Explore our expert-made templates & start with the right one for you.
SQL data transformation
July 13, 2020
Before starting to transform your data, you must have already deployed Upsolver and created a data source.
Upsolver’s SQL transformation on data streams removes the complexity from traditional data pipeline transformations and orchestrations. Upsolver SQL is ANSI SQL compliant, so you don’t have to learn special syntax to get started. It is easy and intuitive to use for anyone with basic SQL knowledge. Users write regular SQL expressions with extensions for streaming data use cases such as window aggregations. The Upsolver engine will continuously execute the queries.
Let’s get started.
Create an AWS Athena data output
1. Click on OUTPUTS on the left and then NEW on the right upper corner.
2. SELECT Amazon Athena as the data output.
3. Give the data output a name and select your data source and click on NEXT.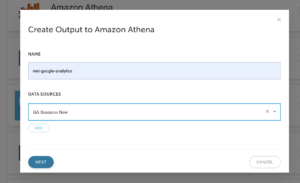
Data transformation using SQL
1. Map your input fields to output fields by click on the + sign next to the field. Or directly go to the SQL page. Keep in mind that everything written in SQL will be automatically translated in the UI and everything changed in the UI will be reflected in SQL.
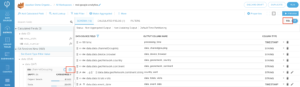
2. Use TO_DATE function to parse out the YEAR() and MONTH() from the DATE STRING.

3. Use TO_NUMBER to convert STRING to NUMBER for calculation.
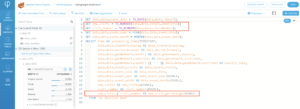
4. Use || to concatenate values from two fields together.
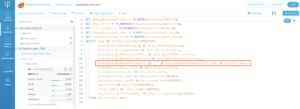
5. Click on PREVIEW to ensure your data looks correct
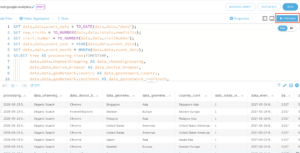
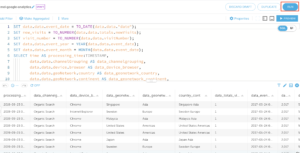
6. Click on RUN to input your AWS Athena information
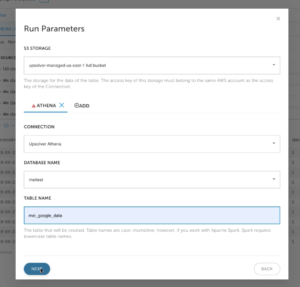
Configure AWS Athena run parameter and data output information
1. Enter S3 STORAGE that the Athena table will be utilizing. Also CONNECTION, DATABASE and TABLE information for your target Athena environment. Click on NEXT.
2. Enter the run parameters for your data set. Pick the COMPUTE CLUSTER that you want to utilize. Also the time interval for the data to be loaded to Athena. Click on DEPLOY.
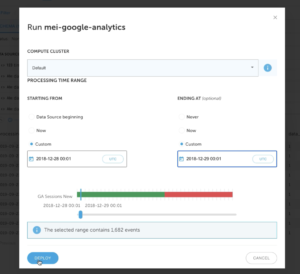
3. Monitor Current Status and wait until the data competes loading.
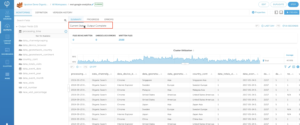
Verify loaded data from AWS Athena
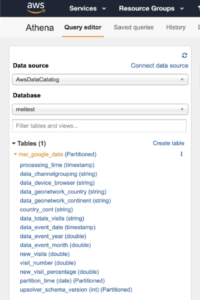
1. In your Athena environment, make sure the table is created correctly and data types are as expected.
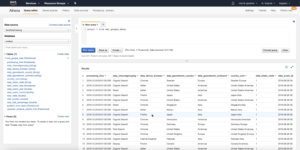
2. Run a simple SELECT query to make sure the data loaded to Athena correctly.
What’s next?
Find out how to combine multiple data sources together and perform transformations on the combined data set.