
Explore our expert-made templates & start with the right one for you.
Introducing SQLake: Data Pipelines Without Manual Orchestration
-
 Ori Rafael
Ori Rafael
- Building Data Pipelines
- November 8, 2022
Upsolver SQLake, our new major release which has been in the works for two years, brings the benefits of stream processing to use cases once only possible with batch. It provides a single data pipeline platform that automatically turns simple SQL queries into production-grade data pipelines without any manual orchestration.
We’re also using this release to turn industry pricing on its head, with a simple and predictable pricing model. More about that later in this blog.
Data in Motion
Data is considered “data in motion” if its source continuously generates new data points that share a common schema. It can be click streams, security logs, payments, IoT sensor readings, or other sources that are usually delivered using event streams like Kafka, files on object storage, or updates to tables in operational databases.
The demand for utilizing data in motion is accelerating rapidly as companies exploit fresh data as a competitive advantage. To meet this need, organizations often turn to their familiar batch processing platform, trying to deliver data at a higher frequency.
The Path to Orchestration Hell – Applying Batch Processing to Data in Motion
Simply put, every data pipeline is composed of two parts: Transformation code and orchestration. If you run daily batches, orchestration is relatively simple and no one cares if a batch takes hours to run since you can schedule it for the middle of the night. However, delivering data every hour or minute means you have a lot more batches. Suddenly auto-healing and performance become crucial, forcing data engineers to dedicate most of their time to manually building Direct Acyclic Graphs (DAGs), in tools like Apache Airflow, with dozens to hundreds of steps that map all success and failure modes across multiple data stores, address dependencies, and maintain temporary data copies that are required for processing.
The attempt to shoehorn a 30-year old batch process into more real-time pipelines creates an orchestration hell that bottlenecks analytics development cycles and damages pipeline reliability. Every pipeline becomes a data engineering project, requiring “tender loving care” from engineers until it has proven to be dependable and scalable. Batch processing works great when the data flow is simple and freshness is not a factor (daily batches and one-to-one dependencies between jobs). But when you increase both the batch frequency (for example, from daily to under an hour) and the number of sources and targets, orchestration becomes 90% of the work.
To better understand why DAGs become complex in a world of data in motion, consider these scenarios orchestration must account for:
- How would you handle a recurring batch of 15 minutes of data when one batch takes 30 minutes to process?
- How would you handle cases in which some of the steps in your DAG completed and others didn’t?
- How would you create the monitoring and observability measures that are required to guarantee a data freshness SLA (that is, a data contract) to the business?
- How would you handle a join between two data sources in cases where one has late-arriving data?
- How would you throttle processing and compact many small files/updates for target systems that can’t handle your data in motion velocity?
- How would you safely “replay” pipelines using historical data (to fix data quality issues or retroactively test a research hypothesis) without losing or duplicating data (that is, maintain exactly-once consistency)?
- How would you create and maintain a processing state for data living outside the scope of the batch currently being processed?
There are some very experienced data engineers out there who can solve these problems, but is this the best use of their time? As a data engineer myself, I hope not. Data work – designing use-case-specific transformations – is clearly valuable to the business. Orchestration, on the other hand, is a necessary evil that shouldn’t constitute 90% of the pipeline development effort.
The Promised Land of Data Contracts
After we realized that good old batch processing wasn’t the right hammer for data in motion, we tried to imagine the future of data in motion processing by talking to a lot of data engineers and data consumers. The conclusion we reached is that all data pipelines will eventually become declarative. Users will declare the “data product” they want using a query that transforms a source schema into the desired output (that is, a data contract) and the data infrastructure will deliver to the contract specification. Orchestration, infrastructure management, state management, temporary data copies, and file formats are all examples of implementation details that will be inferred by the pipeline system, not manually defined using DAGs with hundreds of steps.
The promised land of data contracts is a sensible vision when you consider how a database query has worked for decades. When a user writes a query, the database automatically creates a query execution plan internally, in the form of a DAG, and runs it. No database user would consider building a query execution plan manually since that’s the role of the database query optimizer, a core component of the database. The only reason users manually build DAGs for pipelines is that the pipeline optimizer hasn’t been invented – well, until now.
What’s Holding Back Stream Processing Platforms From Replacing Batch?
Once we reach the conclusion that batch processing isn’t the future of data in motion, we look to streaming platforms, such as Spark Structured Streaming or Apache Flink, to take us to the promised land. However, there are several technical limitations that prevent these platforms from going mainstream:
They are too complex
Stream-processing platforms are code-based, so every pipeline is a project. Even if we slap a SQL wrapper on top, you are still running a process in Spark or Flink and you have to understand the internals of the system in order to debug and configure pipelines properly. This can be done by data engineers and only data engineers with that specific training. The result is that the vast majority of stream processing projects are just simple ingestion pipelines and not the more complex transformation pipelines that data consumers require.
Insufficient state management capabilities
Batches that run every few hours have the luxury of using the entire historical context while processing, but that’s not feasible for processing one event at a time. Streaming platforms are aware of the stateful processing challenge and they include a state store that provides historical context in milliseconds, but only at limited scale. These state stores are insufficiently powered to actually replace batch. A good example is the Databricks Delta Live Tables (DLT) documentation for streaming aggregation, which directs users to limit streaming aggregation to extremely low–cardinality fields such as country code.
“Simple distributive aggregates like count, min, max, or sum, and algebraic aggregates like average or standard deviation can also be calculated incrementally with streaming live tables. Databricks recommends incremental aggregation for queries with a limited number of groups, for example, a query with a GROUP BY country clause.”
Users are asking us about streaming aggregates supporting billions of keys, not 200! With such scale limitations, how can streaming platforms replace batch?
As always, a good engineer can solve any problem, and this one can be solved by attaching an external state store based on a key-value database such as Aerospike, Cassandra, RocksDB, or Redis. It can be done, but how can stream processing go mainstream if you need to stand up and maintain a separate key-value store to create a pipeline?
Again, stream processing ends up being limited to simple use cases, with batch processing the fallback for everything else.
You still need manual orchestration
Streaming eliminates the overhead of partitioning data into separate batches, which is great for one-step pipelines. But:
- it doesn’t solve the pain of multi-step pipelines that move data between several tables and need to be synchronized.
- it doesn’t solve error-handling with various success/failure modes
- it doesn’t solve data management tasks like compaction and vacuum. These require a separate manual effort but they are essential for every pipeline.
How SQLake Advances Stream Processing
SQLake was built backwards from a single “North Star” requirement: that users write a query and in return get a production-grade pipeline. To achieve this goal, every action that forces the user to do something else must be automated, with best practices enforced.
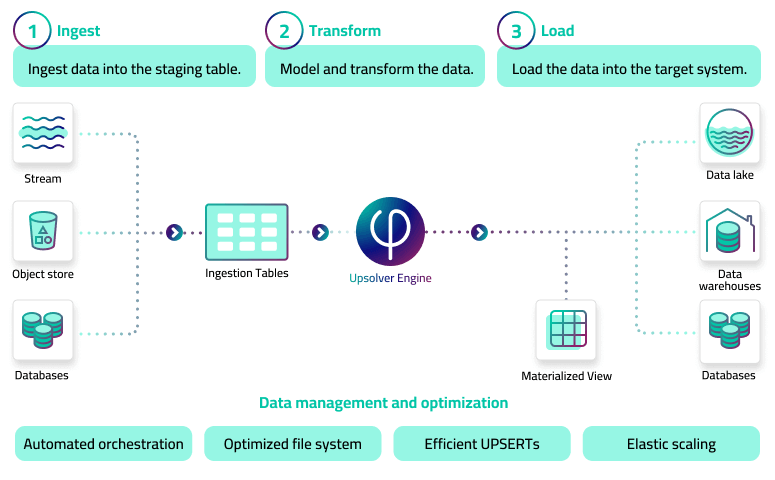
The SQLake development model uses SQL across three main entities:
- Tables
- Jobs that move data between tables
- Clusters that run jobs and auto-scale using ephemeral cloud compute (usually Spot instances).
Unlike any other pipeline platform, SQLake is integrated to the user’s cloud data lake, placing it in both the data movement and the data management categories.
The Orchestration magic
How SQLake handles orchestration is relatively simple, although completely derived from the product’s unique architecture. The first step of every SQLake pipeline is to strongly order the input data and store it in a data lake table for both SQL queries and additional processing jobs. When you create jobs that read from the data lake table, SQLake partitions the data in the input table into per-minute chunks and transforms each chunk as a processing task. SQLake then enforces the dependencies between the tasks using the timestamp in the input table. And it does this across a chain of jobs without human intervention.
This approach creates a deterministic flow of processing tasks that eliminate the need for manual DAGs. In addition to automatically orchestrating the processing job, SQLake also creates system jobs for data management. These jobs include:
- Schema updates to the target system based on changes detected in the data source.
- Compaction of small files for reduced processing overhead.
- Health metrics reporting.
- Cleanup of temporary data copies.
Without these system jobs, SQLake wouldn’t deliver on the vision of automatically turning queries into pipelines. The data management system jobs are the last mile for realizing the vision of “write a query, get a pipeline.”
Lastly, SQLake comes with a built-in decoupled state store that scales to billions of keys with milliseconds read latency without human intervention. The SQLake state store is an Upsolver breakthrough technology – think of it as applying the decoupled Snowflake architecture for key-value state stores – and it completely eliminates the overhead of managing a key-value database for pipelines. Its unique index compression also outperforms Spark’s native state store by storing at least 10X more data in a given RAM footprint.
SQLake is an Economics Game-Changer, Too
Not all barriers to building data pipelines for analytics are technical. Some are financial. To remove any hesitancy to trying out SQLake, we have used the launch as an opportunity to turn industry pricing on its head. SQLake’s cost model is simple and predictable: you pay only for what you ingest, transformation pipelines are free, and there is no minimum commitment.
Data platforms are usually priced in compute “units,” and are notorious for costs that are hard to decipher and that grow well beyond expectations. This is not surprising. How is it possible to predict cost in an environment with multiple users who write pipelines, using a wide variance in data modeling practices that dramatically influence processing efficiency, with software price increases doubling each time you need a larger instance?
So, we decided to disrupt data pipeline pricing to free organizations to fully exploit the value of their data in motion without worrying about the cost of every action they take.
SQLake pricing is plain and simple. Customers pay $99 per TB for the data they ingest (priced to the nearest GB). Transformation and output of data to one or more targets is free. There are no fees for added users, compute instances, rows processed or pipelines created. These are all unlimited!
For example, a data analyst using SQLake to write a dozen separate transformation pipelines using the same source data doesn’t incur any software costs beyond $99/TB of data ingested, and can therefore work without cost concerns. Of course this analyst would incur cloud compute charges from the customer’s cloud account where the Upsolver pipelines run, but Upsolver minimizes this cost too by using low-cost Spot instances. Normally, Spot instances cost 1.5%-5% of the same compute capacity in a data warehouse! For instance, an 8-CPU instance will cost $4-$8 per hour on one of the popular data warehouses and roughly $0.11 per hour on an AWS m5.2xlarge Spot instance.
What Next?
Upsolver’s vision is to accelerate the delivery of big data to the people who need it. With SQLake, we have advanced stream processing to the point where any SQL user can blend real-time and historical data within a single system and without entering orchestration hell. And with our new pricing we’ve removed the commercial barrier as well, so that users can build all the pipelines they want, while only paying once for the data they ingest.
Now that SQLake is out the door, we have many features and integrations planned going forward, including Apache Iceberg support, adding column expectations for improved data quality, visual job and column lineage, direct insert/update/deletes for manually refining data in tables, and more. We love hearing from our customers and community – so please share your roadmap feedback in our Slack channel.
Try SQLake – Unlimited 30-Day Trial
Try SQLake for free for 30 days. No credit card required.
Visit our SQLake Builders Hub, where you can learn more about how SQLake works, read technical blogs that delve into details and techniques, and access additional resources.
Published in:
Blog
,
Building Data Pipelines