
Explore our expert-made templates & start with the right one for you.
A scalable way to deliver NoSQL prod data to analytics environments
-
 Upsolver Team
Upsolver Team
- Upsolver News
- September 11, 2023

Data replication for data developers
Paging developers shipping prod data for analytics and ML: MongoDB, your favorite NoSQL database, is now supported as a change data capture (CDC) source in Upsolver! Easily export semi-structured and document based data from MongoDB at scale and ingest into Snowflake or a data lake. More details below—if you’re already familiar with MongoDB and CDC, skip ahead to section 2.
The challenge of MongoDB CDC
MongoDB: the database for scale
Renowned for scalability and flexibility, MongoDB is a popular NoSQL database that stores data in documents and collections, making it an ideal solution for applications that handle data in large volumes and need to scale at pace. However, with frequently-changing schemas and fluctuating data volumes, replicating this data into a data warehouse or lake for analytics and other high-value downstream use case is cumbersome and time consuming without the right tool.
Enter Upsolver.
Upsolver’s new MongoDB integration makes NoSQL CDC at scale quick, easy, and reliable.
But first, what is CDC?
Change data capture is a data integration feature that monitors, identifies and captures data changes in first-party application databases and delivers them to external systems, commonly for prod analytics. Changes include adding, updating and deleting the contents of rows or documents, and modifying the schema of a table or collection—all of which can happen during each user interaction with the application. Upsolver’s CDC functionality monitors such database changes, and sends only the updates to the destination, thereby optimizing the data transfer and reducing processing load. By performing this check every minute, data is delivered to the target in near real-time for all business-critical downstream use cases.
MongoDB CDC in Upsolver
How it works
Upsolver takes an unique approach to ingesting CDC data. By embedding the Debezium Engine into a fully managed service and transferring data directly from MongoDB change streams to a target like Snowflake or data lake, Upsolver eliminates the dependency on listening agents and message queues that would normally need to be configured separately for CDC. Removing the complexity of deploying and maintaining Kafka and Kafka Connect clusters frees you up to focus on higher-value work. With Upsolver, you simply configure your MongoDB source, set your target, and add desired in-flight data pre-processing. Launching the job then lets you monitor the pipeline, observe data flow, and validate the quality of data, all from the Upsolver UI (more on this in the next section).
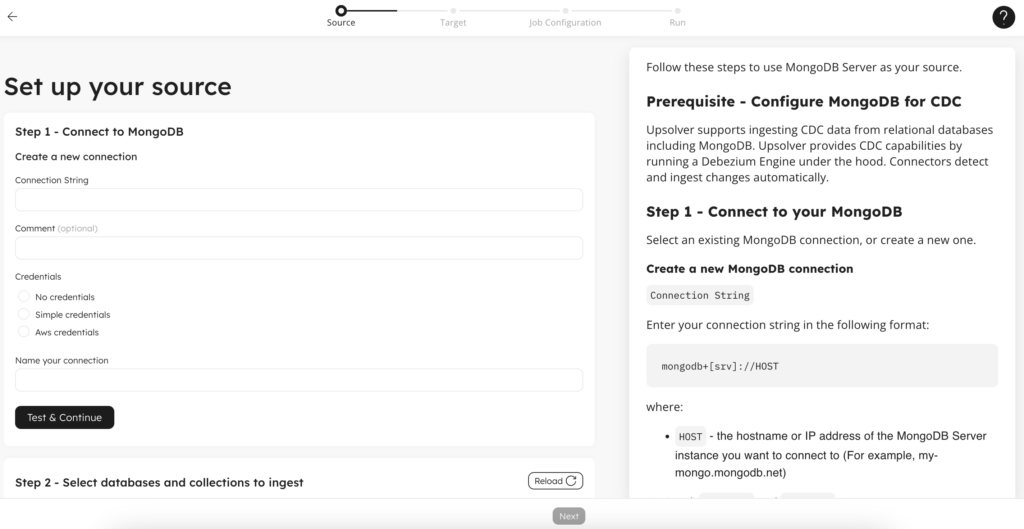
What you’ll perhaps enjoy even more than the simplicity of user experience is the host of features in Upsolver that natively resolve many of the more painful components of building data pipelines. Pipeline crashes can be left in the past, thanks to automated schema evolution. Upsolver automatically adds any new collections, documents, and key-value pairs in the source MongoDB database to the target—unless you tell it not to. The schema of your analytics-ready target data evolves at pace with your source application, even for deeply nested data structures.
Data observability
Observability and job monitoring features in Upsolver provide you extensive visibility into the actual CDC data and its health, bypassing the common tricky scenario of seemingly healthy pipelines that write bad data into the target. With field level statistics that are always up-to-date in the Upsolver UI, it’s quick and easy to gain insight into the volume, cardinality, density, uniqueness and several other attributes of the data.
Ready to get started?
Upsolver is proud to offer an affordable and transparent pricing model—particularly for high-volume data—comprising a fixed software fee and a data volume rate that’s one tenth the cost of other solutions on the market.
If you’re new to Upsolver, you can schedule a demo with one of our in-house architects to see how easy it is to ingest your prod MongoDB data into Snowflake or other destinations. Alternatively, get started immediately by creating your free trial account.
Existing customers can start ingesting MongoDB data today by simply logging into your account and launching the no-code wizard or writing a few simple lines of SQL to quickly create an observable MongoDB CDC pipeline.
Published in:
Blog
,
Upsolver News