Explore our expert-made templates & start with the right one for you.
Replicate MySQL or PostgreSQL DBs into your Cloud Data Lake in 3 Simple Steps
Make your databases instantly available for analytics with Upsolver.
Free forever Community Edition
Your MySQL or PostgreSQL tables in S3 or Azure Data Lake - Instantly
With out-of-the-box support for all major cloud and on-premise MySQL or PostgreSQL deployments, Upsolver makes replicating your databases to your data lake a breeze.

Seamless Change Data Capture and Database Replication
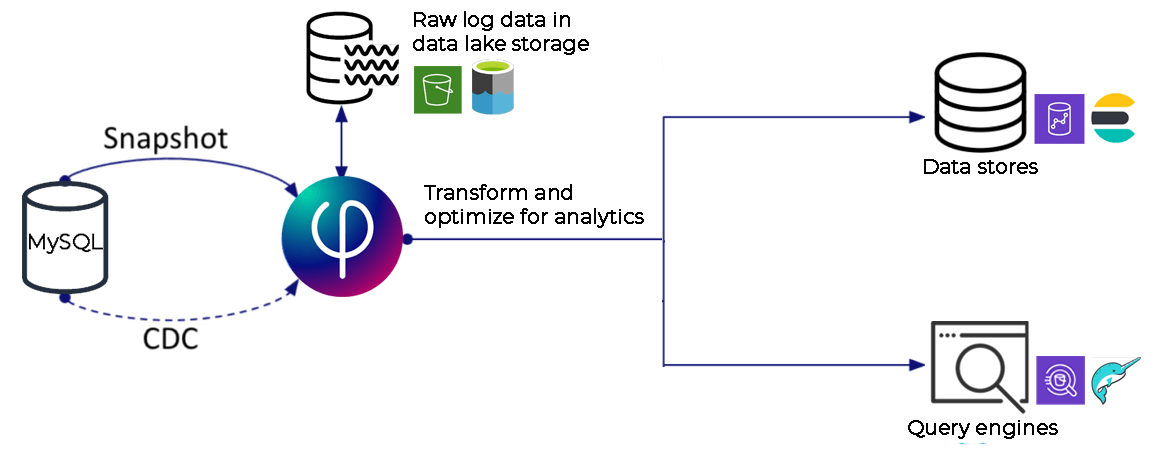
On-prem and cloud-based transactional and operational databases are an important source of data needed for data science, machine learning and ad hoc analytics. The best way to maintain an up-to-date replica of these databases in your cloud data lake is to create a log-based CDC (Change Data Capture) pipeline that migrates an initial snapshot of the data and then monitors and streams changes from the source database log to keep the copy in sync with the original.

How Upsolver's CDC Solution works
Upsolver’s CDC connector lets you continuously replicate any on-prem or cloud MySQL or PostgreSQL database into your AWS or Azure data lake in a few simple steps, and without writing code. Upsolver replicates a baseline snapshot of the source database and then keeps it up to date by monitoring the transaction log and replicating changes as they occur.
This data can be accessed by query engines, or output to external data stores such as your cloud data warehouse.
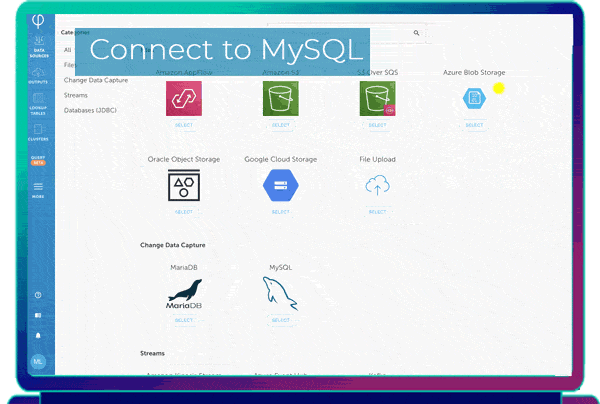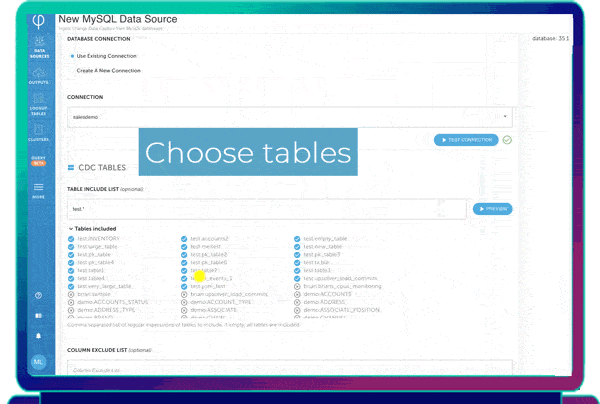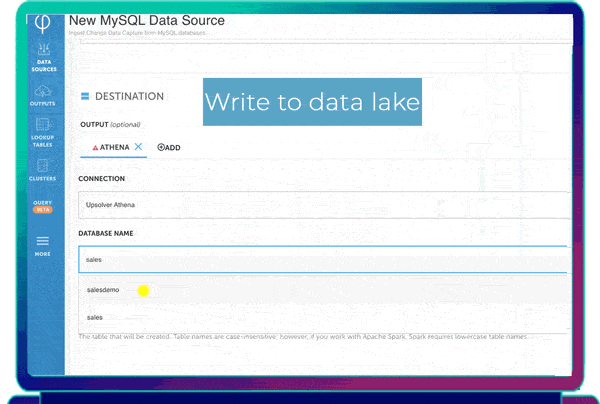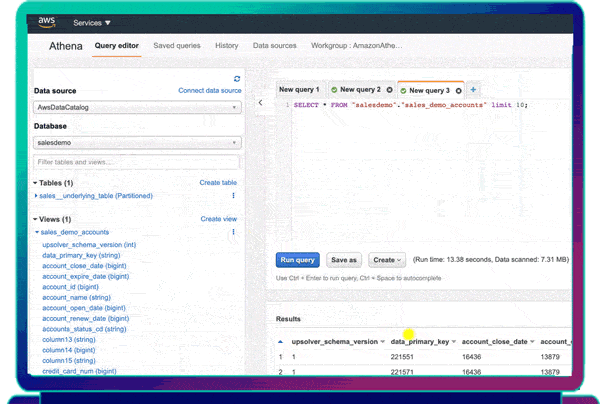
Connect your MySQL or PostgreSQL database
Continuously stream CDC logs from any on-prem or cloud MySQL or PostgreSQL database - including Amazon RDS , Azure MySQL or PostgresSQL, or MariaDB
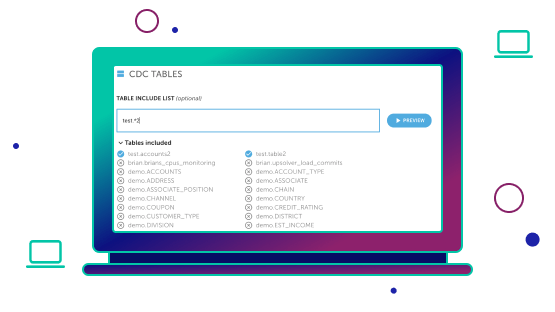
Configure the replication pipeline through Upsolver’s Visual SQL IDE, where you can select one, some or all tables to replicate. You can also apply filters, aggregations, joins and any other transformations you’d like to the incoming data.
Your data lake tables are continually kept in sync with your source database reflecting new rows, UPSERTs and schema evolution.
Replicate and Transform
Select the tables you want to move with point-and-click, transform your data, and write optimized Parquet to your data lake
Select the tables you want to move, then build transformation logic using our Visual SQL IDE which allows you to use drag-and-drop or edit SQL directly, with the two systems staying in sync.
- Continuously execute joins, filters and aggregations on CDC data as it arrives
- Dynamically split tables based on a key field
- Replay from any historical state
Automatic Performance Optimization
Upsolver automates data lake engineering best practices, saving you the time and trouble of hand-coding and configuration of distributed systems.
- Conversion to Parquet columnar format
- Continual file compaction
- Data partitioning
- Workflow orchestration

Query Data your Way
Leverage your open data lake architecture to choose the best analytic engine for the job
By leveraging open standards in a data lake, you can choose to query data directly from tables in the data lake or distribute the prepared data out to the systems of your choice.
- Query your database replica on your data lake using a SQL engine like Athena, Dremio, Starburst or your CDWs external tables feature (Redshift Spectrum, Snowflake external table).
- Prepare and continuously output tables to data stores such as Snowflake, Redshift and Synapse. Data lake UPSERTs ensure prepared output tables are always in sync with the source data.
- Execute lookups in milliseconds using Upsolver’s built-in key/value store
Become a Database Replication pro with our Free Resource Bundle
Whether you’re already replicating databases into your data lake, evaluating or just looking to increase your professional knowledge – this Education Pack is for you.


Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products