
Explore our expert-made templates & start with the right one for you.
Upsolver April 2024 Feature Summary
-
Rachel Horder
- Release Notes
- April 11, 2024
Welcome to the April edition of the Upsolver feature summary where we explore the enhancements and fixes we have implemented over the past month. Outwardly, it looks like a quiet month, as our engineering team has only provided me with a handful of issues to talk about. However, the team has been incredibly busy fixing a huge list of issues and bugs in the background, ensuring future features are built on a stable code base.
Incredibly, two months have passed since our Chill Data Summit in New York City, where we announced support for Apache Iceberg. The team worked like crazy to implement Iceberg support ready for the summit, and have since been fixing, enhancing, and making adjustments to ensure everything is working as expected. Many of our customers have been quick to implement Iceberg as the advantages of a lakehouse are becoming ever more apparent.
One of the talks at the Chill Data Summit was from Alex Merced from Dremio, who dived into the results of their State of the Data Lakehouse Survey 2024. If you haven’t seen this yet, I highly recommend you watch the recording. The cost savings to be made by adopting a lakehouse over on-prem and cloud data warehouses are extraordinary, and a big factor driving the rapid adoption of Iceberg. Survey respondents predicted that 69% of their data analytics will move to the lakehouse in the next three years, with over half expecting to see savings of more than 50%. It’s no wonder then that Iceberg is the hot topic of discussion in the data world right now.
Speaking of analyzing data in the lakehouse, we were delighted to be announced as PuppyGraph’s Data Movement Partner. PuppyGraph is a graph database that runs on data in the lakehouse or warehouse, so you don’t need to buy or build a dedicated graph database. This means you can get to the exciting and important part of visualizing your data in super fast time and without the hassle of configuring complicated systems. Upsolver was built specifically for high-scale data ingestion, so we are ideal partners as you can analyze petabytes of data with PuppyGraph.
But… back to the bug list, this update includes the following releases:
Contents
- Enhancements
- CDC Jobs
Enhancements
Enabled Sorting for External Iceberg Tables
External Iceberg tables are tables that you create with Upsolver or another tool, but are not used as a target for an Upsolver ingestion job. However, external tables can be optimized by Upsolver using our Iceberg Table Optimizer tool, which will compress files to free up space and speed up queries, as well as running tuning operations:
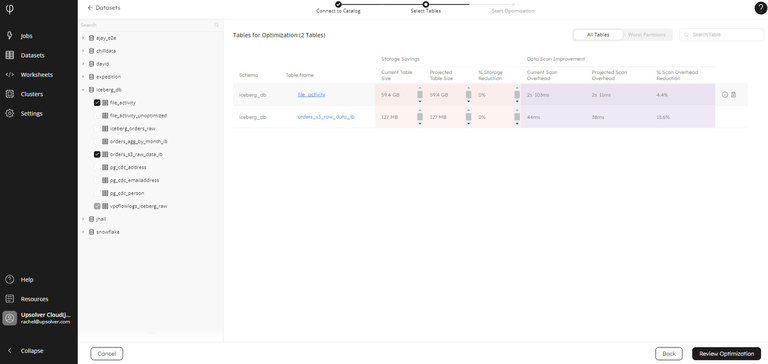
Adding one or more sort columns to your Iceberg tables can dramatically increase query performance in much the same way as adding an index to a table in a database such as Microsoft SQL Server, for example.
Sorting prevents the need for a table scan, as each file is sorted in the order of the specified columns, enabling the query engine to read only the files that satisfy the query.
If you have an external Iceberg table, we now preserve the sorting defined in that table during the compaction process when you run the Upsolver Iceberg Table Optimizer.
Check out the Apache Iceberg documentation to learn about sorting.
Support Sorting of Iceberg Tables with Files of Different SortIds
Further to the above enhancement to support sorting on external Iceberg tables, we have added support for when the sorting of the table changes, and the table’s sort settings increase the sort id.
Performance Improvements
The team has worked hard at improving the overall performance across the Upsolver platform, making a lot of changes under the hood. Hopefully you are noticing good response times as a result.
CDC Jobs
Fixed Incorrect Row Count in Snapshot Monitoring
During the snapshot phase, the monitoring tab would sometimes display an incorrect row count in the Replication Status column:
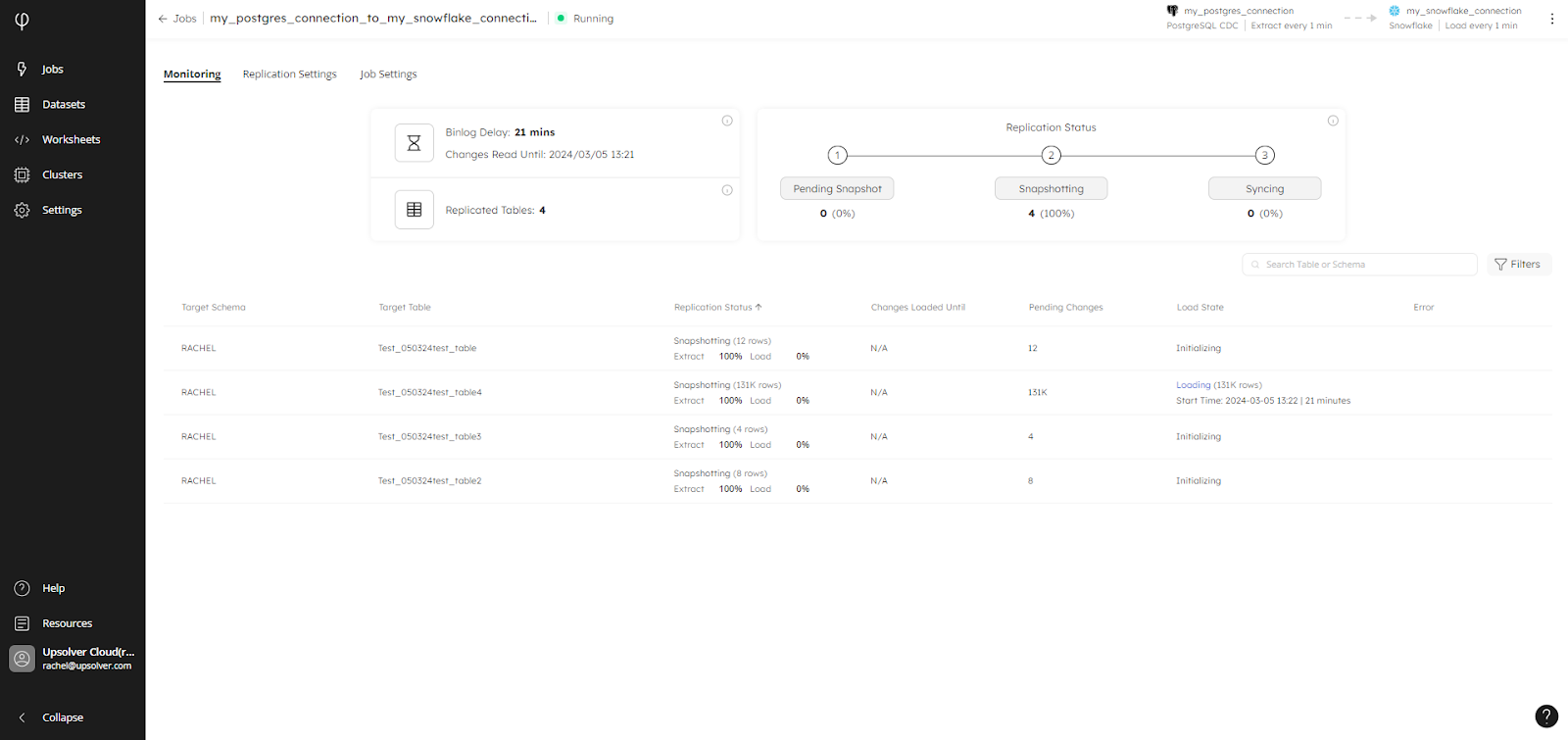
This has now been fixed and should display the right number of rows in each table.
That’s it for now, but I can share that coming in next month’s feature update is support for ClickHouse as a target for your data ingestion pipelines, and also the new data lineage feature.
So far, this year at Upsolver has been busy with a lot of new features and updates, so if you have any questions or would like to discuss your use case, please feel free to book a demo with one of the team, who will be delighted to give you a personal tour of Upsolver. See you next month!
Published in:
Blog
,
Release Notes