Explore our expert-made templates & start with the right one for you.
Table of contents
Building pipelines easily
Upsolver reduces the time to build pipelines and place them into production from months to weeks. It does this by providing a visual interface synced to declarative SQL commands so that pipelines can be built without knowledge of programming languages such as Scala or Python. It also automates the “ugly plumbing” of table management and optimization which can absorb tremendous amounts of data engineering hours to get right.
Visual SQL Integrated Development Environment (IDE)
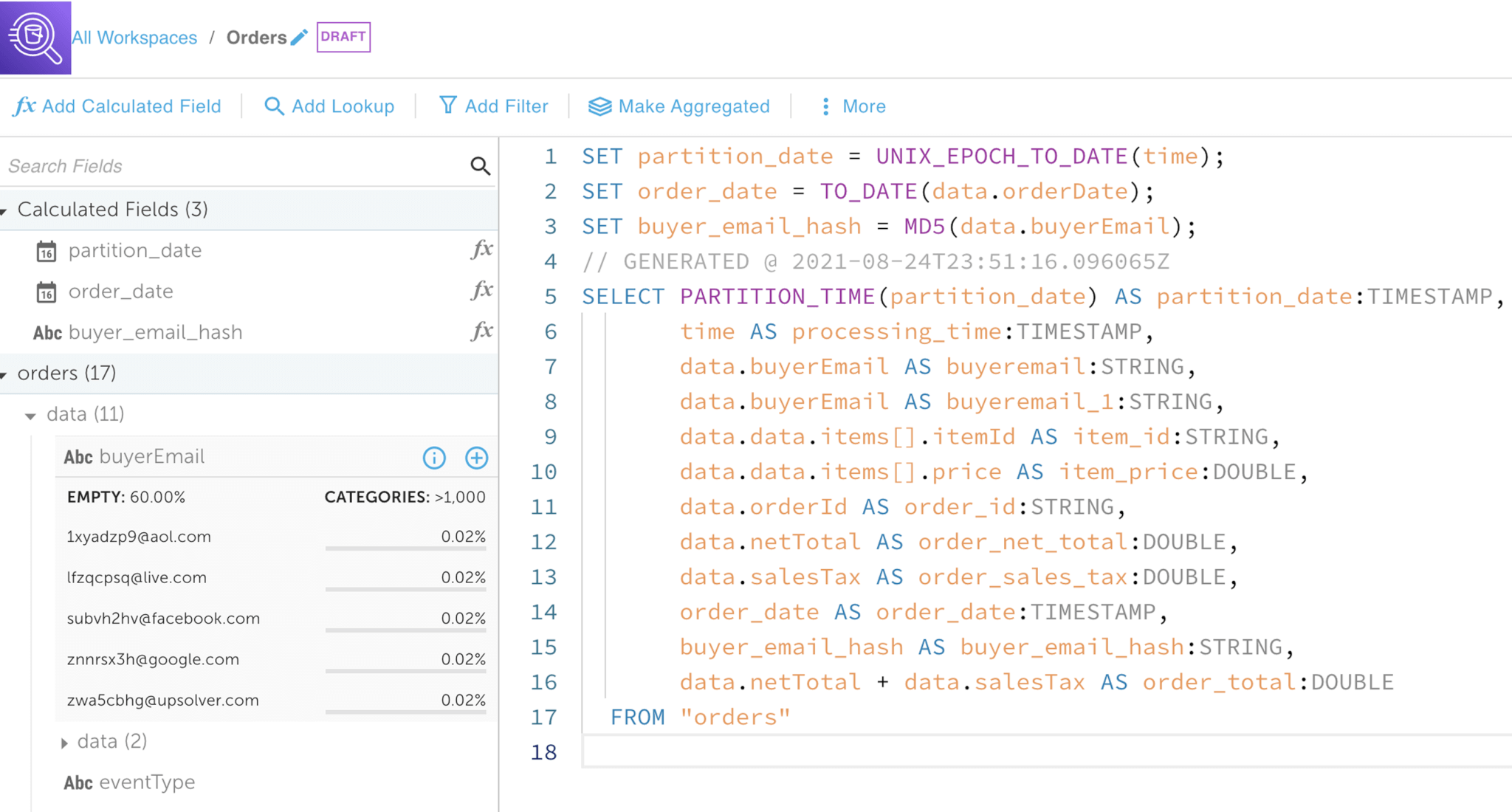
Design pipelines that ingest data, perform stateful transformations, and output to the data lake or external data store – all via a point-click experience, synced to editable SQL.
Upsolver provides a visual method for building pipelines and is synchronized with SQL commands that you can edit directly, without the need to write code in a programming language. You can use it to build pipelines that ingest data, read data from various streaming sources and data lakes (including Amazon S3, Amazon Kinesis Streams, and Apache Kafka), and writing data to the desired target (e.g. Amazon Athena, Amazon Redshift, ElasticSearch, and RDS).
The Upsolver UI is based on ANSI SQL so it is easy and intuitive to use for anyone with basic SQL knowledge. Users write regular SQL queries with extensions for streaming data use cases such as window aggregations, and the Upsolver engine continuously executes the queries.
Data engineers will appreciate the power Upsolver gives them, being able to easily perform any transformation they want, while those with less coding experience will appreciate the ease of use from being able to solve difficult data processing challenges with a combination of clicks and some SQL query editing.
All of the underlying data engineering tasks required for optimal performance on the data lake – such as compaction, vacuuming, and task orchestration – are handled automatically under the hood by Upsolver.
At each step, a single click switches you between the UI and SQL; and changes sync automatically between the two. Upsolver parses the data on read, and provides you with rich data profiling.
- Achieve time-to-value in days, making your data engineers more productive and shortening development time by 95%
- Enable self-service for 10x more users by relying on SQL rather than low-level coding in Scala or Python.
Schema-on-read/data profiling
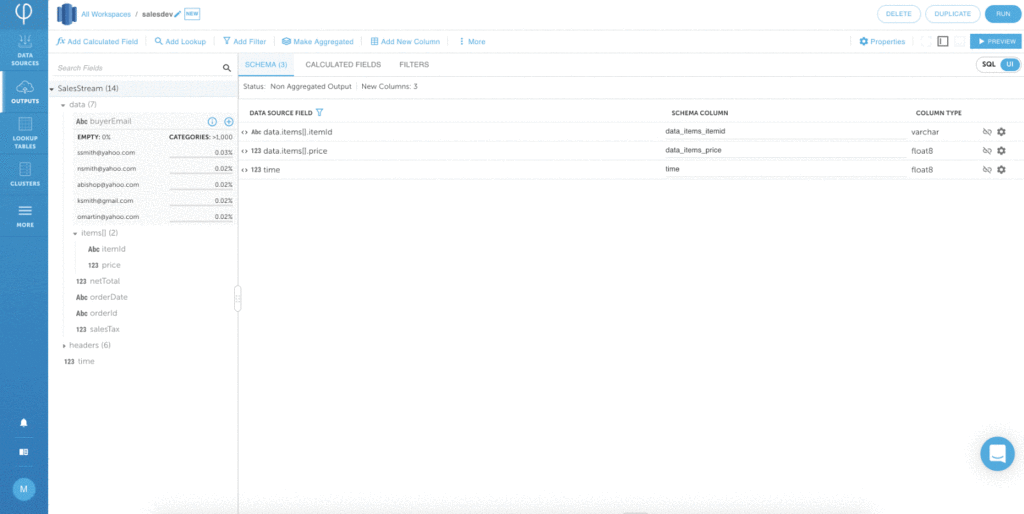
When you connect a data source, Upsolver analyzes the data and infers the schema. It visually displays the schema as well as important statistics about the incoming data. This provides you some top-level insights into the data that can help you decide on necessary transformations to get to the query-ready tables you require.
Besides the schema of the source, you can also view field statistics such as:
- Data density
- Cardinality
- Distribution spread of values
- Oldest and most recent record timestamps
- Count of keys
- Count of arrays
You can also view any parse errors during ingestion, view and export a sample of the data, and view which outputs are using the source (data lineage). You can monitor ingestion speed, latency, a prediction of ETA and errors. You can measure these properties over the entire lifetime of the source or filter for a specific window of time.
Learn more about the data source UI.
Learn more about schema discovery.
SQL-defined continuous stateful transformations
Upsolver lets you run complex stateful transformations at scale on your data lake – all without writing code. Joins, aggregations, nested queries, and window operations are all supported via Upsolver’s Visual SQL UI, which allows you to build transformation logic through drag/drop or SQL writing commands, with the 2 interfaces bidirectionally synchronized.
Upsolver’s SQL transformation on data streams removes the complexity of coding and orchestrating transformations and maintenance tasks. Upsolver SQL is ANSI SQL compliant, with extensions for streaming data use cases such as window aggregations, so it is easy and intuitive to use for anyone with basic SQL knowledge. The Upsolver engine continuously executes the queries and maintains the consistency of output tables.
Some common operations you can use include
- WHERE for filtering data
- JOINs on data from multiple sources or streams
- GROUP BY aggregations
- Time-related operators for streaming data such as WINDOW, ALIGN, WAIT and MAX DELAY
Upsolver also supports over 150 SQL functions and supports user-defined functions. Upsolver supports arrays as well as nested arrays natively.
REST API
If you prefer a programmatic interface for specifying your pipelines, Upsolver’s REST API enables you to manage all Upsolver’s infrastructure as code and complete any operation available in the Upsolver IDE, including creating and modifying data sources and outputs and implementing transformations.
Upsolver’s fully managed architecture does not require a dedicated API Servers. It utilizes the Global API Server to interact with Upsolver. In a Private VPC deployment, the API Server is required to be deployed in the user’s private VPC. The users will need access to the API Server to access the website. The API server will typically have the HTTPS port open for the users to access through a component such as VPN.
Learn more about Upsolver components.
Replay from previous state
Since Upsolver retains your raw data on the underlying cloud object store, you can “time travel” to a previous state and replay new logic. This is useful for inspecting the previous state of your data, for validating analytics hypotheses using historical data and for operationally fixing data quality issues using newly-defined logic.