
Explore our expert-made templates & start with the right one for you.
Lakehouse vs. Data Lake: The Ultimate Guide
-
 Upsolver Team
Upsolver Team
- Data Lakes
- January 24, 2024
Despite the widespread adoption of data lakes and the emergence of lakehouses, there remains much confusion amongst technologists as to what each of these architectures is and precisely what they do. Upsolver’s Roy Hasson and Jason Hall recently hosted a webinar to unpack the components of each approach with the purpose of finally clarifying this ongoing muddle between data lake versus lakehouse.
This article covers the main points of the webinar so you can understand the evolution that led us to data lakes and lakehouses, and the impact of Apache Iceberg at addressing some of the existing complexities of maintaining a data lake.
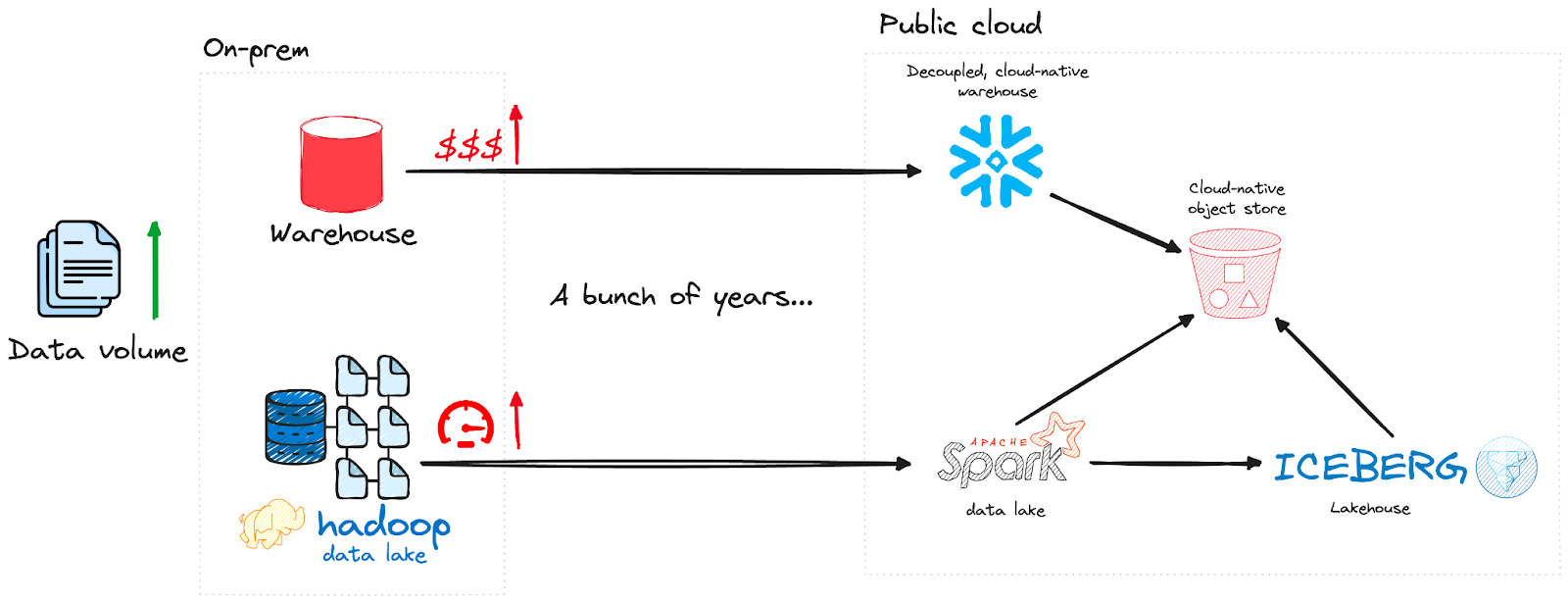
Evolution
So just how did we get to this point? You may remember the on-premise world when we stored data in an enterprise database or warehouse, such as Oracle, SQL Server, or Teradata, and hosted the database in a server room somewhere in the company building. Only a few “special” employees had access to the server room, and only a few “special” employees had access to the database. Furthermore, the data was locked into the vendor’s platform, restricting access at numerous levels.
As big data began to emerge, the Hadoop data lake surfaced to enable us to process data volumes that otherwise overpowered our traditional data warehouses – which were already difficult and costly to scale. Unlike these warehouses, Hadoop brought a fully distributed compute environment that could handle the high-volume workloads.
Fast forward a few years, and we started moving to the public cloud: Big Query, Redshift, and other warehouse vendors. This was closely followed by Snowflake, which delivered the decoupled native warehouse: the compute layer did all the processing and optimization, but the data resided in an object store. While this decoupling brought massive performance, scaling, and cost benefits, it was still a proprietary architecture, meaning you couldn’t get into your data any more than with an on-prem data warehouse.
Apache Spark also came into play, enabling us to migrate from Hadoop to the cloud, by providing a highly scalable, in-memory, distributed processing layer that could take full advantage of data in object storage.
Bringing us to the present day, we’re now very much talking about data lakehouses. While Databricks has had Delta Lake for some time, this remains proprietary, whereas the rise of the Apache Iceberg lakehouse brings us an open table format: that means no more data lock-in.
Goals
So what is the purpose of a data lake or lakehouse:
- Data lake eliminates data lock-in and makes data ubiquitously accessible from your choice of tools.
- Lakehouse extends the data lake by offering abstractions to simplify and automate the manual tasks of managing a data lake while adding warehouse-like capabilities.
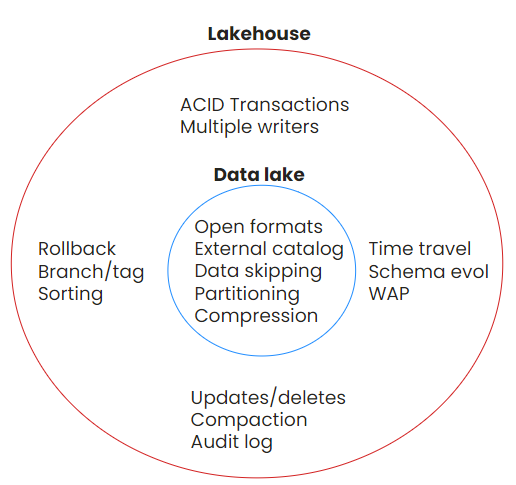
Data lakes have typically been difficult to manage, so lakehouses emerged to extend the data lake by offering a new set of abstractions to simplify and automate data management, such as compaction, sorting and partitioning data, and optimizing for queries.
Lakehouses also provide a warehouse-like experience by leveraging ACID transactions and the ability to merge and delete data. In essence, data lakes and lakehouses are not so different, and the lakehouse is an extension of the data lake.
Data Lake versus Lakehouse
What they are
A data lake is a centralized repository that allows you to store structured, semi-structured, and unstructured data at any scale, using open file formats. This data can be anything from a CSV or JSON file, through to PDFs, videos, and images.
“You can think of your data lake as your garage: you throw a bunch of stuff in there and you’ll get to something when you need it.”
As well as highly-scalable, data lakes are low cost, durable, and flexible in terms of storing types of file. You don’t need to make any decisions before you store the data.
The lakehouse extends the data lake by integrating a metadata management layer to provide warehouse-like capabilities, such as schema evolution, ACID transactions, and mutability to structured and semi-structured data. Rather than manage ACID transactions through a compute layer such as a warehouse, we extract those operations into an independent layer. By bringing the warehouse magic to this layer, you can scale and innovate faster, all while reducing costs.
What they are not
Unlike Presto and Trino – popular options for querying data in Amazon S3 – data lakes and lakehouses are not query engines: they are processing layers that leverage the data to give access to read and write it.
While both data lakes and lakehouses offer warehouse-like capabilities, they are not a data warehouse. Furthermore, we can’t think of either as a product, we can’t go buy a lakehouse, it’s an idea, a concept, a design pattern that we use to scale our data.
Use cases
There are many use cases for both the data lake and lakehouses but these are some of the most popular ones that we have come across here at Upsolver:
Data lake
- Archive raw, historical data: the data lake is a significantly cheaper option for storing historical data that you don’t frequently access rather than using a data warehouse.
- Tiered storage: data lakes can be used for tiered data storage for products such as Spark or Flink that maintain data in-memory. When data needs to be flushed, it can be stored in the lake ready for later use. Products such as Snowflake allow you to store your hot data in the warehouse, and your cooler data in S3. By retaining your heavily used data in the warehouse, this makes it more efficient and cost-effective, and you can bring in your cooler data as required.
- Unstructured data processing: data lakes are a great way of storing unstructured data such as images, videos, and PDFs.
- ML model training: training a model on the lake is usually going to be more cost-effective and efficient than pulling the data from a data warehouse.
- Cloud-storage sharing: this is a powerful model if you need to copy data between GCS and AWS to perform different tasks on each lake provider.
Lakehouse
These are similar use cases to the data lake, but which are applied to the lakehouse:
- BI, ad-hoc, interactive analytics: with the lakehouse you can run queries through dashboards, notebooks, and SQL workbenches.
- Low-cost warehouse replacement: the lakehouse provides a great alternative to a full-on data warehousing product. You can leverage a query engine tool such as Trino, Presto, Dremio, Starburst, or Amazon Athena, without buying into a data warehouse. However, you will have the warehouse experience with optimized queries, the ability to update and delete data, and managed schemas.
- Warehouse cost reduction and tiering: using the lakehouse you can move cold data into cold storage, and still query it from Redshift, BigQuery, and Snowflake.
- Database replication: lakehouses provide the semantics and abstractions to replicate CDC data into the lake as it manages merges, updates, and deletes. This is much harder to do in a data lake.
- Cross-cloud sharing: this makes it easy to write data into one cloud and have access from another.
Architecture
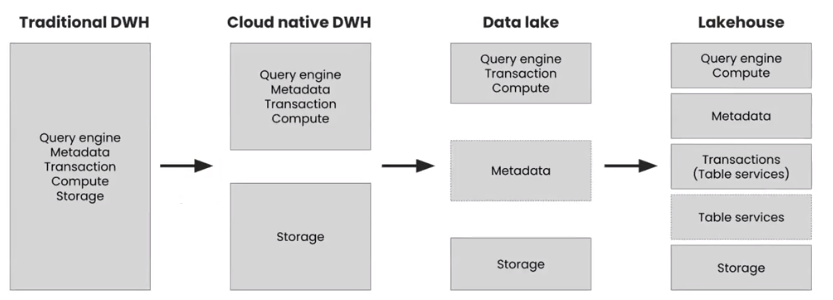
The architecture of a data warehouse has evolved through several stages. The traditional data warehouse, as we saw above, started as a single box, from a single vendor such as Oracle, and did everything for us, including managing transactions, metadata, and storage. While having a product that did everything for us made the majority of our work easy to do, the concept made it hard to scale and could break under diverse use cases.
When vendors decided to move the data warehouse to the cloud, they separated the storage from the compute layer. The cost of processing the huge volumes churned up by big data made it prohibitively expensive to do this with these layers combined. This new model enabled us to pay for cheap storage for our data, without increasing the cost of the compute layer.
Then, from the cloud native data warehouse model, the data lake emerged, this time going one step further by separating the metadata layer. This gives the ability to distribute the metadata across multiple environments, so that Presto, Trino, Spark, and Redshift, for example, can understand what datasets you have and where to find them through a decoupled catalog. Hive Metastore and AWS Glue Data Catalog exist to provide this service, instructing external query engines where to find the data.
Fast forward to the lakehouse and this separates further. One big aspect of a data warehouse is the ability to run isolated transactions to commit changes into the lake. With the data lake, that component was baked into the engine, so if the engine supported updating data in the object store, it would work, otherwise, without this support it wouldn’t. For example, if you wanted to replicate CDC data into the lake you’d often have to write your own code, which was not easy to do. However, with the lakehouse, this has evolved, and the transaction layer has now been extracted with its own APIs and abstractions, so external tools can implement transactions through this layer. This creates a welcome model of consistency across the board.
The table services layer improves on the experience of maintaining data, such as merging and compacting, both of which were challenges in the data lake. These APIs now layer on top of best practices, such as knowing the optimal size of an object to get the best performance, removing the need for us as engineers to think about.
Data Lake vs. Lakehouse: Architecture Evolution
Data Lake
In the diagram below, we can see that the storage and compute layers are separated, denoted by the red and black boxes:
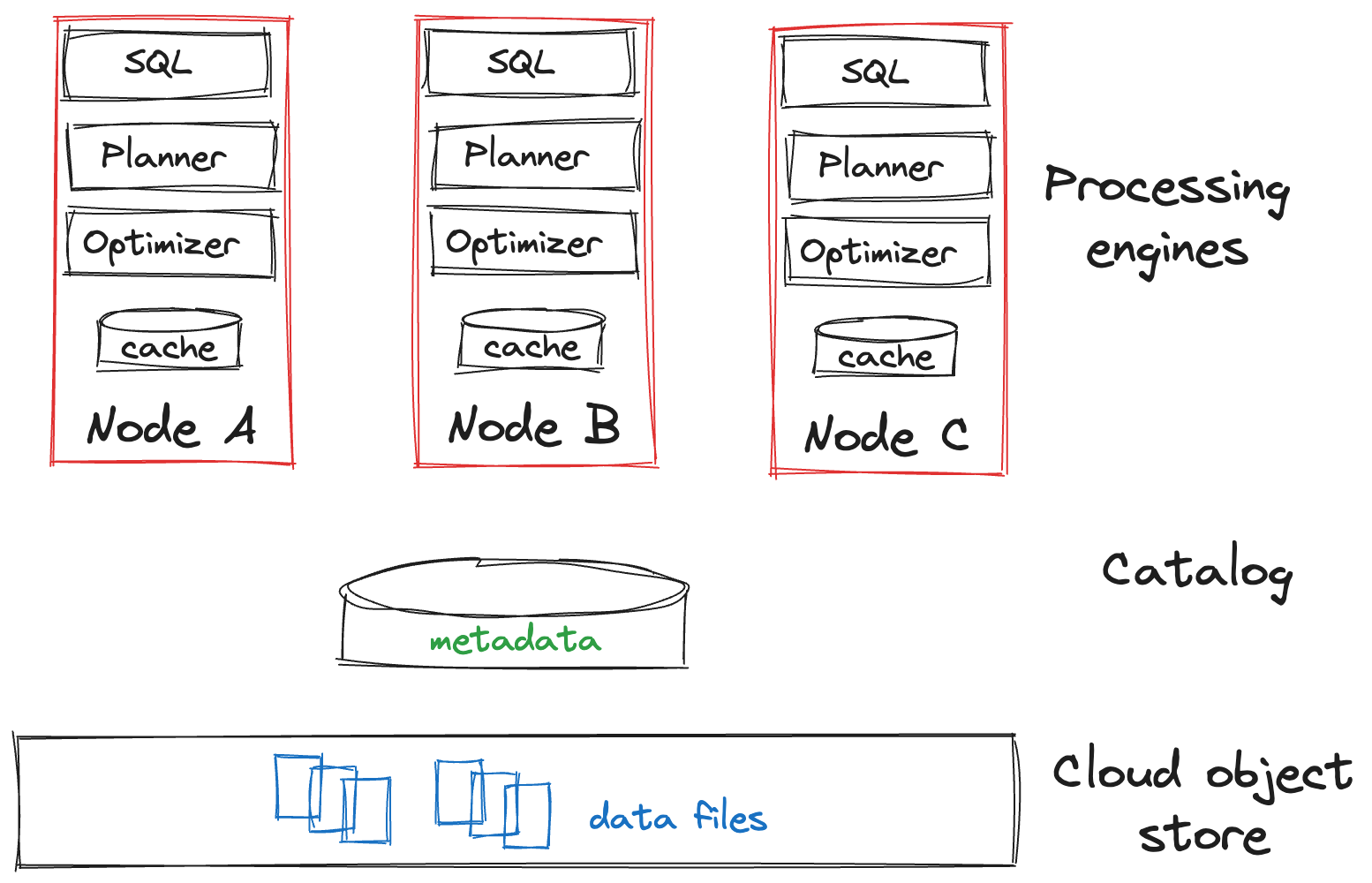
The cloud object store holds the physical files, such as CSV, JSON, or Parquet. The thin catalog layer – you can think of this a database – stores schema information, such as the names of the tables and columns, the column types, and the location of the data in the object store. The processing engine, such as Presto, Trino, Athena, or Snowflake, perform the SQL operations using the catalog to do the planning and caching, and return the results.
Lakehouse
We can see from the following diagram that the transaction layer has been split out to create another layer over and above the data lake architecture:
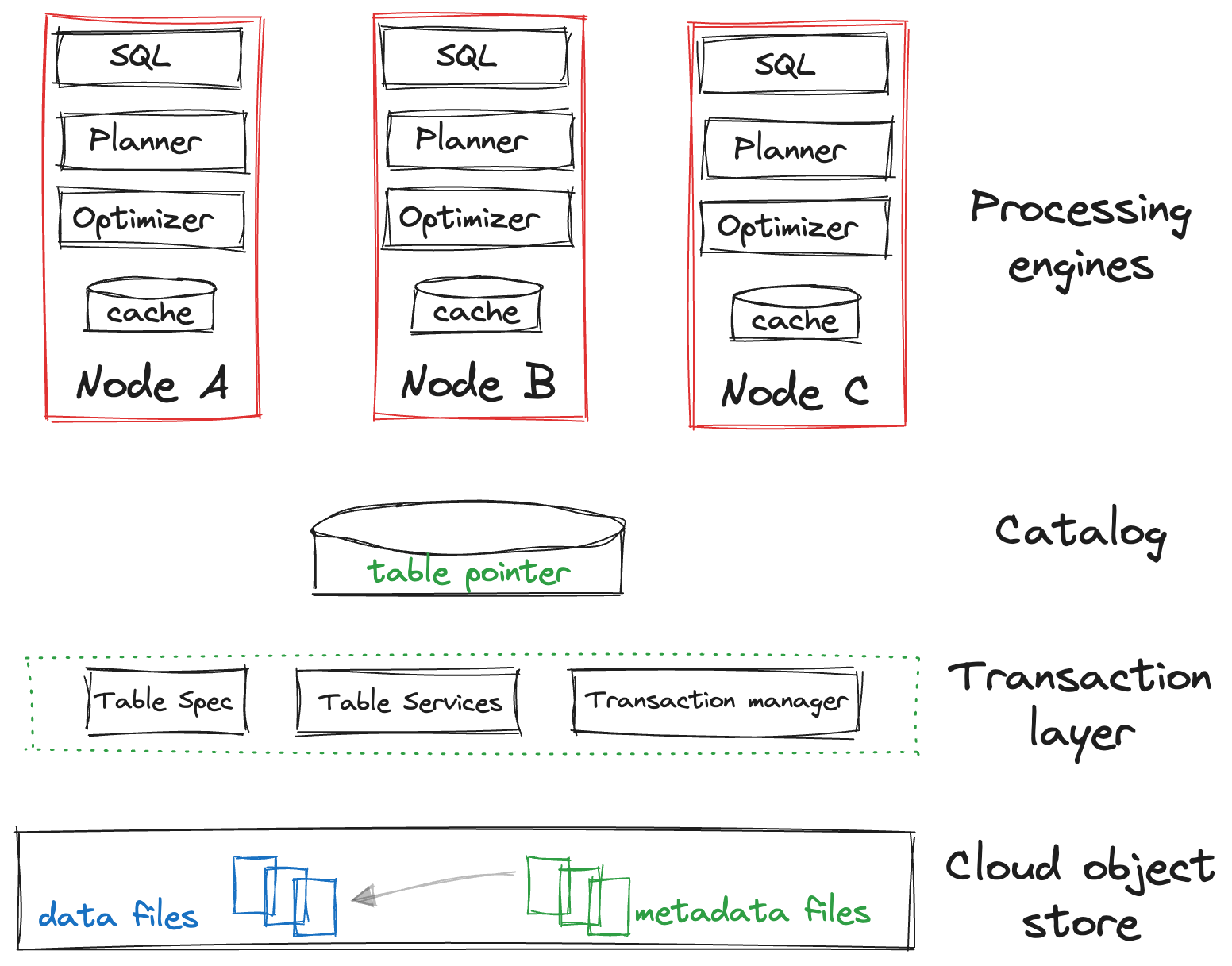
This transaction layer is implemented as part of the table format, and enables engines writing into the data to do so in a consistent manner. The transaction manager handles conflict resolution, such as two transactions trying to write simultaneously,
File vs. Table Format
File Format
You’re probably familiar with Parquet, Avro, CSV, and JSON files. The objective of these formats, particularly Parquet and Avro, is to reduce the storage size, by compressing and optimizing the data to keep costs low. The other objective is performance, to return the results as fast as possible to the user. Unsurprisingly, reducing data scans is crucial for optimal performance. Usually these files are either row or columnar format:
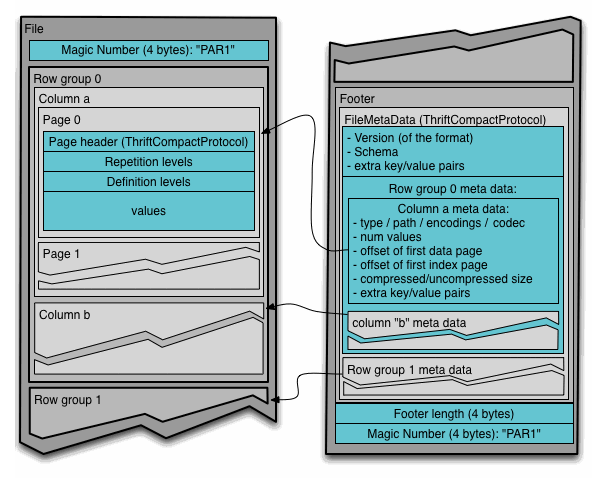
Table Format
With table formats, such as Iceberg and Hudi, these are built on top of a file format and they are definitions that determine how to manage the schema and large datasets. Their objective is to optimize schema evolution and allow you to define multiple access patterns. When access to data is held in the metadata rather than using the partition, it becomes easier to search for data based on criteria other than just by date. Iceberg brings many query planning benefits, as it stores all the metadata in a file, rather than needing to go to the physical data files. It knows how many rows exist, which files the data is in, and whether or not columns are sorted.
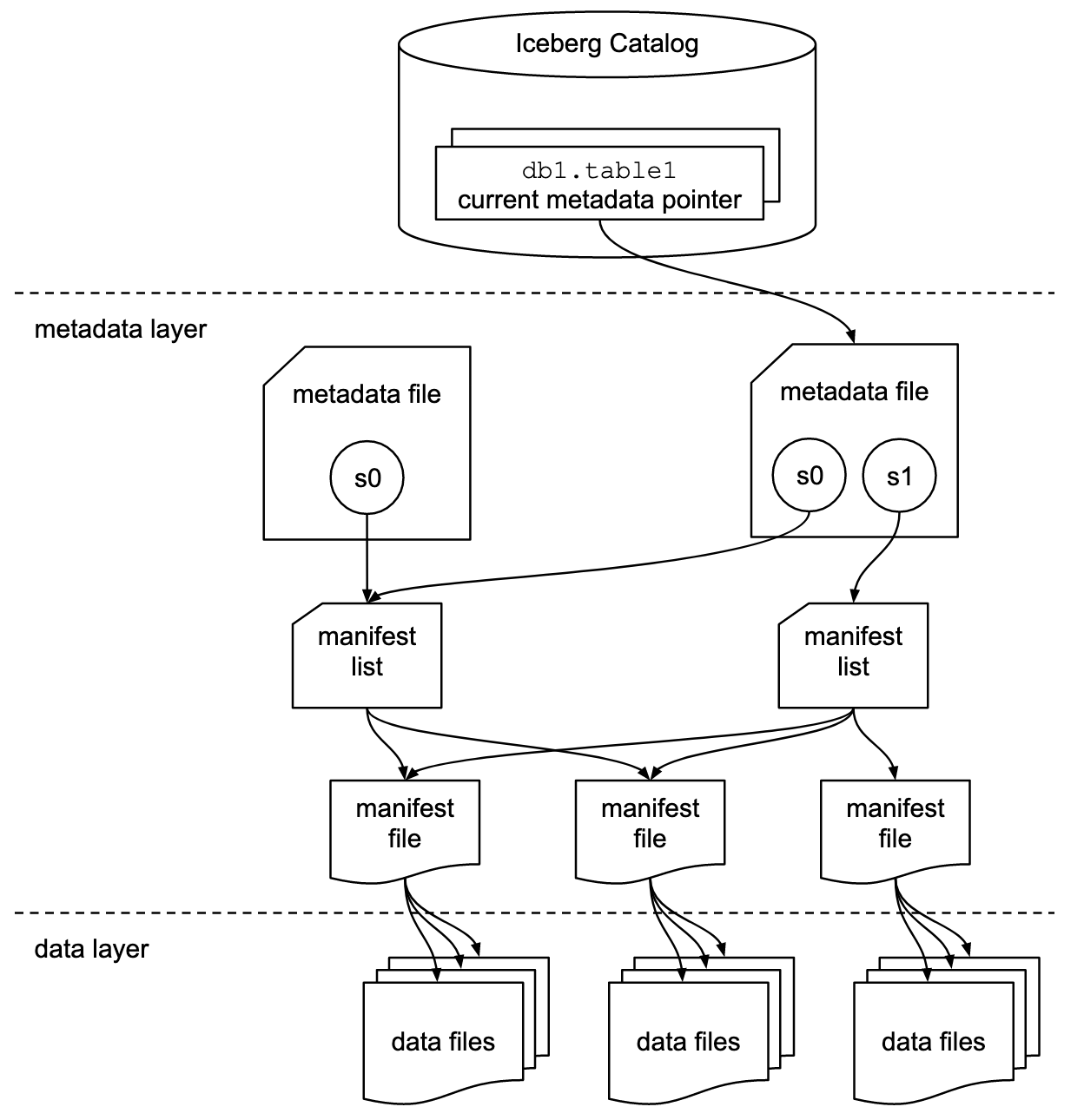
Lakehouse Transactions – Key Capabilities
The main capability of transactions is optimistic concurrency, which means if you have readers and writers accessing the same data, they will each assume their version is the most accurate. If a writer is trying to commit changes and finds that the data has since changed, it will hold off the write.
Read isolation means you are querying a committed snapshot inside of the table. With Iceberg, each time you make a change, this creates a new snapshot. All engines that query the table will look at the latest snapshot.
Writing to lakehouse tables is slightly more complex, and there are two modes: serializable or snapshot isolation:
- Serializable fails if a concurrent transaction commits a new file containing rows matching the condition used in the original transaction. This is similar to a standard database commit.
- Snapshot fails if a concurrent transaction changes the values of the snapshot.
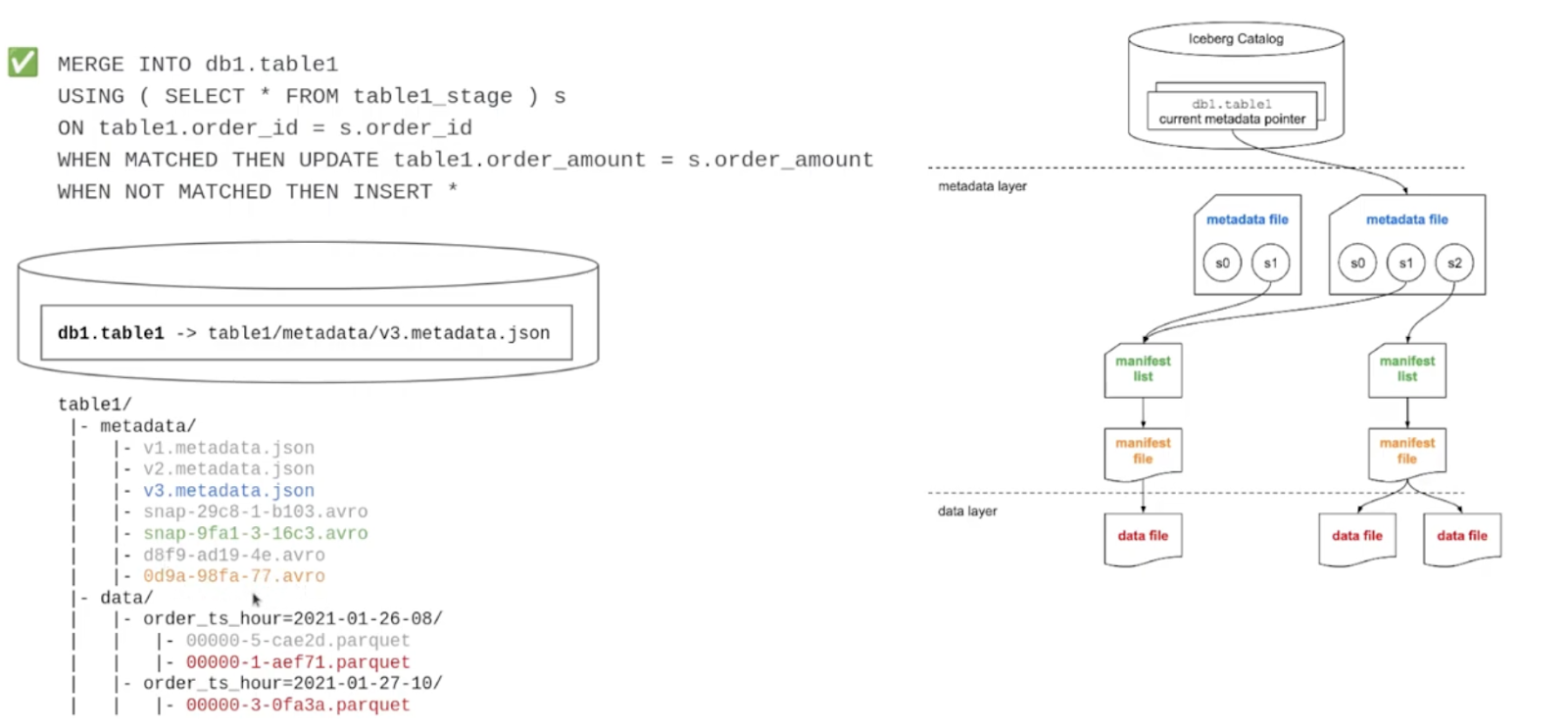
Image courtesy of: Dremio Step-by-Step Guide to Apache Iceberg Transactions | Course #5
At the center of our lakehouse architecture is the data lake, where partitioning and compression take place. A lakehouse extends this, by adding ACID transactions, enabling multiple writers, supporting rollback and time travel, and managing updates and deletes:
Schema and Partition Management
With a data lake, if you want to make changes to your data, you need to re-write the files, which is a painful and costly problem. With a strict partition layout, it would be typical to order files by Year and Month for example. But if you want to retrieve data based on another value, you can’t do this as this as the partition is already established, and you’d need to duplicate the files into another partition.
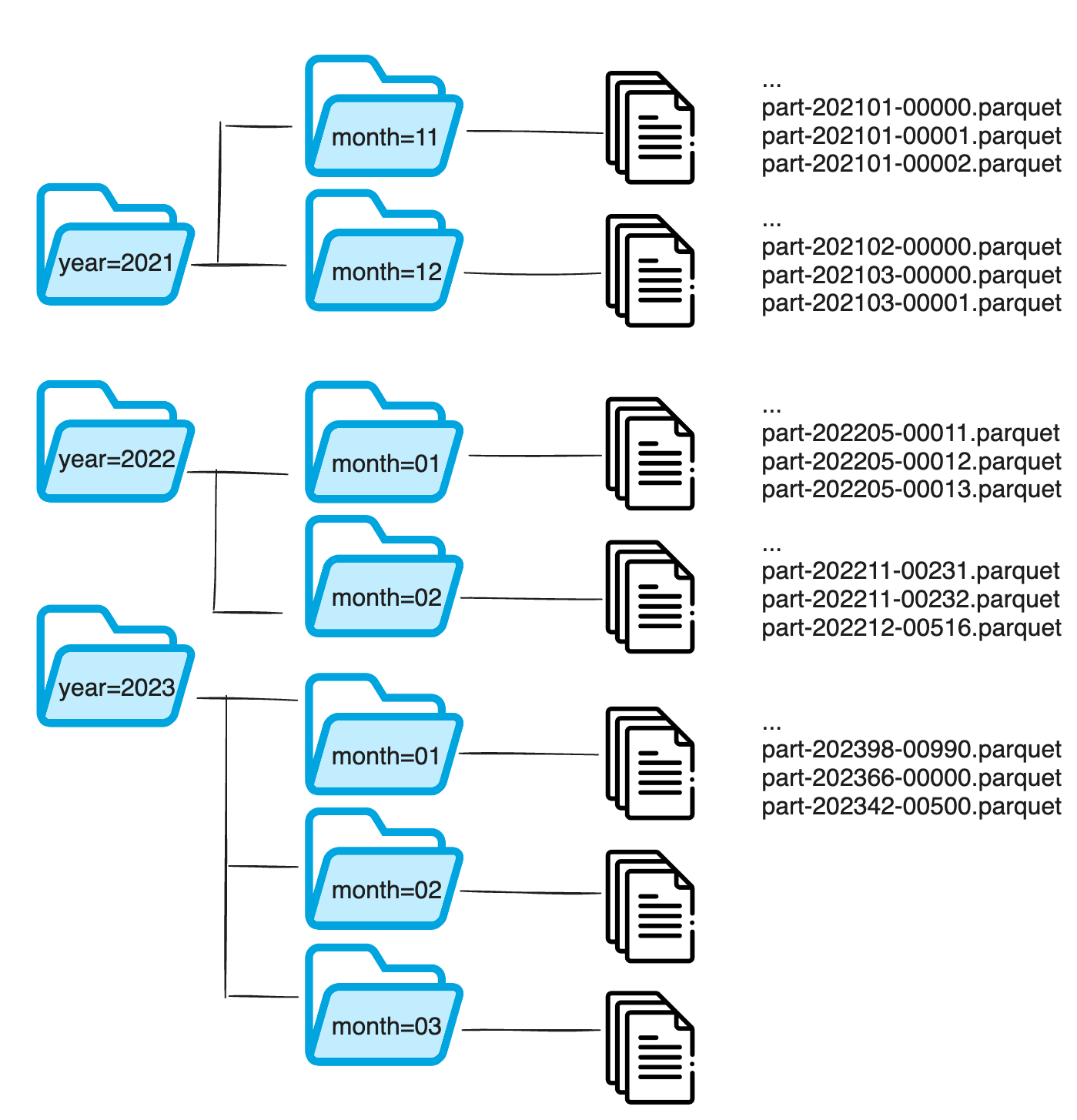
With the lakehouse, this constraint is moved from the limitations of the partition, into a set of metadata files, including the schema management. The lakehouse’s support for schema evolution and complex types, means you can change column names, and add or remove a column simply by updating the metadata file and without having to recreate the partition. Because each column has a column ID in addition to its name, this guarantees correctness. For example, if you delete a column and create a new one with the same name, there won’t be conflict because the new column exists based on the new ID, and the old data won’t be returned and cause problems in the resultset.
Furthermore, you can add extra partitions. If you have already partitioned by Year and Month, you could then add CustomerID, for example. The metadata that Iceberg retains means that you don’t have to scan the data in S3, saving huge amounts of processing time. The sort order feature enables new data to be inserted into a specific order, speeding up queries.

Scale and Performance
The scalability and performance of a lake platform depends on several factors. The data lake can reach the limitations of the catalog – such as Hive or Glue – and soon be hindered by high latency when querying very large tables. The restriction of the schema size, and the overall lack of useful features further limits its scalability. When it comes to the file format, you can store your data in CSV or JSON files, which is easy to do but won’t give you the performance you require because the engine doesn’t know how to find the data efficiently. Data splintering happens when files of a different data shape land in the same folder, and can’t be queried as a result. Furthermore, if data is thrown into S3 without any consideration for partitioning or structuring, it makes it difficult to query, and time-consuming to organize with potentially thousands of files.
With the lakehouse being based on the metadata layer, you need to be aware of the housekeeping activities needed to perform a clean-up of unused manifest or orphan files. While the lakehouse brings ACID transactions and conflict resolution, on a large and active lakehouse, a lot of activity can slow the whole system down. Lakehouses also require frequent compaction to remain performant, but it’s up to the end-user to work out when this needs to be done and instigate the operation.
Pain Points
With a data lake, there’s a lot of heavy lifting to do and you’ll need to write custom code and perform orchestration. With a lakehouse, there is still manual work to be done with the optimizations and clean-up operations. The way in which your data is stored makes a big difference to your ability to get the best performance and requires upfront planning. On the data lake, you need to write the code to implement compaction, perform hard deletes, and apply sorting and clustering. The data lake is error prone and tends to fail on a frequent basis.
Data lakes are fast for writing, but slow for querying. With many small files, this can slow queries until they are compacted, while CDC is difficult to implement and also prone to error. You can experience delays with updating the catalog, resulting in no data being returned.
The lakehouse offers more features out of the box with scheduling capabilities, but there is still work to be done to optimize the tables. You need to continuously maintain your data to ensure it is not being retained longer than it should, thereby violating GDPR compliance. You must also work out when to apply Copy-on-Write over Merge-on-Read to your tables. To understand more about Copy-on-Write and Merge-on-Read, see the article How Apache Iceberg is Reshaping Data Lake File Management.
Like the data lake, the lakehouse is fast to write and, if on-going maintenance is performed, fast to query. Be aware however, that inefficient compaction can be costly, and Merge-on-Write for streaming data can slow down queries. Lakehouses are very much designed for batch workloads, where all the changes are merged simultaneously, whereas streaming data requires streaming changes.
Using Upsolver to Manage Ingestion and Tables
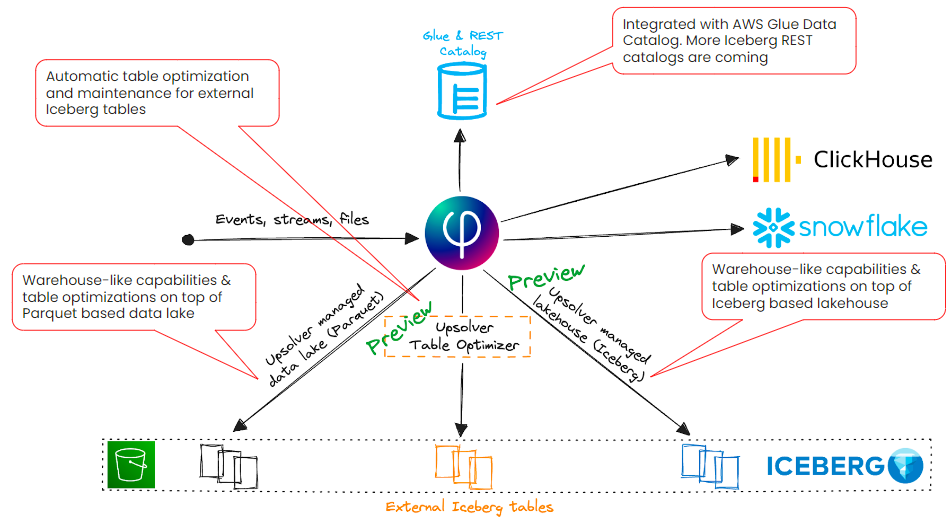
Upsolver provides an easy ingestion solution for bringing data to your lake or direct to target. Upsolver integrates with the Iceberg catalog to find the data that you need, and you can use it to manage your existing data lake without having to make the move to Iceberg, as it creates its own metadata layer on top of an existing parquet-based data lake, giving you the ability to update and delete data. Upsolver can create your Iceberg tables, and then automatically manage and optimize them for you, removing the need for manual intervention. This means users can run their queries using an engine such as ClickHouse, Athena, Redshift, and Snowflake, without having to worry about anything under the hood.
Upsolver now includes an Iceberg Table Optimizer for tables created by an external application, such as Presto, Trino, or Spark. The optimizer will maintain and clean your Iceberg lake to keep it performant. It is as simple as registering your catalog, and Upsolver will audit all your tables and make recommendations for optimizations.
To watch this webinar in full, please visit the Upsolver website, and feel free to reach out if you have any questions.
If you’re new to Upsolver, why not start your free 14-day trial, or schedule your no-obligation demo with one of our in-house solutions architects who will be happy to show you around.
Published in:
Blog
,
Data Lakes