
Explore our expert-made templates & start with the right one for you.
Upsolver Announces Zero-ETL and Lakehouse Optimization for Apache Iceberg
-
 Upsolver Team
Upsolver Team
- Upsolver News
- February 6, 2024
Upsolver’s CEO, Ori Rafael, and CTO, Yoni Eini, opened the Chill Data Summit, Iceberg Edition, in New York City, an educational and informative event for data professionals embarking on their journey with Apache Iceberg. Hosted by Upsolver, the Summit was the perfect opportunity for Ori and Yoni to announce three new features in support of the open table format that Apache Iceberg is delivering to bring warehouse capabilities to the data lake. These features will enable data engineers to easily ingest data to Iceberg tables, and analyze and optimize tables within their lakehouse. Upsolver’s new capabilities will reduce storage costs while increasing data scans to improve query performance.

What is Apache Iceberg?
Apache Iceberg introduces a new open table format that brings database-like features to the lake, including transactional concurrency, support for schema evolution, and time-travel and rollbacks through the use of snapshots. By creating an industry standard, Iceberg’s open table format – which sits as a layer on top of the data lake – allows any engine to read from, and write to, Iceberg tables, without adversely impacting one another’s operations.
What is Upsolver?
Upsolver is a leading cloud-native data integration platform for high-scale workloads. We are on a mission to make open data lakes as easy and performant as data warehouses, which is the goal of the lakehouse. Inspired by our bad user experience with data lakes compared to the simple SQL experience we were used to in the warehouse or database, we wanted to bring a better experience to the lakehouse – while helping our customers save money.
Schedule a 1:1 meeting with one of Upsolver’s solution architects to see this integration in action.
Ingest Data to Iceberg with Zero-ETL
Upsolver makes ingestion from streaming, database, and file sources into the target system super easy, and we’ve added Apache Iceberg to the list of connectors we support. Quickly create robust pipelines to ingest high-scale data and benefit from automatic compaction and table management, meaning no manual intervention is required – Upsolver delivers a hands-off experience.
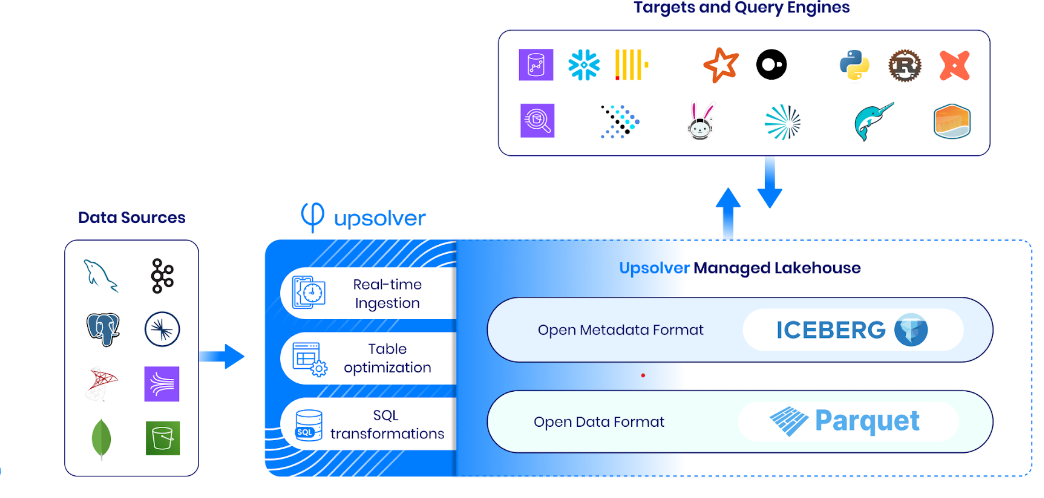
Learn how to get started ingesting your data to Apache Iceberg.
Introducing the Iceberg Table Optimizer
Data engineers who have already created a lakehouse and are ingesting data using an external tool can leverage Upsolver’s Iceberg Table Optimizer to manage their tables. Using a wizard experience, engineers can connect to their data catalog and select tables for analysis. Upsolver examines the partitions and uses industry best practices to calculate when to tune and optimize your tables.
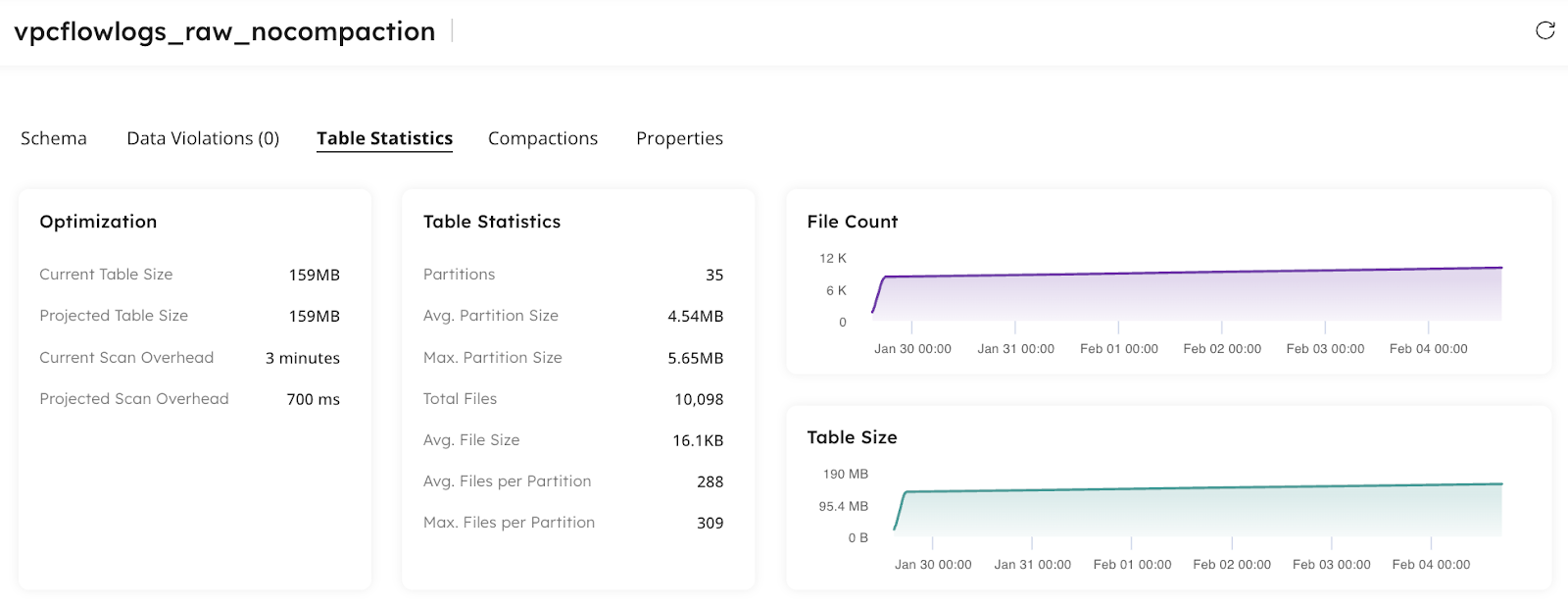
Read the step by step guide on how to run the Iceberg Table Optimizer.
Analyze Your Existing Lakehouse Tables
Upsolver’s open source Iceberg Table Analyzer CLI scans the files and partitions to show the current state of the table, and the benefits that can be achieved by running a compaction operation.
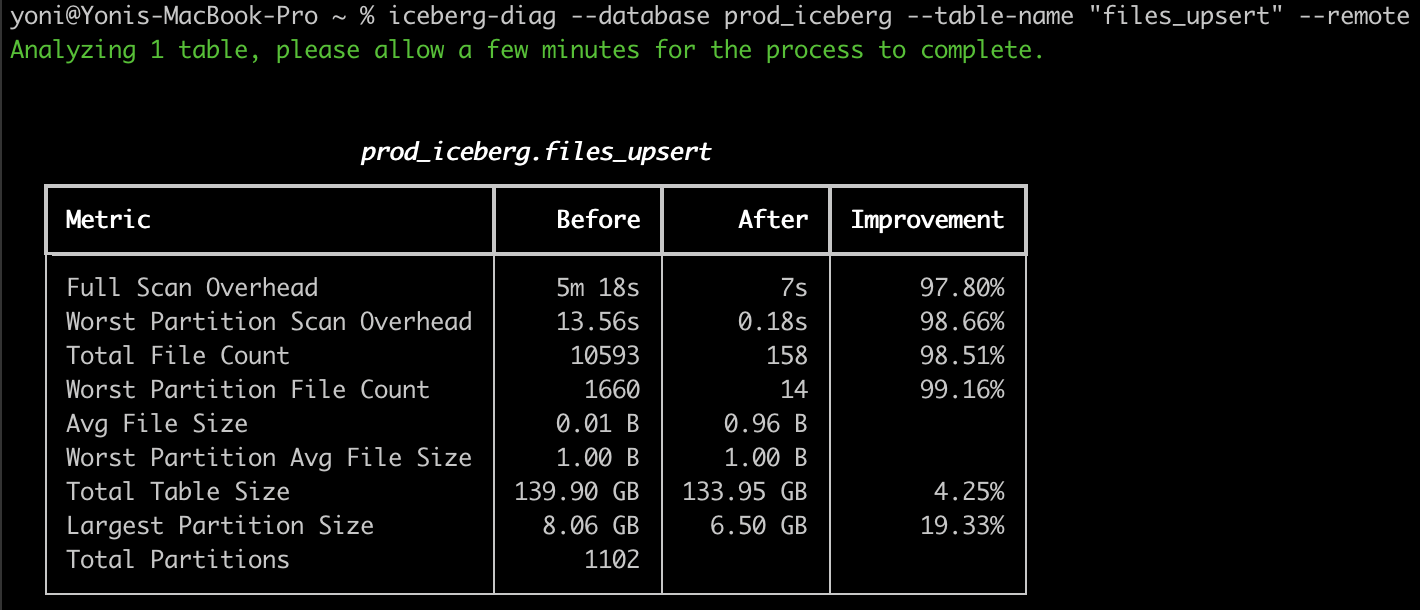
Discover how to use the Upsolver Table Analyzer to find tables that require compaction.
Ready to redefine your data journey? Embrace the future of Apache Iceberg and Upsolver today!
Schedule a quick, no-strings-attached demo with a solution architect, or get started building your first pipeline with our 14 day free trial.
Published in:
Blog
,
Upsolver News