
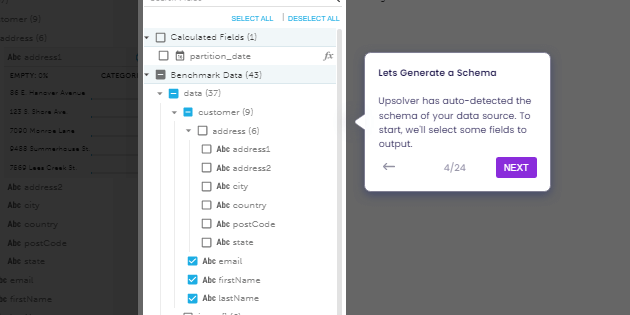

Explore our expert-made templates & start with the right one for you.
Spark was first introduced in 2009 as a much faster alternative to Hadoop MapReduce. It offers a flexible real-time data lake compute engine that supports complex transformations. Due to its performance and support for popular programming languages like Java, Scala and Python, Spark has been a popular environment for creating data lake processing jobs.
![]()
![]()
![]()
Why many companies struggle with Spark
Spark has its roots in the very complex Hadoop ecosystem, which has made it a difficult technology to use efficiently for many companies.
Spark requires specialized engineering resources to build and maintain data pipelines. Spark inherited the complexity of Hadoop and requires specialized engineers that understand distributed systems, coding in Scala/Java, workflow orchestration and analytics best practices.
Spark transformation pipelines are time-consuming and complex to build. Using Spark requires more than just coding transformations. You must write jobs to handle state management and file system management. Also, you must specify the job execution through an orchestration system like Airflow. Finally, there are numerous “levers” to pull in order to optimize the data lake for performance. Creating a pipeline in this way is time-consuming, error-prone and creates significant “tech debt” that is paid off through lengthy cycles for any change to the pipeline.
There is no self-service or low-code Spark The move towards cloud computing sprung several proprietary managed services built on Spark’s core features while adding security, reliability and managed cloud infrastructure. These products offload the burden of ensuring availability of a Spark cluster, they do not assist with making Spark jobs easier to program or maintain.
![]()
Upsolver: low-code lake-based data pipelines
Upsolver was founded by database engineers who wanted to bring the simplicity of a database to the cloud data lake, without the complexity of Spark. Key attributes include:
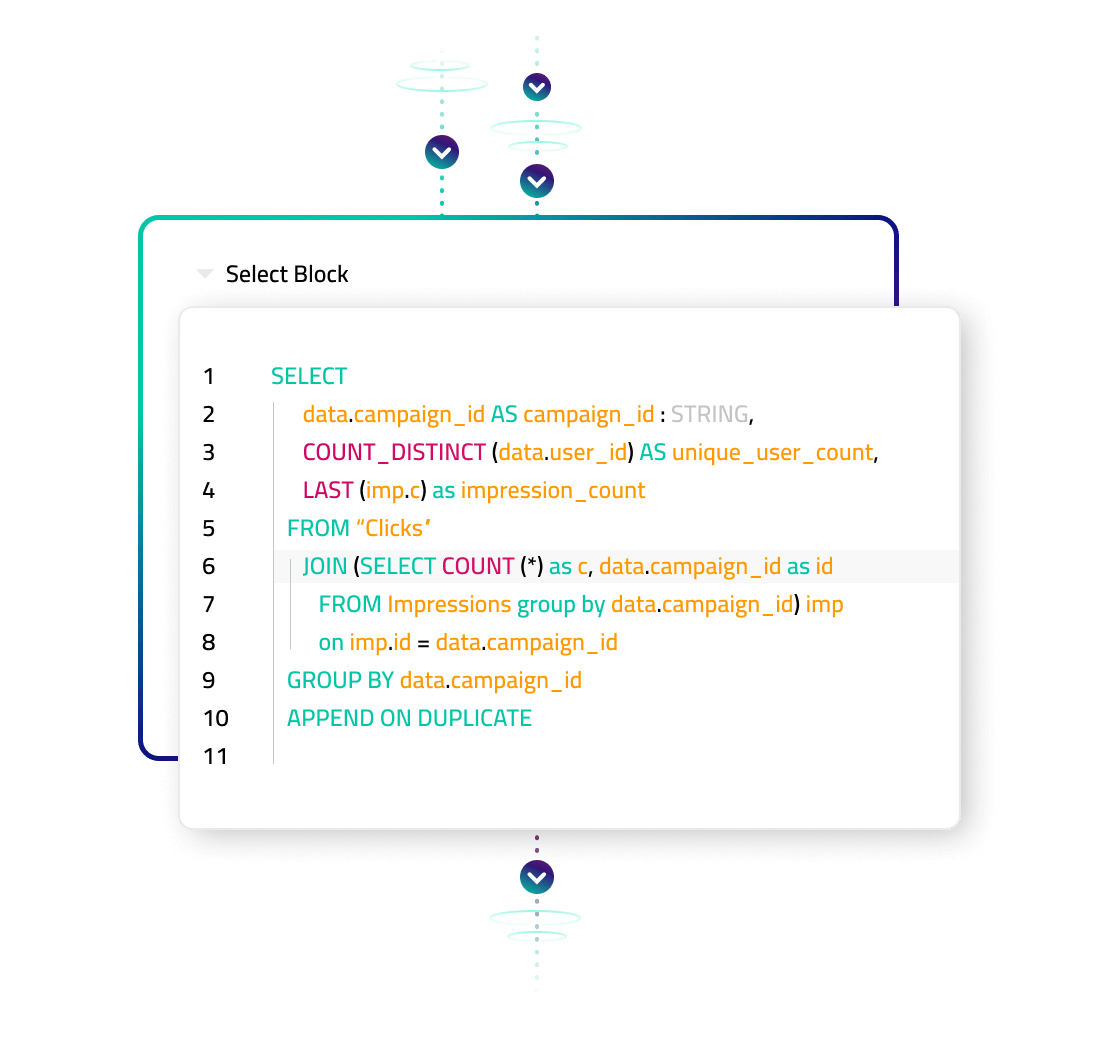
- Choose no-code, low-code or high-code: Upsolver allows transformations to be specified via a GUI or SQL commands, plus allow insertion of custom Python when needed. Anyone who can read SQL and build a pipeline.
- Abstract away data lake complexity: Data consistency (no loss, no duplications), ETL jobs orchestration, ETL state management and file system management are all handled automatically, according to best practices.
- Deliver analytics-ready live tables: Upsolver outputs tables to your data lake or external data store and keeps them up-to-date and data strongly consistent.
- Combine streaming and batch data: Upsolver processes all data as a stream, meaning that stateful transformations such as streaming joins, aggregations and use of sliding windows are handled easily.
- Automate elastic scaling: Upsolver never stores data on local server storage so processing automatically and elastically scales.
- No infrastructure to manage: Upsolver runs in your VPC and is fully managed, Data never leaves your control.
These advantages over Spark, allow Upsolver customers to build and run at-scale pipelines for complex data in days, without hiring or redeploying expensive big data engineers.
Comparison Matrix
 |
||
| Data transformations | Scala / Python | UI / SQL |
| Raw data schema detection | User | Upsolver |
| Job orchestration | User | Upsolver |
| State management | User | Upsolver |
| Exactly-once processing | User | Upsolver |
| File system optimization | User | Upsolver |
| Healing, scaling, upgrades | User / platform | Upsolver |
| Time to production | Months | Days |
| Headcount | 3-4 big data engineers | 1 engineer / DBA / analyst |
To learn more about how Upsolver compares to Spark, download the full guide here