
Explore our expert-made templates & start with the right one for you.
Table of contents
Intro
This frequently-updated page contains real-life examples and diagrams from Upsolver customers who are using AWS data lakes. While the Upsolver platform itself is a key component in all of these architectures, we hope even non-customers can learn from these examples when it comes to the use cases, considerations, and design patterns that go into a typical cloud data lake.
1. Sisense Builds a Versatile Data Lake with Minimal Engineering Overhead
As a leading global provider of business intelligence software, Sisense has data-driven decision making embedded in its DNA. One of the richest sources of data the company has to work with is product usage logs, which capture all manner of users interacting with the Sisense server, the browser, and cloud-based applications.
Over time, and with the rapid growth in Sisense’s customer base, this data had accumulated to more than 70bn records. In order to effectively manage and analyze this data, the company quickly realized it would have to use a data lake architecture, and decided to build one using the AWS ecosystem. We’ve written a more detailed case study about this architecture, which you can read here.
The Data Lake
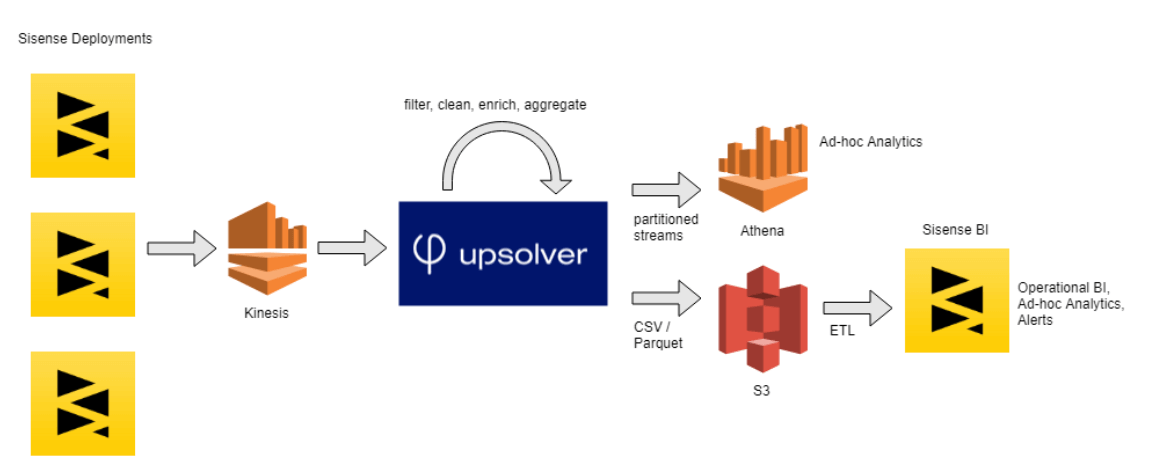
To quickly generate value for the business and avoid the complexities of a Spark/Hadoop-based project, Sisense’s CTO Guy Boyangu opted for a solution based on Upsolver, S3, and Amazon Athena.
Product logs are streamed via Amazon Kinesis and processed using Upsolver, which then writes columnar CSV and Parquet files to S3. These are used for visualization and business intelligence using Sisense’s own software. Additionally, structured tables are sent to Athena to support ad-hoc analysis and data science use cases.
To learn more about Sisense’s data lake architecture, check out the case study.
2. The Meet Group’s New Data Architecture Supports All its Tools of Choice
The Meet Group is a leading provider of interactive online dating solutions. Its mobile apps are comprised of five brands and offer different experiences and options for connecting individuals.
Its applications are used by millions across the globe daily and are available in multiple languages. Given the scope of The Meet Group’s reach, the company’s software generates hundreds of millions of daily events.
After several acquisitions, The Meet Group sought a powerful and scalable data lake solution to integrate its data pipelines and central data collection to drive better real-time aggregate insights and analysis.
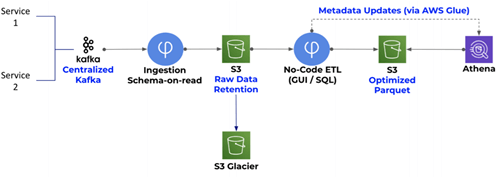
The Meet Group uses Upsolver as a real-time collection and transformation engine that connects data producers such as Apache Kafka, Amazon Kinesis, and operational databases to analysis tools such as Amazon Athena, Amazon Redshift, and Amazon Elasticsearch Service. By choosing a data lake on AWS, The Meet Group can leverage the best tool for each analytics and data science use case, using Upsolver for scaling and optimizing the data pipelines automatically to meet their business demands.
All of The Meet Group’s data is collected to a centralized Kafka data hub. Upsolver ingests this data to S3 and extracts a strongly typed schema-on-read, which is updated in real time and presented in Upsolver’s visual UI. In turn, The Meet Group users create data transformation jobs by mapping the schema-on-read to tables in various analytics tools. The syntax for these jobs is SQL-based and each job can mesh multiple data sources into a single table. After users run their jobs, Upsolver continuously updates the target tables and data becomes queryable in Athena. The data Upsolver creates for Athena is optimized for faster queries by using columnar formats (such as Apache Parquet), compression, partitioning, and compaction of small files. Upsolver maintains the metadata for Athena tables in the AWS Glue Catalog.
Learn more about The Meet Group’s data lake architecture.
3. ironSource Streams its Way to Hypergrowth
ironSource is the leading in-app monetization and video advertising platform. ironSource includes the industry’s largest in-app video network. The company collects, stores, and prepares vast amounts of streaming data from millions of end devices.
When ironSource’s rapid data growth effectively obsoleted its previous system, it chose Upsolver to help it adopt a streaming data lake architecture, including storing raw event data on object storage.
The Data Lake
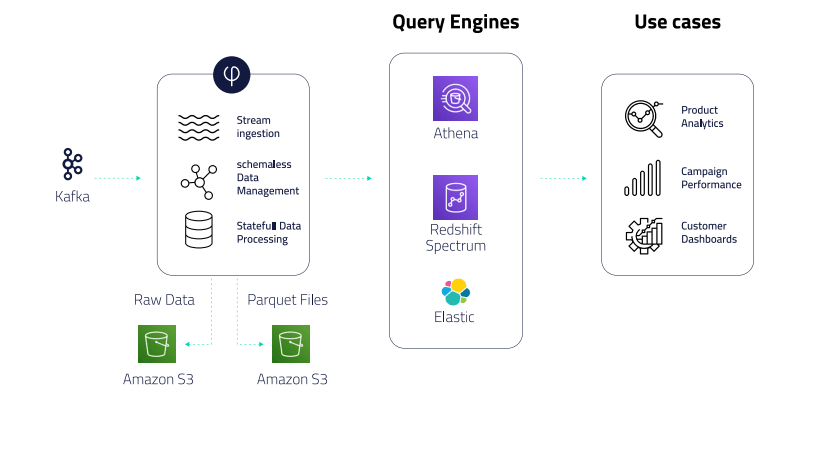
- Using Upsolver’s no-code self-service UI, ironSource ingests Kafka streams of up to 500K events per second, and stores the data in S3.
- Upsolver automatically prepares data for consumption in Athena, including compaction, compression, partitioning, and creating and managing tables in the AWS Glue Data Catalog.
- ironSource’s BI teams use Upsolver to enrich and filter data and write it to Redshift to build reporting dashboards in Tableau and send tables to Athena for ad-hoc analytic queries.
Learn more about ironSource’s data lake architecture.
4. Bigabid Builds a High-Performance Real-time Architecture with Minimal Data Engineering
Bigabid brings performance-based advertisements to app developers, so clients only pay when new users come to their application through the ad. Bigabid takes advantage of machine learning (ML) for predictive decision-making and goes beyond social media and search engine data sourcing to create an in-depth customer user profile.
Bigabid had to replace its daily batch processing with real-time stream processing, so the company could update user profiles based on users’ most recent actions and continue to develop and scale ad campaigns. Using Upsolver’s visual no-code UI, Bigabid built its streaming architecture so quickly, it saved the equivalent of 6-12 months of engineering work from four dedicated engineers.
The Data Lake
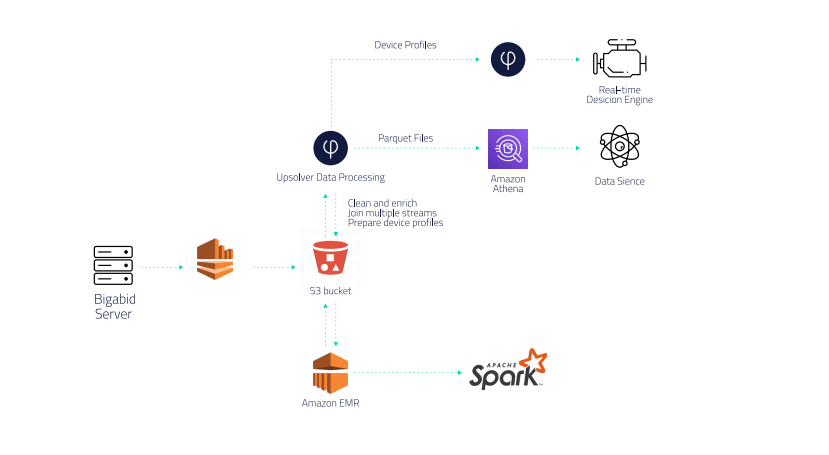
Bigabid uses Kinesis Firehose to ingest multiple data streams into its Amazon S3 data lake, then uses Upsolver for data ETL, combining, cleaning, and enriching data from multiple streams to build complete user profiles in real-time. The company also uses Upsolver and Athena for business intelligence (BI) reporting that is used by its data science team to improve machine learning models.
Upsolver also automatically prepares data for Athena, optimizing Athena’s storage layer (Parquet format, compaction of small files) and sharply accelerating queries.
Learn more about Bigabid’s real-time data architecture.
5. SimilarWeb Crunches Hundreds of Terabytes of Data
SimilarWeb is a leading market intelligence company that provides insights into the digital world. To provide this service at scale, the company collects massive amounts of data from various sources, which it uses to better understand the way users interact with websites.
In a recent blog post published on the AWS Big Data Blog, Yossi Wasserman from Similar Web details the architecture that the company uses to generate insights from the hundreds of terabytes of anonymous data it collects from mobile sources.
The Data Lake
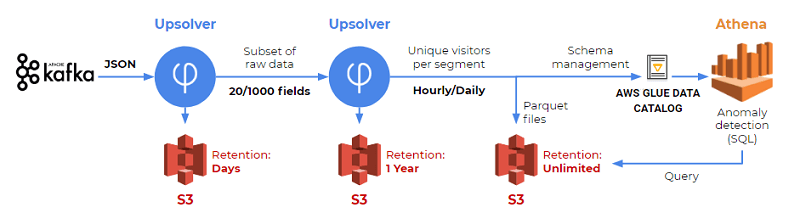
Image source: AWS blog
The SimilarWeb solution utilizes S3 as its events storage layer, Amazon Athena for SQL querying, and Upsolver for data preparation and ETL. In his article, Wasserman details the way data is sent from Kafka to S3, reduced to include only the relevant fields needed for analysis, and then sent as structured tables to Athena for querying and analysis.
Read more about Similar Web’s data lake solution on the AWS blog.
6. Meta Networks’ Event-Streaming Architecture Creates Myriad Opportunities
Meta Networks provides companies with a holistic solution to network security through a software-defined perimeter (SDP), a VPN alternative for secure remote access to any application.
The amount of inbound and outbound traffic and streaming data the Meta NaaS platform collects in real-time is substantial. The company knew a data-driven approach and a big data solution would create new opportunities for both internal teams and customers.
The Data Lake
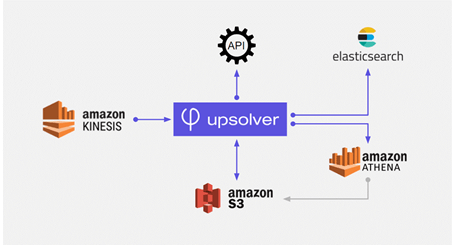
Upsolver’s service focuses on helping companies that generate event streams to quickly analyze data using Amazon Simple Storage Service (Amazon S3) as a storage layer.
Meta Networks integrated Upsolver into its Amazon data stack. It used Upsolver’s visual interface to ingest data from Amazon Kinesis to S3 and then ETL the data from S3 to Amazon Athena, Amazon Elasticsearch, and Upsolver’s own real-time lookup tables. Upsolver’s data lake ETL include a streaming join between Kinesis and S3 so Meta Networks could easily combine real-time and historical data in its analytics.
Meta Networks deployed an analytics solution on Amazon Athena to production and could slice and dice its network data from multiple customer deployments using SQL. The company also uses Upsolver’s lookup tables and Elasticsearch to sharply reduce query times and create customer-facing dashboards that present interactive real-time data at the end point level.
Learn more about Meta Networks’ event streaming architecture.
7. Peer39 Contextualizes Billions of Pages for Targeting and Analytics
Peer39 is an innovative leader in the ad and digital marketing industry. Each day, Peer39 analyzes more than 450 million unique web pages holistically to contextualize the true meaning of the page text and topics. It helps advertisers to optimize their spend and place ads in the right place, at the right time.
The Data Lake
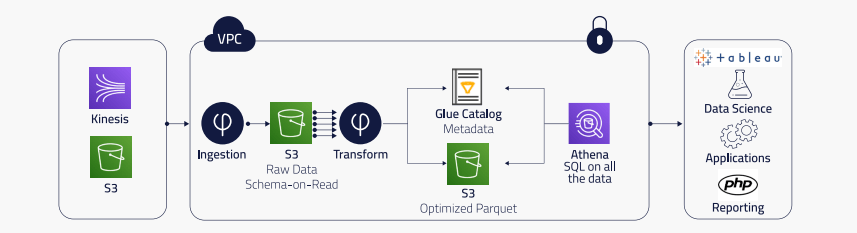
Upsolver automates and orchestrates Peer39’s data workflow, incorporating built-in data lake best practices including:
- partitioning
- queuing
- guaranteed message delivery
- exactly-once processing
- optimization of Athena’s storage layer (Parquet format, compaction of small files) so queries run much faster.
Peer39’s updated streaming data architecture unified teams across data science, analytics, data engineering, and traditional database administration, enabling the company to speed go-to-market with existing staff.
Learn more about Peer39’s streaming data architecture.
8. Browsi – Managing ETL Pipelines for 4 Billion Events with a Single Engineer
Browsi provides an AI-powered adtech solution that helps publishers monetize content by offering advertising inventory-as-a-service. Browsi automatically optimizes ad placements and layout to ensure relevant ad content.
Browsi needed to move from batch processing to stream processing, and move off of manually-coded data solutions.
The Data Lake
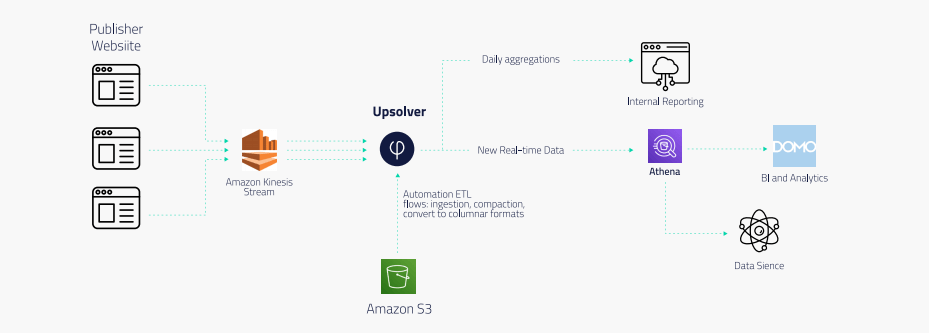
Browsi implemented Upsolver to replace both the Lambda architecture used for ingest and the Spark/EMR implementation used to process data.
Events generated by scripts on publisher websites are streamed via Amazon Kinesis Streams. Upsolver ingests the data from Kinesis and writes it to S3 while enforcing partitioning, exactly-once processing, and other data lake best practices.
From there, Browsi outputs ETL flows to Amazon Athena, which it uses for data science as well as BI reporting via Domo. End-to-end latency from Kinesis to Athena is now mere minutes. Meanwhile, a homegrown solution creates internal reports from Upsolver’s daily aggregations of data.
And it’s all managed by a single data engineer.