
Explore our expert-made templates & start with the right one for you.
Ingesting Operational Data into an Analytics Lakehouse on Iceberg
-
 Rachel Horder
Rachel Horder
- Cloud Architecture
- February 27, 2024
Combining the best features of data lakes and warehouses, a lakehouse provides a unified architecture for optimized storage and querying of your data. Apache Iceberg, an open table format for big data, has emerged as the industry-standard for lakehouse architecture. In this article, we will explore the main limitations in turn of a data lake and a data warehouse for managing your data, and how a lakehouse combines the best of both worlds. We will then explore the process of ingesting your operational data into an Iceberg analytics lakehouse, which can also be adapted to other use cases such as machine learning and AI.
Ready to get technical? Watch our recorded workshop on Building an Iceberg Lakehouse with Spark and Upsolver, presented by Upsolver VP Product Roy Hasson. Watch the technical deep dive here
Limitations of Data Lake and Data Warehouse Technologies
It is common for businesses to have a lake for large-scale data science initiatives such as ML, and a data warehouse for business intelligence. Data lakes offer cheap and inherently scalable storage for any type of data, e.g. files, images, audio, vectors etc, but querying and managing the data is often slow and engineering-heavy, and can become a cost in itself that offsets the benefits of data lake architecture. It is easy – and common – for lakes to rapidly become swamps, containing disorganized files that makes data discovery and analysis difficult. As a result, BI users often depend on data engineers to prepare and format data to make it work with their reporting tools, killing off any hopes of data democratization within the business.
Querying data in the lake involves reading the list of directories, then reading the lists of files in each directory and sub folder. If a query includes a filter, each file must be opened to read the data to retrieve data matching the filter, and each file then needs to be closed. This can be a costly exercise on a large data lake as more compute power may be required to achieve adequate performance levels for larger queries, since a slow response time for BI reports can be harmful for the business.
Data warehouses remain popular because they store relational data that is already modeled for analysis and reporting on the business. The tradeoff with a warehouse, however, is vendor lock-in. Fully-managed cloud warehouses are convenient for businesses whose primary use case is BI. But because vendors for managed cloud warehouses use proprietary metadata and table management, accessing the underlying data becomes virtually impossible without use of the vendor platform.
Furthermore, data warehouses work best with relatively constant data, meaning significant development time is required to adequately handle evolving schema or otherwise changing data. Often, just adding an extra row or transformation to the ETL process can be tedious to achieve, requiring tools in addition to the warehouse platform, creating a bottleneck to the actual analysis.
A data warehouse was not originally designed for data that’s generated in large volumes or at a fast pace, and won’t perform cost-effectively under the pressures of the high scales of data that organizations are increasingly collecting. When ETL processes become too costly, such as for high volume or real-time data sources, the tendency is to discard the data as “irrelevant” even when, in actuality, it contains rich business insights. Take for instance interaction events written to the operational log of a product application. Without analyzing these events, we lose important insight into the user journey through our product. Yet, logs, especially from streaming queues, are generally considered to be a difficult data source that doesn’t belong in the business data warehouse. Prioritizing data sources based on the value of the data is far more effective than based on limitations of the warehouse infrastructure.
Finally, data warehouses are designed for batch updates to data, both for ingestion and transformations, lacking reactivity to schema changes, and the capability for in-flight processing. The data in warehouses may be clean and structured, but for many businesses, it is also out of date at the time of insight or report generation. For companies needing real-time data, for example for detecting fraudulent transactions, monitoring systems up-time, processing security logs etc., such a delay is simply not viable. Modern businesses that react and respond to social media trends, or fulfill food, taxi, or other bookings all depend on near real-time, fresh data, closing the gap between BI and product-led and/or ML use cases.
Why Apache Iceberg is a Good Option for Your Data Architecture
So how do we get the best of both the data lake and warehouse worlds, while leaving their limitations behind? We can use Apache Iceberg to create a powerful lakehouse platform for modern data management and analytics. With its hybrid architecture, Iceberg delivers the benefits of a data warehouse without the cost, complexity, and vendor lock-in, while utilizing the flexibility and low-cost storage advantages of a data lake. The resulting performant and scalable solution utilizes open formats for not just data storage but also table structure and management, making the data extremely portable and accessible from virtually unlimited query systems. Simply put, there is nothing secret about how your data gets stored, optimized, and managed, so you remain in control.
By adopting a lakehouse architecture, you can overcome the challenges of managing the files in your data lake with custom code. Lakehouse architecture enables real-time data ingestion and analysis, as the processing engine allows batch and streaming data flows to be ingested and queried in the same way, unlike in the warehouse. Your data can be accessed quicker than in a data lake, as Iceberg leverages columnar storage formats for excellent performance. Data updates are performed at the file level, rather than the directory level, and queries are accelerated with Iceberg’s schema-on-read approach. Iceberg maintains a metadata layer on top of the files in your lake, which includes the schema, inserts and updates, effectively creating a virtual table that users can query using SQL – just as if it were a table in a data warehouse.
Additionally, Iceberg includes compaction to reduce the number of files, thereby increasing the performance of data operations by decreasing I/O. This is especially beneficial for streaming data that generates a lot of small files that are inefficient to manage and query. Compacting these into larger files makes queries run faster. To top this off, Iceberg offers transactional concurrency, support for schema evolution, and time-travel. If you want to learn more about Apache Iceberg under the hood, check out the blog How Apache Iceberg is Reshaping Data Lake File Management.
Ingesting Operational Data to Iceberg
Since Apache Iceberg is the clear choice for the storage and management of high-scale data like that from operational sources, we’ve made it really easy to ingest such data and create a lakehouse in minutes. Below we show how to ingest data into Iceberg using simple SQL code in Upsolver, but you can also use our ingestion wizard for a super-fast, no-code experience to get started.
Steps to Ingest Your Operational Data to Iceberg
Step 1 – Configure Your Environment
Before you begin ingesting your operational data to Iceberg, ensure you have first configured your environment. Take a look at the official Apache Iceberg documentation to understand requirements and dependencies; then, check out this video from AWS Developers, Set Up and Use Apache Iceberg Tables on Your Data Lake – AWS Virtual Workshop, which includes a demonstration showing how to create an Iceberg table on a partition in your data lake using Amazon Athena. You also can create your Iceberg tables using Upsolver, as we’ll see in the following steps. If you haven’t already created your Upsolver account, sign up here for a free trial.
Step 2 – Create a Connection to Your Catalog
Upsolver currently supports AWS Glue Data Catalog and Tabular catalogs. In this example, we will be using AWS Glue Data Catalog, though the steps are very similar for Tabular.
Give your connection a name, and supply Upsolver with the AWS_ROLE, the DEFAULT_STORAGE_CONNECTION (the connection you created in Step 1), the DEFAULT_STORAGE_LOCATION for the directory containing the data files you want to ingest, the REGION where your catalog is located, and an optional COMMENT.
CREATE GLUE_CATALOG CONNECTION my_glue_catalog_connection
AWS_ROLE = 'arn:aws:iam::123456789012:role/upsolver-sqlake-role'
DEFAULT_STORAGE_CONNECTION = my_s3_storage_connection
DEFAULT_STORAGE_LOCATION = 's3://sqlake/my_glue_catalog_table_files/'
REGION = 'us-east-1'
COMMENT = 'Glue catalog connection example';
Your connection is persistent, so you won’t need to re-create it for every job. The connection is also shared with other users in your organization.
Step 3 – Create a Connection to Your Source
Upsolver supports the most popular database, streaming, and file data sources. We’re going to use Apache Kafka, which is a streaming data platform. Provide a name for your connection, and supply the HOSTS and CONSUMER_PROPERTIES for your server.
CREATE KAFKA CONNECTION my_kafka_connection
HOSTS = ('pkc-2396y.us-east-1.aws.confluent.cloud:9092')
CONSUMER_PROPERTIES =
'bootstrap.servers=pkc-2396y.us-east-1.aws.confluent.cloud:9092
security.protocol=SASL_SSL
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="XXXXXXXX" password="-----------";
ssl.endpoint.identification.algorithm=https
sasl.mechanism=PLAIN';
As with your catalog connection, your source connection will always be on, as Upsolver continuously streams data to your Iceberg table, which we will create in the next step.
Step 4 – Create an Iceberg Table
As previously mentioned, you can create Iceberg tables using Upsolver. When you create an Upsolver-managed Iceberg table, Upsolver automatically manages the compactions required to maintain the performance of your table. Creating a table uses similar syntax to creating a standard table in your data lake, but includes the ICEBERG definition in the statement:
CREATE ICEBERG TABLE my_glue_catalog_connection.my_database.my_iceberg_table()
PARTITIONED BY $event_date;
In the above example, we create my_iceberg_table without specifying any column names or data types. Upsolver will automatically detect the source columns and types and manage schema evolution for us. However, we do want to specify that partitioning is done on the event date. Upsolver creates the table in my_database, and uses my_glue_catalog_connection, which we added in the previous step.
Step 5 – Create a Job to Ingest Your Operational Data into Iceberg
The next step is to create an ingestion job. Upsolver includes an extensive library of functions and operators that you can use to build custom and advanced jobs for your use case. You can include expectations to control the quality of your data in-flight, and exclude and transform data, essential for processing personally identifiable information (PII).
The following is a very simple example to create a job to ingest our raw Kafka data into our new Iceberg table:
CREATE SYNC JOB ingest_kafka_to_iceberg_catalog
START_FROM = NOW
CONTENT_TYPE = AUTO
AS COPY FROM my_kafka_connection
TOPIC = 'orders'
INTO my_glue_catalog_connection.my_database.my_iceberg_table;
When you run the job, Upsolver starts the streaming process and your data will appear in your Iceberg table after a short while. Then Upsolver continues streaming your events and you can connect to your catalog using your query engine of choice. For example, check out the video How to: Create an Iceberg Lakehouse for Snowflake Using Upsolver, which demonstrates how to connect to your new Iceberg table from Snowflake, and view the data you have ingested with Upsolver.
Step 6 – Observe Your Data and Compaction Savings
When you create a pipeline, Upsolver provides a wealth of information to enable you to observe your data. In Upsolver, click into Datasets and select your table to view vital statistics. This information is built-in as standard, so you don’t need to write custom queries or build reports – it’s always up-to-date and available when you need it. Furthermore, anyone in your organization can access this data, enabling analysts who are building dashboards and reporting to have visibility into the content and structure. Datasets provide self-service diagnosis for anomalies or schema evolution that may impact downstream applications.
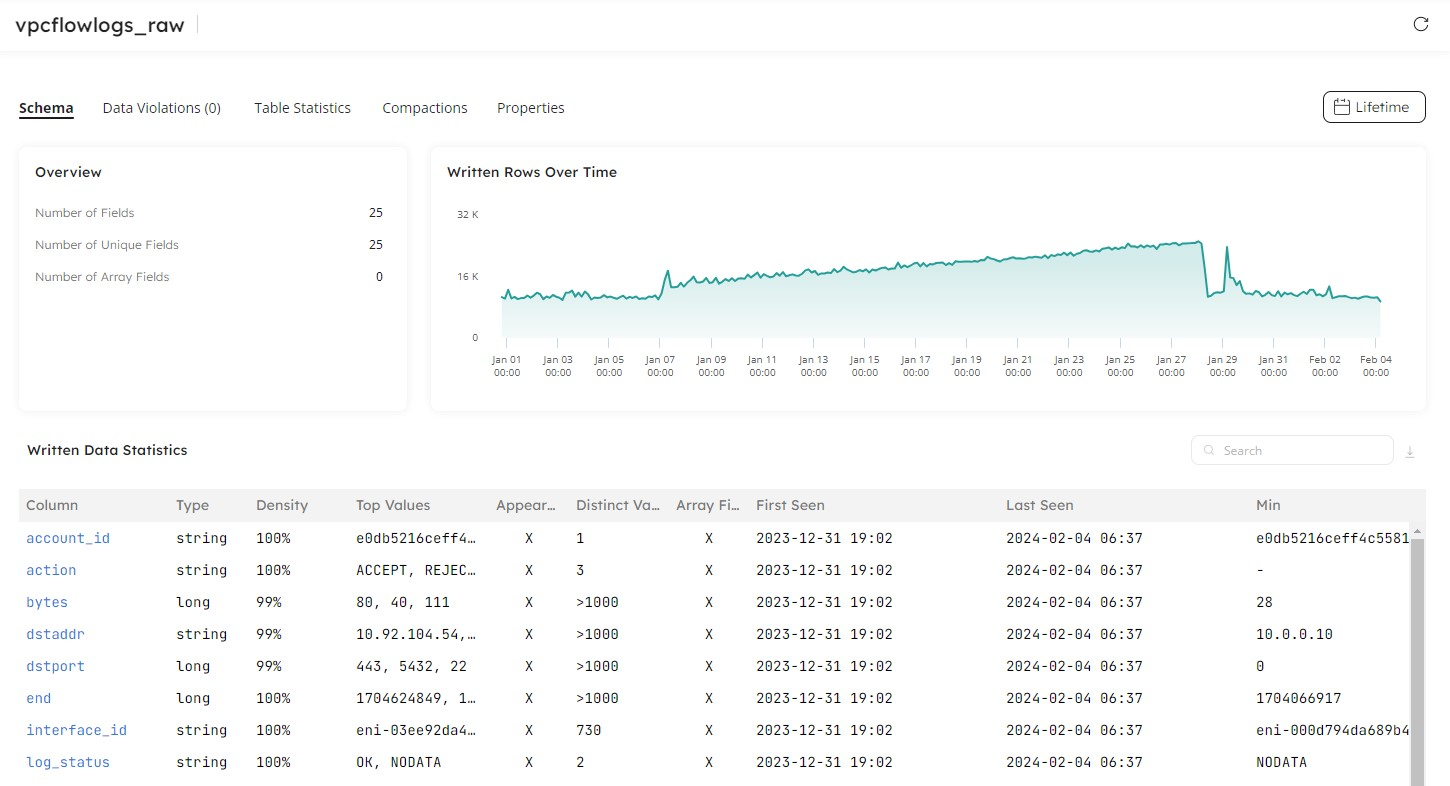
You can also monitor the compaction work that Upsolver handles automatically in the background. Choosing Upsolver to ingest your data to Iceberg means that you don’t have to worry about compaction. Using industry best practices, Upsolver gauges when compaction and tuning operations should best be run on your partitions, ensuring your queries remain performant, and your storage costs are as low as possible.
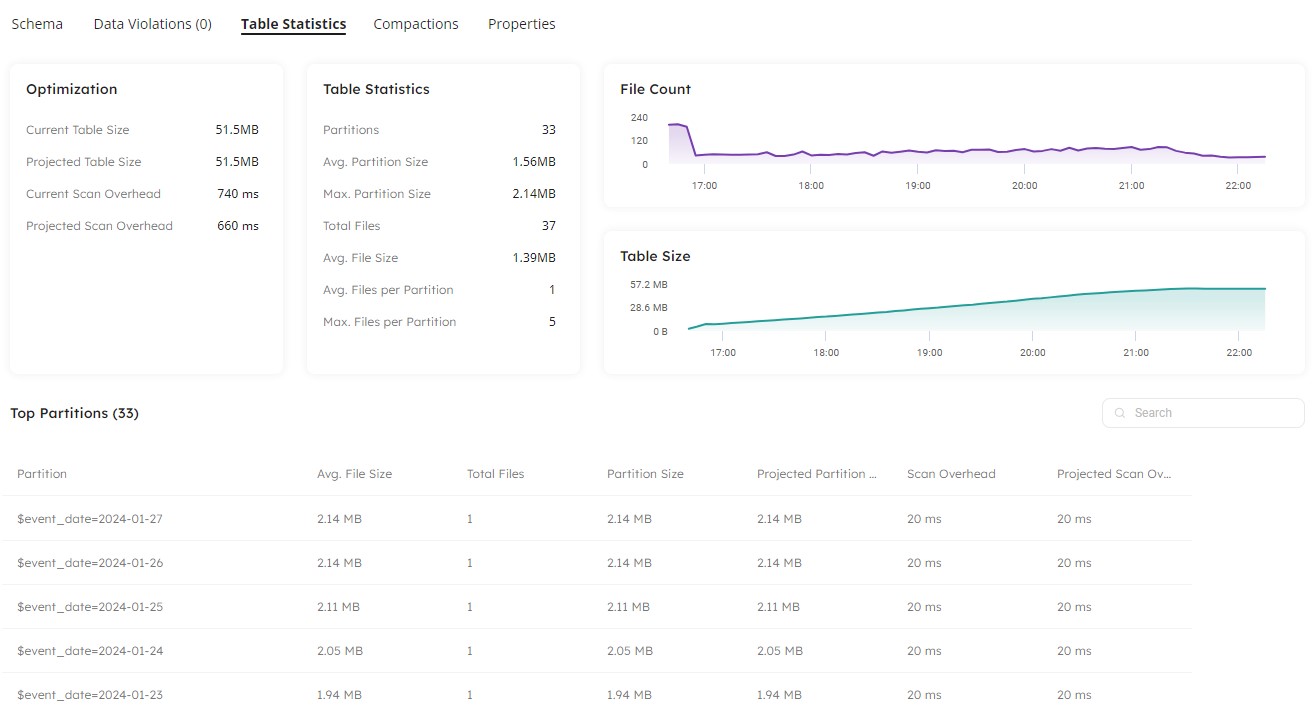
The Table Statistics tab in Datasets displays the before and after calculations for potential space-savings gains to be made from running a compaction. You will also discover calculations for determining the possible increase in data scans that can be achieved after the compaction process runs.
As with any data project, before deploying the operational data into production, thoroughly test the ingestion process in a controlled environment. Validate the integrity and accuracy of the data within the Iceberg table to ensure that it aligns with your expectations. Discover how you can use Datasets to observe your data and discover compaction benefits, and check for data quality. When you have your expected results, you can plan your deployment to production.
Summary
Iceberg is a rapidly maturing, revolutionary technology that enables you to combine the scalability and flexibility of your data lake with the data accessibility of a traditional data warehouse. By creating a dynamic metadata layer over your data lake, Iceberg delivers a SQL-like experience, enables concurrent transactions, and easily handles schema evolution.
If you’re planning to ingest your operational data into an Iceberg lakehouse, Upsolver offers a powerful solution for ingesting your data and maintaining performance. With full observability built-in to Upsolver as standard, you can monitor the quality and volume of your pipelines, enabling your data analysts to derive insights from diverse and real-time datasets without delay. Embracing Upsolver for ingesting your operational data, and Iceberg as your target, is not just a choice for today, it’s a strategic investment for future-proofing your analytics infrastructure for tomorrow.
If you’re new to Upsolver, why not start your free 14-day trial, or schedule a quick call with one of our in-house solutions architects who will be happy to show you around.
Published in:
Blog
,
Cloud Architecture
