
Explore our expert-made templates & start with the right one for you.
What is Databricks? Components, Pricing, and Reviews
-
 Eran Levy
Eran Levy
- Cloud Architecture
- October 14, 2022
If you’re looking to build a modern data stack, you’ve probably heard of Databricks. With a staggering $3.5B in private funding, a heated dispute with Snowflake over performance (see Snowflake vs Databricks), and a large and established customer base, Databricks is certainly a force to be reckoned with in today’s cloud data ecosystem.
However, as with any technology, making informed decisions requires cutting through the noise. No single tool will solve every data engineering challenge you’re facing, and it’s important to understand where various software is more or less useful.
Towards this end, this article provides a brief overview of Databricks – its components, use cases, and some of the strengths and weaknesses we’ve learned based on online reviews and conversations with Databricks users. We hope this will help you make a more informed decision when evaluating Databricks or other data technologies.
Full disclosure: Upsolver competes with Databricks for certain use cases around large-scale data processing, as well as data lakehouse architectures. In other cases, Upsolver can and is used alongside Databricks.
What is Databricks?
A Quick Overview
Databricks is a U.S.-based company, founded by the team behind Apache Spark. It has since grown to be a major contributor to data lake technology across all the major cloud platforms. Their products purport to facilitate data engineering, data science, and machine learning – but as we shall see, they are not necessarily equally well-suited for all use cases.
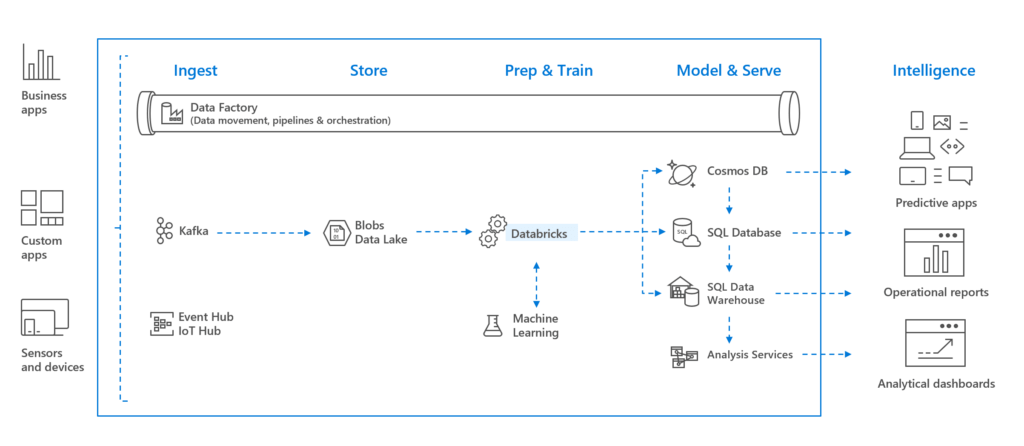
What are the Key Features and Components of Databricks?
Databricks is comprised of several component technologies that we will describe briefly:
Spark
Apache Spark is an open-source cluster computing system for fast and flexible large-scale distributed data processing. It enables you to query data stored across hundreds of machines. Databricks at its heart is a managed service for Spark, which is a core component of the Databricks ecosystem. This means a solid understanding of Spark is essential for any work done with Databricks.
Workspaces and Notebooks
Development in Databricks is organized in Workspaces and Notebooks. A workspace contains all the assets and libraries used in your Databricks environment; specific jobs are run through notebooks (similar to tools such as Jupyter or Google Colab). Compute resources are allocated via Runtimes (which we cover below).
AutoML and MLflow
Databricks AutoML is a service that enables you to build machine learning models in a low-code environment. It can be compared to tools such as Amazon Sagemaker. MLflow tracks machine learning experiments by logging parameters, metrics, versions of data and code, and any modeling artifacts from a training run. That information is then available to compare previous runs and to execute a previous test. MLflow can be used as a regular logging system in data science development.
Delta Lake
Delta Lake provides a table format layer over your data lake that gives you a database-like schema view and style ACID transactions through logs that are associated with each Delta table. There is some confusion over Delta Lake as there is both an open source version and a more robust custom version that Databricks commercializes with their offering.
While Delta Lake optimizes the storage layer, accessing the data in Databricks still requires writing Spark code in most current use cases.
Delta Live Tables operate as a pipeline management layer that works against Delta Lake to provide more automated testing, as well as better monitoring and visibility for ETL pipelines.
Unity Catalog
Unity Catalog is used as a central governance catalog for metadata and user management. Conceptually it allows you to manage user access rights on tables, fields, and views, rather than on the files in the lake. This is done through SQL Grants for a unified permission model for all data assets. This is distinct from Delta Lake, which provides a schema view of the lake files, but they work together.
Runtimes
A Runtime is basically a Spark cluster that provides the compute resources to run a specific job. The types of available runtimes include:
- All purposes (also known as interactive): Attached to a live notebook. Can be configured to shutdown when idle.
- Job clusters – provisioned to run a specific notebook. Can be set to autoscale or called via the API.
- Pools – allow you to reserve certain amount of resources, since your notebook is going to run on a regular basis
With all Those Components, What Does Databricks Do?
At its core, Databricks is a data science and analytics platform to query and share data that is built on top of Spark. Databricks has built a large ecosystem that you can entirely live in – if you’re willing to pay a premium for running clusters and you have a team that’s well-versed in Spark.Those workloads provide the tools and environment for running analytics and machine learning workloads across huge, distributed data repositories.
Spark is notorious for being very difficult to set up and run on your own infrastructure. Databricks abstracts some of that complexity, however, you still need to know how to work with Spark DataFrames and understand the intricacies of Spark coding to run your Databricks jobs.
How Does Databricks Pricing Work?
When you get to the cloud, the question of cost can be really hard to answer as a lot of it depends on what services you are using and at what scale. Pricing also includes costs for Databricks in addition to the cloud service. For this article we cover only AWS, but it is generally similar for GCP and Azure.
Databricks Pricing Overall
Databricks does provide a pricing page to get you going, but we will break it down a bit more succinctly here. The choice is between a “private offer” (negotiated price for pre-purchase of specific usage quantity) and “pay as you go”. Usage costs are based on:
- Databricks Unit (DBU), a unit of processing power on the Databricks Platform
- Cloud platform costs for compute/VM on AWS, GCP, Azure
What does a DBU cost? There are many variables involved that you can play with on their pricing page. But at the bottom end, it’s about $.10 per DBU, and at the top, $.70 per DBU. To further complicate matters, it is rare that a single DBU lasts for an hour. Your configuration could be burning 500 DBUs an hour at $.70 per DBU, thus costing about $350 per hour of usage. 1 DBU is the equivalent of Databricks running on an AWS i3.xlarge machine with the Databricks 8.1 standard runtime for an hour.
As with most services, to get attractive pricing in a private offer you may need commit to a minimum spend. Determining how much to commit to is difficult since the compute requirements are very workload specific. It’s best to run the actual workload at the PAYG price (no commitment) and use that to determine the proper commitment to make.
AWS Pricing for Databricks
If you are running Databricks in your AWS account, AWS charges for the compute resources you use at per-second granularity. This is in addition to what you are paying per DBU to Databricks. The Databricks page that describes those charges can leave you with the impression that everything comes for the one fee. For example, looking at the page, we see an AWS cost range of $.07 to $.70 per DBU used for AWS. Translation: The approximate Amazon fee for each DBU you use will be between that range. But it doesn’t include the DBU cost we just covered, which amounts to an additional $.10 to $.70 per DBU. Continuing with our previous example, if we were using 500 DBUs an hour at $.70 per DBU, we have $350 per hour for the DBU, but another $35 to $350 per hour for the AWS compute charges, for a total of $385 to $700 per hour.
Cost Factors When Using Databricks
As with an AWS EC2 instance, the variables for Databricks pricing start with how many virtual CPUs you allocate, along with the memory of the system. To that, you add in the number of clusters/instances you are going to make use of, the hours per day, and the days per month that you are running them.
You can see a quick guide to other considerations around cluster sizing in this video by Advancing Analytics:
Pricing Summary
As we can see, pricing can get tricky and depends on a lot of variables, but the equation looks like this:
- Total Cost = Cloud Cost + DBU Cost – defined as:
- Cloud Cost is: VM/compute hourly rate * hours
- DBU Cost is: (DBU Count * DBU Hour Rate) * hours
- Each Databricks VM/compute has its own DBU Count
Prices can also change by cloud instance region or by taking advantage of Amazon EC2 Spot instances.
Databricks Use Cases
What is Databricks used for?
Databricks works best as a data science tool and for ad-hoc exploration of large datasets (see our previous article on Apache Spark use cases). For data scientists who are well-versed in libraries such as PySpark, and who are accustomed to Notebook-based development, Databricks can be a good choice as it allows rapid prototyping and modelling against very large datasets. Once the ML pipeline has been developed, it can then be moved to production.
owever, when moving a pipeline to production, Databricks has some limitations that you should be aware of:
- Databricks is very Notebook-centric. Versioning and Git integration are supported, but it’s still not ideal in terms of CI/CD processes for production code.
- Running a large-scale job in Databricks can be significantly more expensive than running the same job in an alternative platform, such as Upsolver SQlake, Amazon Glue ETL, or your own managed Spark cluster on Amazon EMR. Again, Databricks cost is generally fine for prototyping; however, when the same pipeline needs to run continuously, pricing can get prohibitive and negate much of the cost savings associated with working in a data lake architecture.
Finally, Delta Lake offers a way to manage your data lake file system and perform updates and deletes on files stored in object storage.
Is Databricks a Good Choice?
As with most things, the answer is “it depends.” What follows is more food for thought to help your decision-making process.
Reviews
Looking around on G2 and Reddit for reviews from Databricks users, we see users generally reporting that while it does simplify much of the data lake, it is still a complex system to use, and the pricing is especially confusing. Some users complain the system is overkill for medium-sized businesses. Others feel that Databricks has vendor-locked them into their ecosystem and Delta Lake is really only a single vendor-supported open source project, so it might as well be closed source.
Why Companies Choose Databricks
- Already have Spark expertise and are looking to add to that ecosystem in an easier way
- Want simple access to their ecosystem for a specific function
- They have large, distributed datasets they want to work with
- Unaware of alternatives
Why Companies Don’t Choose Databricks
- Cost
- The “walled garden” aspect of their ecosystem
- More than they need
- Simpler options available
Alternatives & Competitors
There are a wide variety of open-source options available to replace components of Databricks. Lakehouse table formats you can use instead of Delta Lake include Apache Hudi and Apache Iceberg.
In the commercial space, there are some options available. Below are just a few:
Snowflake
Snowflake falls into the Data Warehouse category as opposed to Data Lakehouse. Snowflake is a fully SaaS solution that handles all of your data infrastructures automatically. Their environment can also be used for analytic, machine learning, and data science workloads, but of course you would be working with a data warehouse for better or worse.
Amazon EMR
EMR stands for Elastic MapReduce and is a suite of managed services for running big data frameworks. You can run Spark or Presto on EMR to perform many tasks similar to those in Databricks. In addition, EMR integrates with other AWS products for large-scale data processing, analytics, and machine learning.
Upsolver SQLake
Upsolver SQLake and Databricks are two choices to consider for building and running continuous workloads on your data lake. Databricks SQL Compute is a query service that can be used to query Upsolver tables. Databricks Notebooks can also run against Upsolver tables.
Upsolver offers a more efficient compute engine and is configured and operated entirely through SQL. This enables businesses to build data pipelines in distributed architectures, without struggling with the intricacies of writing Spark code in Java or Scala. To learn more and see an example of a stateful data lake pipeline, visit the SQLake product page.
Next Steps
- To learn more about building data pipelines, get the Free O’Reilly Report: Unlock Complex and Streaming Data with Declarative Data Pipelines
- To discuss best practices for modernizing your cloud architecture, schedule a call with an Upsolver solution architect.
- Read our previous article on reducing data platform costs.
Published in:
Blog
,
Cloud Architecture
