
Explore our expert-made templates & start with the right one for you.
An Introduction to the Data Lakehouse for Data Warehouse Users
-
 Upsolver Team
Upsolver Team
- Cloud Architecture
- April 2, 2024
Exploring Lakehouse? Find out what it takes in our new hands-on tutorial: How to build and query your first Iceberg Lakehouse on AWS. Register and watch!
Data warehouses have long been the gold standard for data analysis and reporting. A child of the 1980s, the data warehouse concept was introduced to provide an architectural model for data flows from operational systems to decision support systems.
Although data warehouses remain very popular, especially with cloud offerings like Snowflake, they’re facing increasing competition from a new paradigm in data management known as the data lakehouse. The modern lakehouse architecture combines the key benefits of data lakes and the data warehouse. And it’s growing increasingly popular: according to a 2024 Dremio survey, 65% of organizations now run the majority of their analytics on lakehouses, with 42% having moved from a cloud data warehouse to the data lakehouse in the last year.
If you’re coming from a background in data warehouses and have found that the concept of the ‘lakehouse’ is confusing or alien, don’t fret — we’re going to dive into both concepts below and explore how they work together.
What is a Data Lakehouse?
A data lakehouse is a new type of open data management architecture that takes the fundamentals of data warehouses and combines them with the cost-efficiency, flexibility, and scalability of data lakes.
| Data warehouse – A relational database that stores integrated data from one or more sources. Data Lake — A centralized repository that can store both structured and unstructured data at any scale, using distributed storage Data lakehouse – An open data management architecture that provides a structured transactional layer over low-cost cloud object storage, enabling fast reporting and analytics directly on the data lake. |
Data lakehouses allow data teams and other users to apply structure and schema to the unstructured data that would normally be stored in a data lake. This means that data consumers can access the information they need more quickly, without adding overhead for data producers. In addition, because the data lakehouse is designed to store both structured and unstructured data, they can remove the need to manage a data warehouse and a data lake.
These attributes make data lakehouses ideal for storing big data and performing analytics operations. They also provide a rich data source for data teams to meet a broad spectrum of analytical needs, such as training machine learning models or performing advanced analytics, and serve as a source for business intelligence operations.
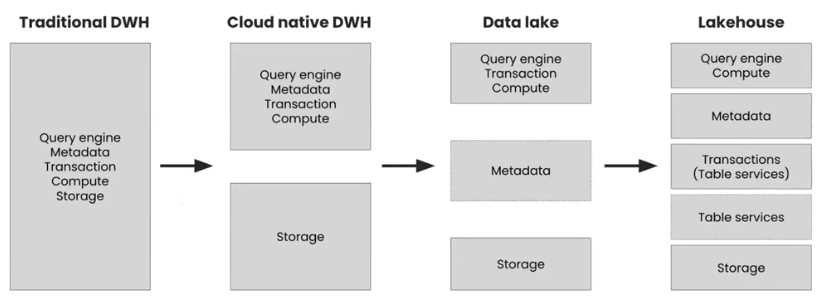
Data Lakehouse vs Data Warehouse: What’s the Difference?
The primary difference between a data lakehouse and a data warehouse is the latter’s native support for all data types. As we’ve already mentioned, data lakehouses support both structured and unstructured data by leveraging cloud object storage alongside open source formats such as Apache Parquet and Apache Iceberg. Data warehouses, in contrast, are designed for structured data and are highly optimized for performing queries on it, often relying on proprietary file formats to do so.
Although this optimization enables fast and complex queries over large datasets, it’s nowhere near flexible or scalable enough to meet the demands of advanced analytics, artificial intelligence, or machine learning applications that digest vast amounts of unstructured data and need direct access to it.
However, which of the two is most suitable for your organization boils down to your use case. A data warehouse is likely the most appropriate option if you need structured business intelligence and reporting emphasizing data quality and governance. If, on the other hand, you need the flexibility to handle a high volume of varied unstructured data types and intend to leverage advanced analytics and AI, you’ll be served better by a data lakehouse.
It’s also important to be mindful of potential cost and resource constraints. While data lakehouses can be more cost-effective for storing large data volumes, they can also require more resources for upkeep and management. This is especially true if data quality and governance are important to your use case; but it tends to cancel out when you are looking to store or process large volumes of data.
Why Choose a Data Lakehouse Over a Data Warehouse?
The data lakehouse is quickly becoming the go-to architecture for delivering analytics as dev teams move away from solely relying on data warehouses as the backbone of their infrastructure.
Rather than serving as the singular focal point of data infrastructure, diverse data warehousing tools can be used to handle specific workloads as part of a broader lakehouse architecture to deliver benefits that include:
- Democratized access to data: Data lakehouses make the data lake more accessible to users across the entire organization. This is because unlike in a data warehouse, where data is gated and can only really be utilized by engineers, a data lakehouse is an open architecture with fewer complexities.
- Fewer complexities: Following this, data lakehouses improve governance between raw and consumable data. This enables a management style in line with those seen in data warehouses that’s achievable using data lake technology and all its benefits. This makes the lakehouse suitable for regulated industries.
- Flexible schema management: Modern table formats used in data lakehouses (e.g., Iceberg—we’ll cover this shortly) allow for schema evolution and enhanced functionality when amending data in a table.
At the heart of this are open table formats such as Apache Iceberg. Iceberg represents a seismic shift in data handling, offering solutions to three critical challenges: managing expansive data sets, cost-effectiveness, and supporting diverse use cases.
Lakehouse Use Cases
The data lakehouse architecture is well-suited for a wide range of use cases across industries. Some common examples include:
1. Managing Expansive Data Sets
Data volumes are growing exponentially. This, coupled with its sheer diversity, is fast outpacing the capabilities of traditional data management systems. This is where Iceberg shines: It offers a robust framework designed to handle petabytes of data across different environments seamlessly.
This, coupled with its scalability and ability to handle incremental updates, schema evolution, and partition evolution without downtime or performance degradation, makes it ideal for dev teams that are wrangling with growing volumes of unstructured data.
2. Cost-Effectiveness
Data warehouses can become very expensive, particularly when scaling up is needed. Iceberg, on the other hand, promotes cost efficiency through storage diversification and an inherent flexibility that decouples compute and storage layers.
By doing so, Iceberg enables dev teams to utilize cost-effective storage solutions without being tethered to a single vendor’s ecosystem. This approach reduces storage costs at a time when businesses are under pressure to do more with less and allows dev teams to tailor their data infrastructure to their specific needs, optimizing both performance and cost.
3. Supporting Diverse Analytics Needs
Modern data applications are extremely versatile, necessitating data management infrastructure that can support a wide array of use cases without compromising on efficiency. From real-time analytics and machine learning models to batch processing and historical data analysis, the requirements are as diverse as they are demanding.
Iceberg’s ability to support multiple data models (such as batch, streaming, and bi-temporal queries) within the same platform simplifies the data architecture, reducing the need for multiple systems and the complexity of managing them. This makes it easier for dev teams to deploy and scale data-driven applications and ensures that data remains consistent, accessible, and secure across all use cases.
Building Hybrid Architecture with Apache Iceberg
Apache Iceberg is a new table format that can help dev teams bridge the gap between their structured data warehouses and their vast unstructured data lakes by enabling the execution of high-performance SQL queries directly on the data lake. Data warehouse leader Snowflake has already adopted it to complement its native tables and address control, cost, and ecosystem challenges faced by its customers.
One of the groundbreaking advancements introduced by Apache Iceberg is its interoperability. Although the Iceberg table format has capabilities and core functionality similar to SQL tables, the difference is that those in Iceberg are fully open and accessible, enabling multiple engines to operate off the same dataset.
Iceberg can also be used to simplify crucial data management challenges, such as managing high-velocity data streams of up to five million events per second, as was demonstrated recently in the Chill Data Summit. This highlights the platform’s scalability and adaptability to various data ingestion rates and underscores the importance of tailored optimization strategies for different use cases.
Powered by modern table formats such as Apache Iceberg, data lakehouses support structured and unstructured data to meet the demands of operations that digest vast amounts of data, such as artificial intelligence and machine learning applications. This makes it easy to manage expansive data sets and support diverse use cases while benefitting from a cost-effective storage solution that isn’t tethered to a single vendor.
Learn More About Iceberg and the Lakehouse
- Watch our free e-learning module on the data lake vs the data lakehouse, or read the ultimate guide
- Try the free Iceberg Table Analyzer – an open source tool to diagnose and optimize your Iceberg table
Published in:
Blog
,
Cloud Architecture