Explore our expert-made templates & start with the right one for you.
Ingest, Process, and Analyze Amazon Web S3 Access Logs
Prepare S3 Access Logs for Analysis in 4 Steps
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Users can use S3 Access Logs to monitor and control how their S3 resources are being accessed. Analyzing these logs can provide valuable insights into user behaviors and can help improve security and compliance.
Let’s explore how SQLake simplifies the process of preparing and analyzing S3 Access Logs.
Using SQLake with S3 Access Logs
There are just four straightforward steps involved:
- Create the staging table in the data lake
- Create an ingest job to copy S3 server access logs into the staging table
- Transform and model the raw data storing results in the data lake
- Analyze your S3 access logs
Let’s walk through the steps.
- Create the staging table in the data lake
Staging tables are used to store a raw and immutable copy of the source data. SQLake automatically detects the source schema, infers data types, and updates the AWS Glue Data Catalog with the required metadata. It’s a best practice to partition your staging tables by the $event_date column, an automatically-generated system column based on the data when SQLake ingested the event.
CREATE TABLE default_glue_catalog.database_2777eb.Access_log_raw_data PARTITIONED BY $event_date;
- Create an ingest job to copy S3 server access logs into the staging table
Next, read the source data, convert it to columnar format, and insert into the staging table. The data is copied continuously, minute by minute, with SQLake automatically handling all aspects of table management (partitioning, compaction, cataloging, and so on).
CREATE SYNC JOB load_stage_s3_access_logs CONTENT_TYPE = ( TYPE = REGEX PATTERN = '^(?<bucketowner>.*?)\s(?<bucket>.*?)\s(?<requesttime>\[.*?\])\s(?<remoteip>.*?)\s(?<requester>.*?)\s(?<requestid>.*?)\s(?<operation>.*?)\s(?<requestkey>.*?)\s(?<requesturi>\".*?\")\s(?<httpstatus>.*?)\s(?<errorcode>.*?)\s(?<bytessent>.*?)\s(?<objectsize>.*?)\s(?<totaltime>.*?)\s(?<turnaroundtime>.*?)\s(?<referrer>\".*?\")\s(?<useragent>\".*?\")\s(?<versionid>.*?)$' MULTI_LINE = TRUE INFER_TYPES = FALSE ) AS COPY FROM S3 upsolver_s3_samples BUCKET = 'upsolver-samples' PREFIX = 'demos/blogs/access_logs/' INTO default_glue_catalog.database_2777eb.access_log_raw_data;
Since the source data is unstructured we must use a regular expression to parse the appropriate fields and associate them with a schema. The CONTENT_TYPE property enables you to define a PATTERN and also configure whether log lines are expected to span multiple lines. Furthermore, you can configure SQLake to infer the data types of each column; you can choose to disable automatic inference and manually cast each field to the appropriate type using a transformation job.
Here are the results when querying the staging table:
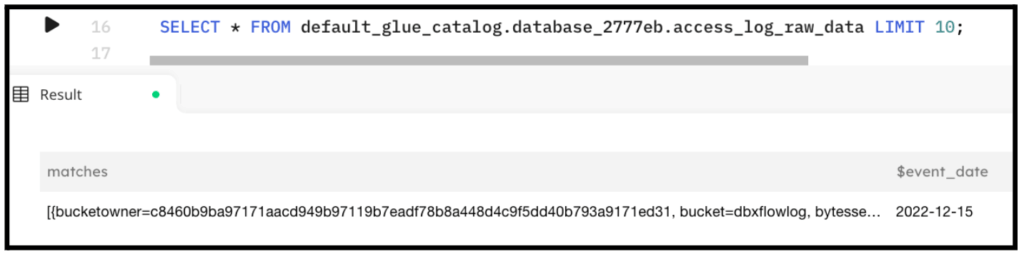
Below is a sampling of some of the most commonly used regular expressions:
- Transform and model the raw data storing results in the data lake
In this step you create a target table and a job that performs the transformations and writes the results to the target table. Once executed the job will continuously process data as it arrives. There is no need to define a schedule.
First, create the target table:
CREATE TABLE default_glue_catalog.database_2777eb.s3_access_log_flattened( dt date ) PARTITIONED BY dt;
S3 is often used by many different applications, especially in analytics. This translates into a large volume of requests. All of these requests are written to the S3 server access logs, which are delivered to your target S3 bucket as best effort. If you have a large number of buckets or a bucket that receives a high volume of access requests, you can expect many small files with a few log lines per file. The staging table you created ingests these small files, compacts them into larger ones, and stores them in the Apache Parquet columnar format that improves query performance. You can also choose to set an S3 lifecycle policy on your source S3 server access logs bucket to remove the small files, since SQLake is maintaining an optimized copy.
Next, create a transformation job to flatten and normalize the log data. Because we used a regular expression to parse the log lines, we are presented with an array of RegEx matches; each field in the array matches a field in the log line. We want to make it easier to use, so we’ll flatten it by using the UNNEST function. By using UNNEST, SQLake automatically explodes the array elements, enabling you to access them using the [] array notation.’
CREATE SYNC JOB load_s3_access_log_flattened
ADD_MISSING_COLUMNS = true
AS INSERT INTO default_glue_catalog.database_2777eb.s3_access_log_flattened
MAP_COLUMNS_BY_NAME
UNNEST (
SELECT
matches[].bucketowner AS bucket_owner,
matches[].bucket AS bucket,
matches[].requesttime_formatted AS dt,
matches[].remoteip AS remote_ip,
matches[].requester AS requester,
matches[].requestid AS request_id,
matches[].operation AS operation,
matches[].requestkey AS request_key,
matches[].requesturi AS request_uri,
matches[].httpstatus AS http_status,
matches[].errorcode AS error_code,
matches[].bytessent AS bytes_sent,
matches[].objectsize AS object_size,
matches[].totaltime AS total_time,
matches[].turnaroundtime AS turn_around_time,
matches[].referrer AS referrer,
matches[].useragent AS user_agent,
matches[].versionid AS version_id
FROM default_glue_catalog.database_2777eb.access_log_raw_data
LET matches[].requesttime_formatted = EXTRACT_TIMESTAMP(
substring(matches[].requesttime,2,20)
)
WHERE $event_time BETWEEN run_start_time() AND run_end_time()
);
Execute the job in SQLake and allow it a minute or two to process the data and begin to write results to the output table.
- Analyze your access logs
You can analyze the data by running queries directly from SQLake or using your favorite data lake query engine, such as Amazon Athena.
SELECT * FROM default_glue_catalog.database_2777eb.s3_access_log_flattened LIMIT 10;
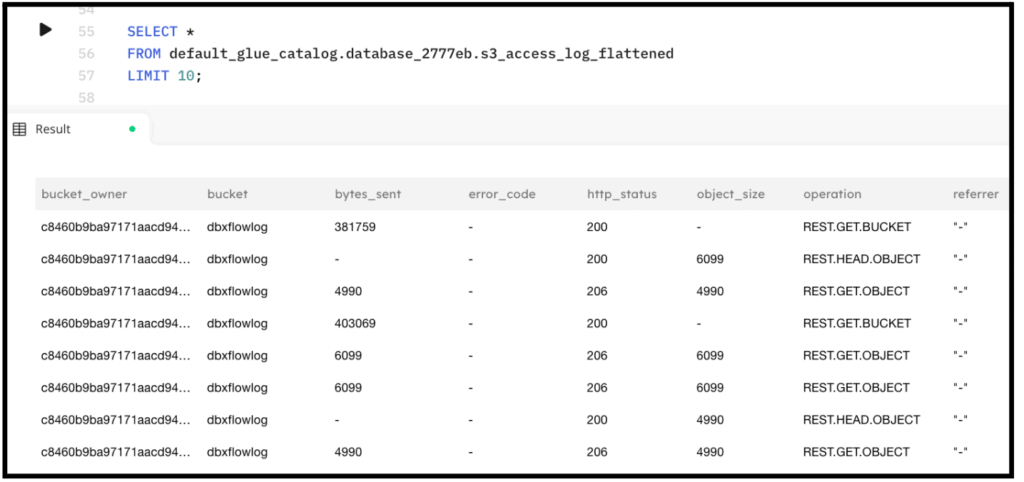
The following is a sample output from the above query executing in SQLake:
Summary
SQLake facilitates the parsing and analysis of S3 Access Logs, making it easier to ingest and analyze raw data from S3 buckets. With its schema inference, optimized data storage, and simplified querying process, SQLake enables you to gain valuable insights from your S3 access logs.
Get started for free today with sample data, or bring your own.
Discover how companies like yours use Upsolver
Data preparation for Amazon Athena.
Browsi replaced Spark, Lambda, and EMR with Upsolver’s self-service data integration.
Read case studyBuilding a multi-purpose data lake.
ironSource operationalizes petabyte-scale streaming data.
Read case studyDatabase replication and CDC.
Peer39 chose Upsolver over Databricks to migrate from Netezza to the Cloud.
Read case studyReal-time machine learning.
Bigabid chose Upsolver Lookup Tables over Redis and DynamoDB for low-latency data serving.
Read case study
Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products