to data, whereby Hive needed to update the entire partition for one record change, making it a slow process. Applying changes across multiple partitions was also a problem, because you could update one partition, and a user could run a query before the data in the next partition had been updated, leading to inconsistent results. Furthermore, if multiple users wanted to update the same dataset in close proximity, there didn’t exist an operation to isolate and perform these updates safely.
More data, but less actionable
Querying data in the lake involves reading the list of directories, then reading the lists of files in each directory and sub folder. For a query including filters, retrieving data involves opening a file to read it, reading the data with applied filters, closing the file, then opening the next file, and so on, to find all matching results. On a large data lake, this resource-intensive process may require adding more compute power to increase performance, thereby increasing costs.
In the data warehouse, data organization and management is solved by dimensional and entity-based modeling. But the lake is meant to be a cheaper store for less processed, less structured data. In managing the lake, you still had to consider your data consumers and their ability to understand the structure of the data. This usually meant introducing additional columns such as Year or Month to enable easier querying rather than reading the timestamp of the file name to fulfill the search filter. Without proper cataloging and guidance on the data layout, it would be easy for the consumer to run a full table scan, an operation we generally want to avoid irrespective of the data storage and compute engine!
Finally, due to intentionally insufficient understanding of data in the lake, summary statistics on datasets are not precomputed. As a result, even gathering simple “table” details in the lake meant running intensive analytical queries.
In short, data lakes provided a large container to hold data, but no inherent organization or understanding of what it held or systematic way to develop the requisite relational mapping. Turning lake data actionable effectively meant adding a warehouse-like layer on top of it — without the tooling for doing so.
The Solution: A New Table Format
Iceberg introduces a new table format standard, and addresses the above points by tracking a canonical list of files rather than a directory, and bringing database-like features to the lake, including transactional concurrency, support for schema evolution, and time-travel and rollbacks through the use of snapshots. By creating an industry standard, Iceberg’s open table format allows any engine to read from, and write to, Iceberg tables, without adversely impacting one another’s operations.
Iceberg includes APIs and libraries, enabling popular tools to connect to, and interact with, its specification. It offers a query language that makes it easy for us as developers to get started without having to learn new programming languages or understand complicated data architectures – and we can easily query across differing sources and systems.
Iceberg’s Position in the Data Stack
Apache Iceberg is a layer on top of your data lake that your tools can interact with. Then, on top of the Iceberg table format, we can use AWS Glue Catalog or Hive Metastore, for example, to track our Iceberg tables. Tools such as Dremio, Hive, or Spark can query the catalog to give us that data warehouse experience on our lake, alongside analytics tools such as Power BI, Qlik, or Tableau.
What a Apache Iceberg Is Not
We should mention that Iceberg is not a storage engine, your data remains in your data lake, lakehouse, or other object store. Furthermore, it is not an execution tool, you continue to use your existing tooling to read and write data. It is a specification and standard for organizing and accessing your data on lake storage, so there’s no service to install and run.
The Benefits of Apache Iceberg
Leveraging a columnar storage format by storing data in Parquet, ORC, and AVRO formats, Apache Iceberg offers excellent performance for semi-structured and unstructured data. A huge benefit is being able to update one row, in one file, without having to update the entire partition: modifications are made at the file level, not the directory level. Furthermore, Iceberg supports snapshot isolation, so that writes are atomic.
With up-to-date metadata on the files and data, your query engine can use these statistics to plan efficient queries. The list of files is created on the write operation, enabling the query engine to use this metadata when building its query plan. Column statistics are also maintained in the manifest files, further enhancing performance benefits as they too are updated on each write operation. Data consumers no longer need to worry about the underlying structure, they can simply run a query against the name of an Iceberg table, and Iceberg knows where the files are that comprise that table.
Iceberg includes automatic compaction to reduce the number of files, thereby increasing the performance of data operations by reducing I/O. This is particularly helpful if you have streaming data, as it tends to generate a lot of small files that aren’t efficient to manage or query. Compacting these into larger files makes your queries faster.
The Iceberg Format Under the Hood
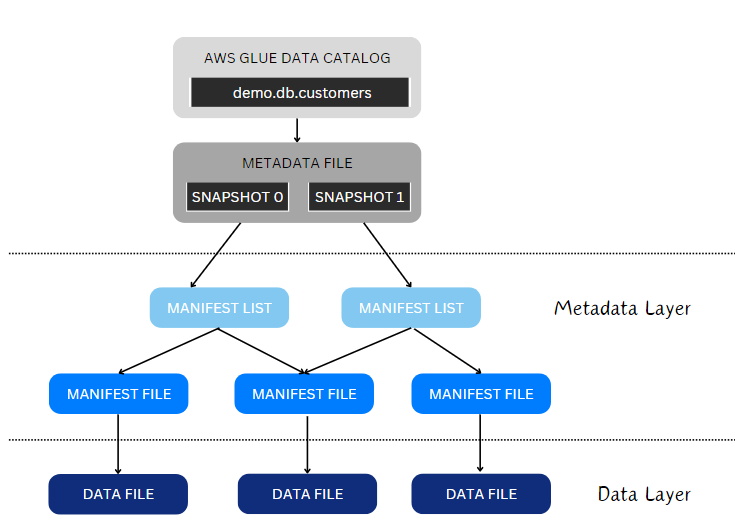
Let’s look under the hood to learn how Iceberg tracks the files in your dataset. Iceberg comprises two layers: a metadata layer, which includes the metadata files and manifest lists, and the data layer, comprising the physical files, e.g. in Parquet format.
The Metadata Layer
- Metadata File – The Metadata File has table-level information, such as the schema, configuration properties, and partition information. The metadata file is aware of the table snapshots, and can have one or more associated manifest lists.
- Manifest List – Each table snapshot in the Metadata File is described in a manifest list. This list contains snapshot level metadata, and every modification performed on your data is associated with a manifest list. Each manifest list has one or more corresponding manifest files.
- Manifest File – The Manifest File is where the data-level metadata is stored. This includes the list of files comprising the dataset, and column-level information. The manifest file can have one or more associated data files.
The Data Layer
- Data File – The data layer comprises the physical Data File(s), and is where partitioning and compaction is applied.
Copy-on-Write Versus Merge-on-Read
Iceberg has two strategies for managing updates and deletes to your data: Copy-on-Write (COW) and Merge-on-Read (MOR). Both strategies achieve snapshot isolation, meaning readers see a consistent snapshot of the data, even if modifications are ongoing. The choice between Copy-on-Write and Merge-on-Read depends on factors such as the frequency of updates, the size of the dataset, and the trade-off between read and write performance.
Copy-on-Write (COW)
This is the best strategy for tables with high-volume reads, because a file can be read without reconciling modifications with a change file (as is the approach in Merge-on-Read):
- The Copy-on-Write option is the default behavior for new tables in Iceberg.
- When a modification is made, a new version of the data file is created.
- The original data remains unchanged, and the modifications are written to a new set of files or data structures.
- This creates a copy of the dataset, allowing for isolation of reads and writes.
- The advantage of COW is that it provides a clear snapshot of the data at a specific point in time, ensuring consistency for readers.
- For example, if you update one row in a file containing 5K rows, all 5K rows are re-written into a new file. So while the write operation is somewhat slower, reads are faster.

Merge-on-Read (MOR)
If you have a lot of write operations, such as from a streaming data source, Merge-on-Read is a good option, as modifications are held separately in a change file, and reconciled (merged) on the read operation:
- With the Merge-on-Read approach, modifications are not immediately applied to the existing dataset. Instead, a separate set of modification files is maintained.
- When a read operation is performed, the system merges the original dataset with the modification files on-the-fly, providing a unified view of the data.
- This approach avoids creating complete copies of the dataset for every modification, saving storage space and reducing the cost of modifications.
- MOR is particularly useful when dealing with large datasets and frequent updates, as it minimizes the need for copying data.
- This approach can slow down the operations because the modifications need to be reconciled with the main data file; however, this is faster for writes, which is ideal for streaming data.
- When you run a compaction operation on the files, the changes are merged into the data file, and read operations will be faster.
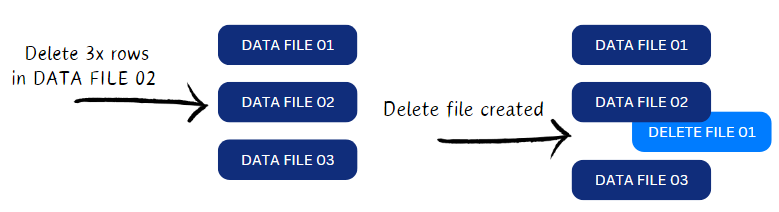
With Merge-on-Read, you can further determine how deletes are managed within the delete file. Iceberg provides two delete file formats:
- Position Delete Files – The Position Delete format distinguishes deleted rows by specifying the file and position in one or more data files. Optionally, it may include the deleted row itself. A row is considered deleted if an entry exists in the position delete file, corresponding to the file and position of the row in the data file, with indexing starting at 0.
- Equality Delete Files – Equality Delete files pinpoint deleted rows within a set of data files based on one or more column values, with the option to include additional columns from the deleted row. These files store a subset of a table’s columns and utilize the table’s field IDs.
Learn more about using the Delete File formats.
Putting this into Practice
Iceberg provides the ability to customize how each table behaves according to your use case. Using the TBLPROPERTIES setting, you can configure how row updates are applied at the granular level for deletes, updates, and merges (upserts):
CREATE TABLE demo.db.customers
(
customer_id int,
first_name string,
lastname string,
email string
)
TBLPROPERTIES
(
'write.delete.mode'='copy-on-write',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read'
)
PARTITIONED BY (customer_id);We can also use the ALTER TABLE statement to change these properties in line with how our data is used over time:
UPDATE TABLE demo.db.customers
SET TBLPROPERTIES
(
'write.delete.mode'='copy-on-write',
'write.update.mode'='copy-on-write',
'write.merge.mode'='copy-on-write'
);
Summary
Apache Iceberg addresses many of the challenges of managing files and data in a data lake, overcoming the limitations of older methods. Delivering database-like features to data lakes, Iceberg offers transactional concurrency, support for schema evolution, and time-travel capabilities. Iceberg’s benefits include leveraging columnar storage formats for excellent performance, support for modifications at the file level, and automatic compaction to enhance query efficiency.
Iceberg’s architecture, comprising metadata and data layers, uses two strategies for managing modifications, and that you use to configure table behaviors according to your specific use cases. Visit the Apache Iceberg website for further information, documentation, and videos.
>> Next step: watch our recorded webinar: Lakehouse vs. Data Lake: Ideal Use Cases and Architectural Considerations
Published in:
Blog
,
Data Lakes