
Explore our expert-made templates & start with the right one for you.
Common Challenges with Apache Airflow and How to Address Them
-
 Jerry Franklin
Jerry Franklin
- Streaming Data
- January 10, 2023
If you want to understand the limitations of Apache Airflow, deep dive into its technical details, and see how it stacks up against other modern orchestration solutions, you should download our free technical paper “Orchestrating Data Pipeline Workflows With and Without Apache Airflow”.
Apache Airflow (that is, AirBnB workflow) was developed by Airbnb to author, schedule, and monitor the company’s complex workflows. Airbnb open-sourced Airflow early on, and it became a Top-Level Apache Software Foundation project in early 2019.
Written in Python, Airflow has become popular, especially among developers, due to its focus on configuration as code. It is a substantial improvement over manual orchestration in Spark. Its power and flexibility helped it become the preferred air traffic control system for managing the processing jobs that move data from one place to another, or from one form to another.
But the world is passing it by. Airflow was built with daily batch data in mind, not micro-batches or streaming data. Cloud computing, data in motion at scale, and real-time analytics stretch Airflow beyond its designed capabilities, creating the need for one or more full-time engineers to maintain it, patch it, and update it. It’s brittle, and typically results in significant technical debt. In the modern data stack, Airflow is yet one more system for engineers to deploy, scale, and maintain.
As demand for fresh data accelerates and processing windows compress from days to minutes, it becomes problematic to rely on traditional batch solutions using Apache Spark and Spark Streaming for processing with Airflow DAGs as the workflow orchestrator.
Airflow has become so ubiquitous, it can be easy to lose sight of what it does not do:
- it doesn’t solve the pain of multi-step pipelines that move data between several tables and require synchronization across steps.
- it doesn’t solve error-handling with various success/failure modes
- it doesn’t address data management tasks such as file compaction and vacuum. These require a separate manual effort, but they are essential for every pipeline.
- It doesn’t easily scale.
Let’s review the most significant caveats when adding Airflow to your data stack.
What to Know About Apache Airflow Before you Get Started
Airflow is not a Streaming Data Solution
Airflow “is a batch orchestration workflow platform.” It is not a streaming data solution. The scheduling process is fundamentally different between batches and streams:
- Batch jobs (and Airflow) rely on time-based scheduling.
- Streaming pipelines use event-based triggers.
Airflow doesn’t manage event-based jobs. It operates strictly in the context of batch processes: a series of finite tasks with clearly-defined start and end tasks, to run at certain intervals or when prompted by trigger-based sensors (such as successful completion of a previous job). Workflows are expected to be mostly static or infrequently changing. In contrast, streaming jobs are endless; you create your pipelines and then they run constantly, reading events as they emanate from the source. Airflow simply wasn’t not built for infinitely-running event-based workflows. It’s impractical to spin up an Airflow pipeline at set intervals, indefinitely.
Delivering data every hour – or every minute – instead of daily means you have a lot more batches. Suddenly auto-healing and managing performance become crucial. It forces data engineers to dedicate most of their time to manually building DAGs with dozens to hundreds of steps that:
- map all success and failure modes across multiple data stores and batches
- address dependencies
- maintain temporary data copies required for processing
When you increase the batch frequency and the number of sources and targets, orchestration becomes the vast majority of the pipeline development work.
And don’t forget that orchestration covers more than just moving data – it also describes the workflow for data transformation and table management. Airflow requires manual work in Spark Streaming, or Apache Flink or Storm, for the transformation code.
Airflow is Highly Complex and Non-Intuitive
Airflow’s scripted “pipeline as code” is quite powerful, but it requires experienced Python developers to:
- create the jobs in the DAG as tasks
- stitch the processing tasks together in sequence
- program tasks for other necessary data pipeline activities (such as compaction and vacuuming) to ensure production-ready performance
- Identify and code remediation paths for all conceivable failure scenarios
- Test, debug, and troubleshoot all DAG paths.
Using Airflow for data in motion as opposed to daily batch processes is out of reach for those who aren’t data engineers, such as SQL-savvy analysts or data scientists. Data streams generally require technical knowledge with Python to access and manipulate the raw data or to tune the underlying processing system (Spark, for example). This is true even for managed Airflow services such as Astronomer or AWS Managed Workflows on Apache Airflow, which primarily simplify management of the Airflow infrastructure. Without this knowledge data practitioners struggle to deploy Airflow in a streaming environment.
Further, Airflow DAGs are brittle. Big data pipelines are complex. There are many dependencies, many steps in the process, each step is disconnected from the other steps, and there are different types of data you can feed into that pipeline. A change somewhere can break your code, and can take time to isolate and repair. For example, imagine being new to the DevOps team, when you’re asked to isolate and repair a broken pipeline somewhere in this workflow:
Onboarding is Hard with Airflow
Such complexity also translates to a steep learning curve; onboarding new engineers is a heavy lift. In addition to Python they must know – or come up to speed quickly on – multiple Airflow-specific concepts, such as the executor, the scheduler, and workers. Further, engineers new to Airflow often find it hard to conceptualize the way it’s meant to be used. For example, it can be challenging to learn to write test cases for pipelines that continuously move raw data.
Also, because Airflow essentially doesn’t care what you use it with, the team’s data stack could be quite substantial and involve many different tools – more complexity and yet more for new engineers to learn. (By contrast, Upsolver automatically handles pipeline orchestration, data management, and infrastructure. As the layer for writing transformations, Upsolver can also make moot tools such as dbt.)
Finally, Airflow documentation is insufficient, and there is no centralized source of best practices, though some of the managed Airflow services such as Astronomer are trying to address this.
What to Know When Airflow is in Production
There’s an almost endless variety of behavioral quirks and ways in which Airflow underperforms or requires expert attention. Here are some of the most significant gremlins you may encounter:
Airflow Doesn’t Come with Pipeline Versioning
Airflow doesn’t offer versioning for pipelines; it doesn’t store workflow metadata changes. This makes it difficult to:
- track workflow version history
- diagnose issues resulting from changes in the source data
- use historical data to validate fixes
- roll back pipelines
Debugging is Difficult and Time-Consuming
Airflow makes it easy to build more pipelines and just get things moving. But troubleshooting is an entirely different story. It can be quite difficult to keep the growing network of pipelines working cohesively. There are many interdependent components, and a problem could arise almost anywhere:
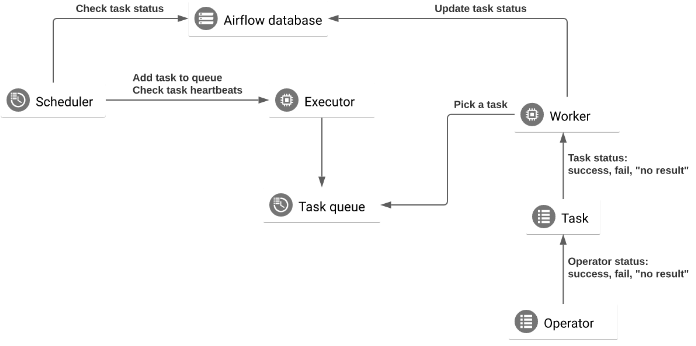
For example, Airflow Operators are templates for a preconfigured task that you can define declaratively inside your DAG. But conceptually, tasks and operators are often interchangeable; operators execute code as well as orchestrating workflows. This further complicates debugging. And there are two types of executor to debug: those that run tasks locally (inside the scheduler process), and those that run their tasks remotely (usually via a pool of workers).
And as the environment increases in complexity so, of course, does debugging. In a local environment debugging, while still time-consuming, is more straightforward than it is in the cloud. Isolating an issue and finding its root cause can be very difficult in a cloud environment, with it many microservices and distributed parts and serverless functions. As is inspecting the state of a running application in real-time, without affecting performance, likewise can be daunting.
Poor Support for Data Lineage Means Intensive Detective Work
An Airflow DAG is valid for a specific pipeline. But Airflow’s support for data lineage tracking and monitoring is, according to its own documentation, “very experimental and subject to change.” (You can push some lineage metrics to a custom backend.) So when data sources, transformations, and pipeline logic inevitably evolve, every change will require a rework and retest of the DAG. A few third-party tools (such as Open Lineage) now exist to fill this gap. But once again, more tools mean more maintenance, more complexity, and more opportunity for error.
Also, Airflow does not natively collect and store information about jobs’ owners and source repository or bucket. This complicates the effort to locate the people affected in the event of a DAG failure. Exactly whose job isn’t working? Who else downstream must be notified? What other workloads could be affected? If you can’t easily locate the DAG creator, you could lose significant time recreating or back-engineering the DAG to fix the issue and fill in any gaps that result from an outage.
Airflow May Not Run When Expected – or at All
Airflow also includes several quirks of timing that could cause confusion for the uninitiated. They’re easy enough to account for – just don’t overlook them:
- Set your start time in the past. Essentially, Airflow won’t run unless its start time has come and gone.
- The first run begins only AFTER the completion of the first scheduled interval. That’s how Airflow ensures that its first run encompasses 100% of the first interval’s data.
- Keep in mind that Apache set Airflow’s internal clock to Coordinated Universal time (UTC). It’s easy enough to account for this, but you cannot change it, so account for it you must.
Airflow Cannot Locate the DAG
This could be because the DAG path is incorrect, or left unspecified, or the YAML file could be misconfigured. Other reasons, and a possible solution.
Issues with Airflow Scheduler
Many challenges arise due to quirks in the way the Scheduler works. First, keep in mind again that the primary use case is for scheduling periodic (usually daily) batches, not frequent runs.
Next, it is not that hard, unfortunately, to inadvertently overwhelm the Scheduler; Airflow devotes processing time to parse every DAG, regardless of whether the DAG is actually in use. Keep usage of your environment’s capacity to <50% to avoid performance issues.
And try to keep your loads consistent over time by varying start times. All things being equal, we tend to schedule runs at standard times and intervals – every hour on the hour, for example. But if you do this as a matter of course, or if someone merges a large number of auto-generated DAGs that are similarly scheduled, it can create a traffic overload that impacts performance. And your performance will be impacted – every hour on the hour. Varying your start times can help mitigate or prevent spikes that strain resources and lead to other problems. This can also help you scale.
But if you change the schedule, you must rename your DAG, as the previous task instances will no longer align with the new interval.
Tasks are Slow to Schedule or Aren’t Being Scheduled
If your Scheduler is not doing its job well – or at all – examine and adjust your scheduler parameters; scheduler settings are in the airflow.cfg. file. You have several options:
- Increase the frequency at which Airflow scans the DAGs directory. Higher frequencies (the default is every 300 seconds) are more CPU-intensive.
- Increase the frequency at which the Scheduler parses your DAG files. Again, a higher frequency means more CPU usage; consider increasing the value (that is, lowering the frequency).
- Increase the number of processes the Scheduler can run in parallel.
Task Logs are Missing or Fail to Display
Missing logs typically are due to a failed process in your scheduler or in a worker. This can take time to troubleshoot. It’s possible either your Scheduler or your Web server logs could lead you to the problem. Absent that, try clearing the task instance in the Airflow UI and re-running the task. Other possibilities:
- Increase the timeout for fetching logs in the log_fetch_timeout_sec file
- Search for the log file from within a Celery worker
- Add resources to the workers
You receive an “unrecognized arguments” error
This could happen because the DAG file is not being properly imported into the Airflow system, or because there is a problem with the DAG file itself. There are also several Other reasons for Airflow to throw this error and a possible solution.
Task Performance Issues
Tasks Run Slow or Fail
There are many ways tasks can fail to complete, and each scenario has multiple potential causes. You can save yourself some agita by setting up error notifications. That helps you get a jump on troubleshooting, but of course you must know Airflow well to get to the bottom of these issues.
For tasks that aren’t running, it could be because:
- the task is paused
- the start date in the past
- the Scheduler isn’t running properly
- There’s a conflict between newly-added tasks and task states (that is, set for prior task runs)
For tasks that show as failed, you may be able to pinpoint the issue in the Airflow UI. Otherwise, check the logs.
- the task may have run out of memory
- Zombie tasks often result from insufficiently-assigned resources. Try increasing the timeout, which gives workers more time to report task status.
- Airflow automatically shuts down tasks that take too long to execute (a “poison pill”). Again, assign more resources to enable faster execution.
Tasks can also fail without emitting logs in the first place. This could be due to:
- a DAG parsing error
- insufficient compute resources
- pod eviction (if you’re using Kubernetes)
- other reasons
Tasks are Bottlenecked
There are multiple possible reasons for this. You could be running too many concurrent DAGS or DAGS with too many concurrent tasks. In this case, adjusting some of the parameters in your airflow.cfg file could resolve the issue. In particular:
- Are you running many tasks in parallel, in total (that is, in all your DAGS combined)? If so, set a higher number of tasks in parallelism.
- Are you scheduling too many tasks to run at one time? If so, increase the number of DAG runs in max_active_runs_per_dg.
- Are you assigning too many concurrent tasks to your workers? If so, you can raise the default limit of 16 tasks in airflow_celery_worker_concurrency (though this figure in turn may be limited by your number of DAGs running concurrently). You might also look at adding Celery workers or adding resources to your Scheduler.
Similarly, you may encounter a large number of tasks in the “None” state, or in Queued Tasks and/or Tasks Pending in CloudWatch (if you’re running an AWS environment). The likeliest reasons for this:
- there are more tasks than the environment has the capacity to run
- a large number of tasks had queued before the autoscaling mechanism had time to detect them and deploy additional Workers.
If either is the case:
- reduce the number of tasks your DAGs run concurrently
- stagger task deployment
- increase the number of assigned workers
Sensor Tasks Fail Intermittently
This could be an issue with a task or with a sensor.
Airflow sensors run continuously until their conditions are met. Sensor failure can result when concurrent tasks exceed the capabilities of the workers. You can configure your logic to reschedule sensors when there aren’t enough worker slots. Or you could just run your DAGs at more frequent intervals. In Airflow 2.2, you can avoid sensors altogether and use Deferrable Operators, instead, which don’t occupy worker time when they’re awaiting their conditions. As a result you use substantially fewer resources.
External Issues
Sometimes you might encounter issues with Airflow whose genesis has little or nothing to do with Airflow per se. Insufficient resources, or resource conflicts, are often the source; regardless, it still translates into more to troubleshoot.
Non-Optimal Environment Performance
This can cause a range of DAG execution issues. For example, external systems such as Linux and Kubernetes can kill Airflow processes via SIGTERM signal. This could require you to allocate more resources to your VM. And this is just one example.
Your Browser Won’t Access Airflow (a 503 error)
This could be due to your Web server, rather than with Airflow or your DAG per se. If it’s under-resourced it may time out before loading or running your DAG; in this case assign it more memory or processing capacity, or try extending the timeout period.
Because of the way Airflow runs code – external to its own operators – performance could also suffer if your logic calls for making a high number of database requests or API calls outside of an Airflow operator. In this case, if you can, move the logic elsewhere – for example, into a Python operator.
Corrupted log files
If you’re processing log files and are using Airflow, you couldreceive a ValueError if log files are corrupted, missing, or otherwise inaccessible. This can prevent Airflow’s file.processor handler from being able to read and process the logs, resulting in an error message. And this is only one of several reasons Airflow could throw this error.
Summary: Open Source? Check. Free? Yeah, About That…
It should be clear by now that Apache Airflow is like a free puppy – it’s not truly, really free. You must hire and retain engineers with deep technical knowledge in how to design, deploy, and maintain Airflow. The only way to avoid the trouble and expense of a DIY Airflow deployment is to use – and pay for – a managed Airflow service, such as AWS or Astronomer.
Orchestration is not optional, and neither is doing it on the cheap – at least, not if you use Airflow.
With Upsolver you can Eliminate Airflow work from Data Pipelines
Upsolver is an all-SQL declarative data pipeline platform for streaming and batch data. It treats all data as data in motion. You use SQL statements to ingest data from stream, file, and database sources into data lake tables, create jobs that execute stateful transforms, and stream the output into live target tables in your data lake, query engine, or data warehouse. You can try out sample templates in Upsolver Upsolver for free, or check out how to use Upsolver to implement CI/CD for your data pipelines.
Upsolver is Architected for Automation
Upsolver automatically parses the dependencies between each step in the pipeline to orchestrate and optimize the flow of data for the most efficient, resilient, and high-performing data delivery.
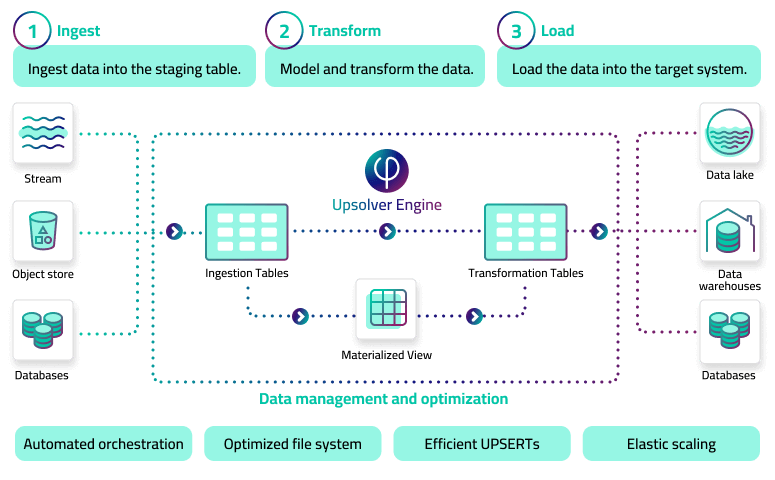
By eliminating orchestration and automating other management and optimization tasks that take the bulk of an engineer’s time, Upsolver slashes the time it takes to develop production pipelines. Just write a query and get a pipeline:
- No Airflow /No DAGs — Upsolver’s unique architecture eliminates the need for orchestration
- Optimizations such as compaction, vacuuming, and metadata management are handled automatically
- Source schema is detected and mapped to staging tables automatically, including added fields
- Tables are updated incrementally without full data scans
Try Upsolver for Free
Try Upsolver for free. Unlimited free trial. No credit card required.
To learn more about Upsolver visit the Upsolver Builders Hub, where you can browse our pipeline templates and consult an assortment of how-to guides, technical blogs, and product documentation.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
Published in:
Blog
,
Streaming Data