



Explore our expert-made templates & start with the right one for you.

Easy button to
ingest & manage
high-scale data in
Enjoy the cost savings and shared access of a cloud-native lakehouse, without the engineering pain.
27 Trillion rows
ingested/month
50 PB
managed/month
35 GB / sec
peak throughput

Data movement at scale
Ensure your critical data is delivered to downstream users reliably, accurately and on time.
When you combine high-volume data with frequent updates and in-flight processing, you need expert
plumbing. Upsolver moves data from complex sources (streams, CDC, files) into your warehouse or lake
reliably at scale.

Open lakehouse control center
Support users from every part of the business to access data their way, but stay in charge.
Avoid functional silos and inconsistent performance in the lakehouse by using Upsolver as your
control center. A single pane of glass for all your data, based on the open Apache Iceberg table
format.
Build, monitor & share
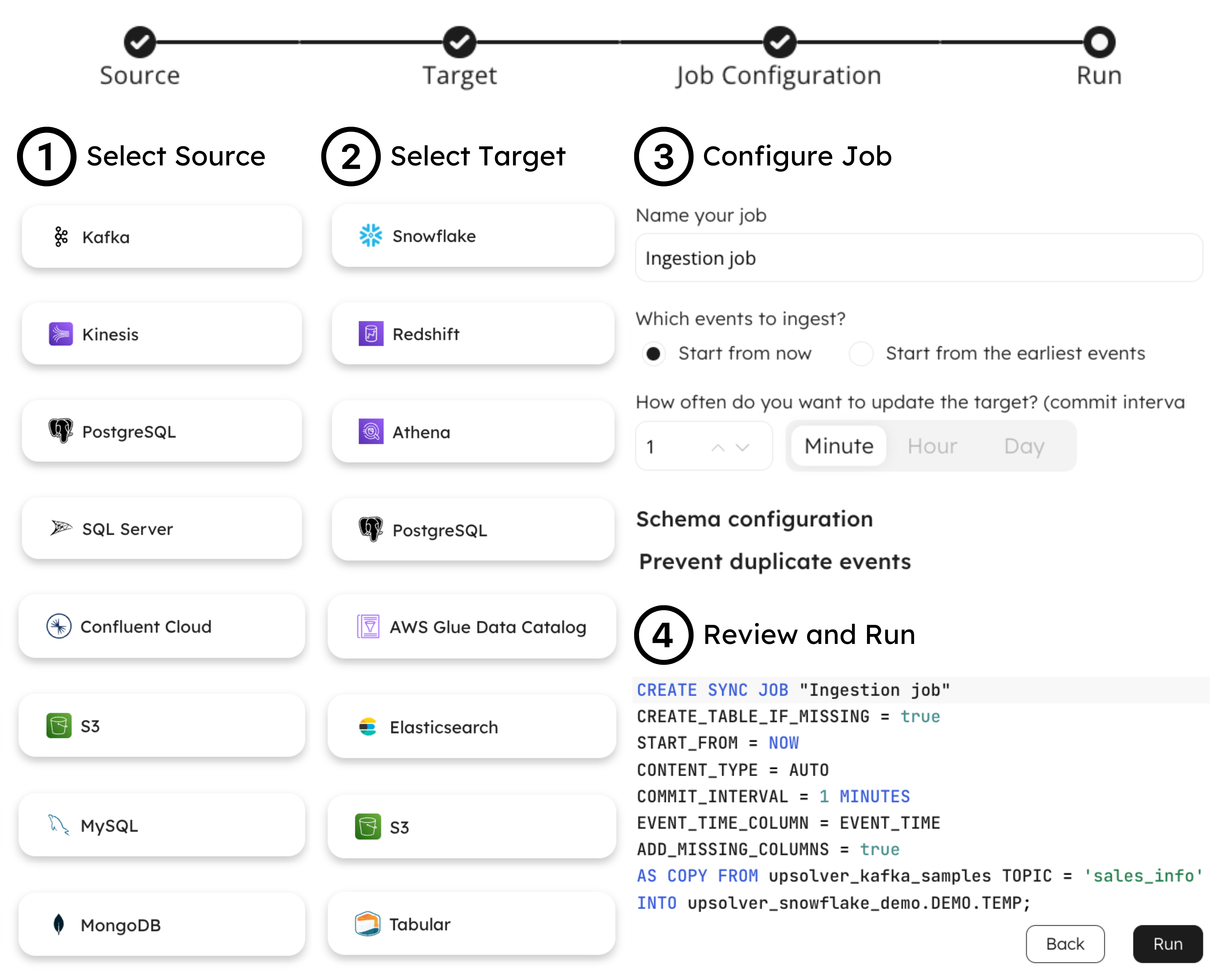
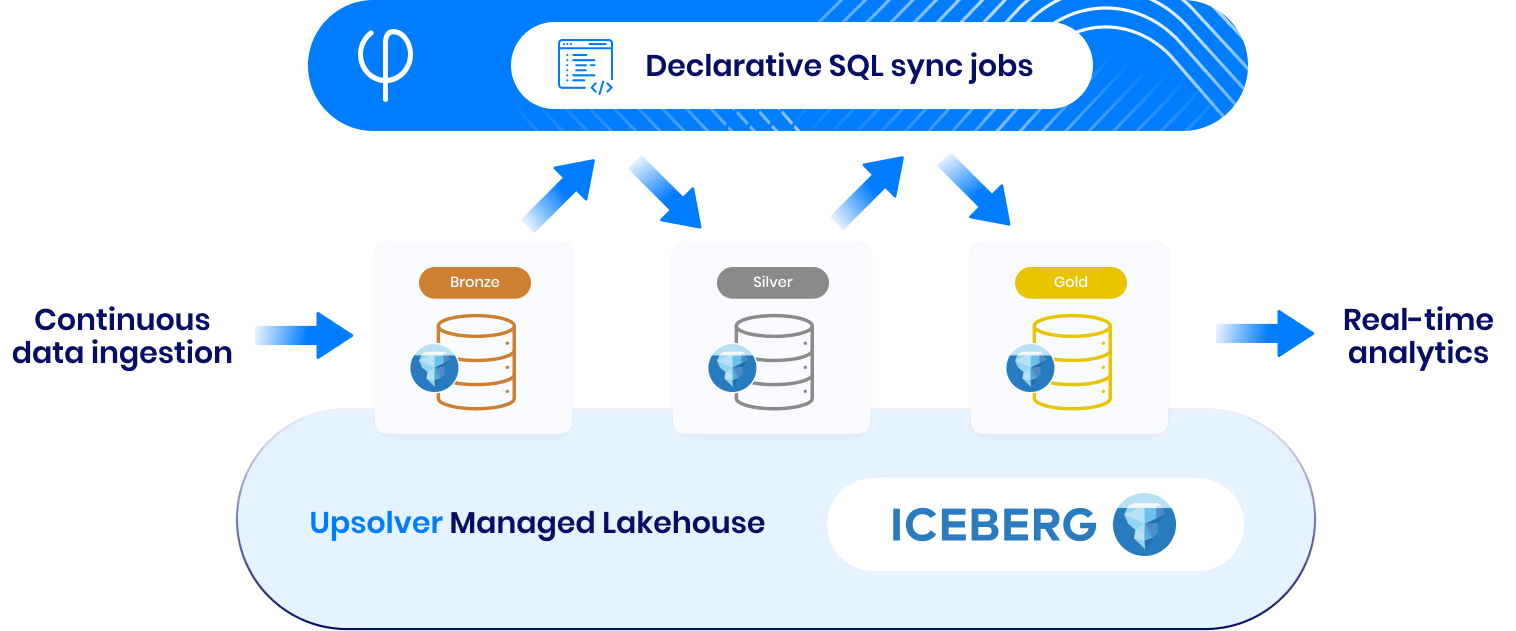
Give your business an edge with up to the minute data! Easily ingest data from operational stores to the warehouse and Apache Iceberg-based lakehouse with minimal configuration.
Zero-ETL ingest data at scale
Transform with declarative SQL

Observe metrics in real-time

Share with the open ecosystem
Leave the plumbing to us
Upsolver continuously analyzes and optimizes your data movement jobs and lakehouse tables with:
Unify data in motion and data at rest
A single platform for developers to ingest, transform and load streaming and historical data

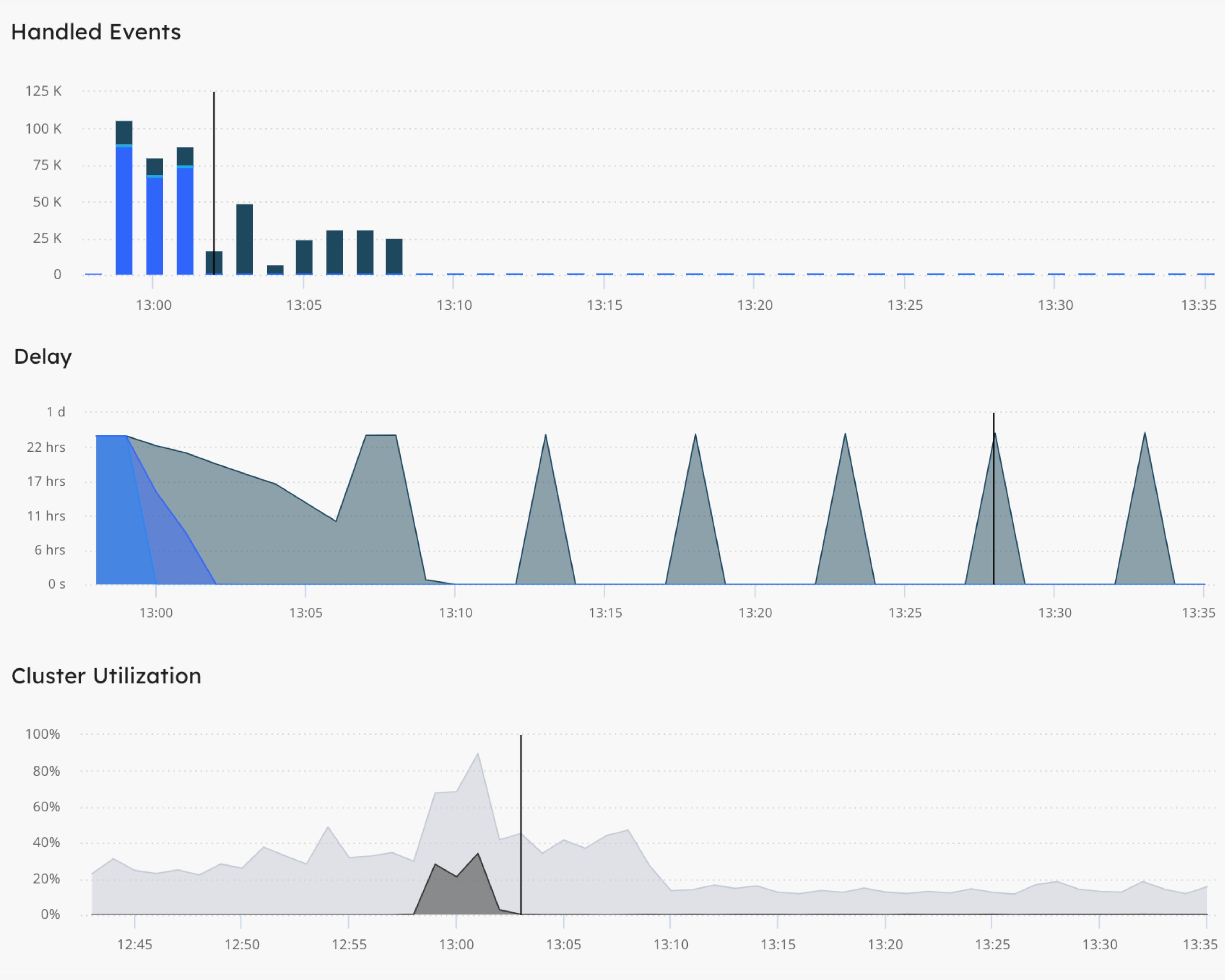

Resiliency without compromise

SyncStream technology
Synchronized pipelines ensure consistent and reliable processing of real-time events, with late-arriving events automatically accounted.

Autohealing
Systems are unpredictable. In case of network downtime, Upsolver automatically reconnects and restarts operations where it left off.

Automatic schema handling
Column names and data types evolve with your application. Upsolver automatically adjusts names and types to fit the target system, even JSON nested ones.

Exactly-once delivery
Automatically deduplicate events over large windows of time, at scale. Works with streams and files without compromise.

Managed scaling
Built on a decoupled shared-nothing architecture, scales seamlessly to match usage. Utilizes discounted Amazon EC2 Spot instances to save you money.

Data replay and backfill
The need to fix your data is inevitable. Upsolver allows you to easily replay data from any historical point in time or create jobs to backfill existing tables.
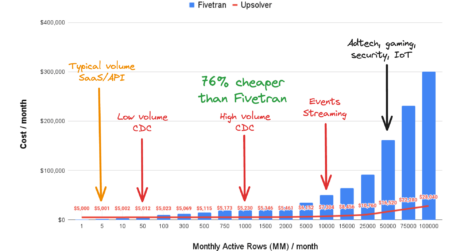
Designed and priced for scale
Upsolver charges by data volume. Competitor charges by ‘active rows’.
This key difference drives order-of-magnitude savings when data volumes scale

Empowering the next generation
of data developers
From startups to enterprises


