Explore our expert-made templates & start with the right one for you.
High-Scale* Data Ingestion
for Snowflake and AWS Data Lakes
Upsolver delivers production data (CDC, event streams) to your analytics users.
* Upsolver moves 25 petabytes of data every single month. That’s 35 gigabytes every second!








A different breed of data ingestion tool
There are (too) many data movement tools out there. Upsolver is the go-to solution to extract, transform, and load large volumes of production data in cloud-native environments. For other problems there are other solutions.
We compete on scale, not connectors.
✅ Use Upsolver for:
→ Moving data into Snowflake or your AWS Lakehouse (Athena + Glue)
→ Replicating production databases (Postgres, MySQL, MongoDB)
→ Ingesting Kafka / Kinesis streams
❌ Upsolver isn't for:
→ Moving data between clouds or onto on-prem / legacy data warehouses
→ Extracting data from third party applications (e.g., Facebook Ads)
→ Running small batch transformations
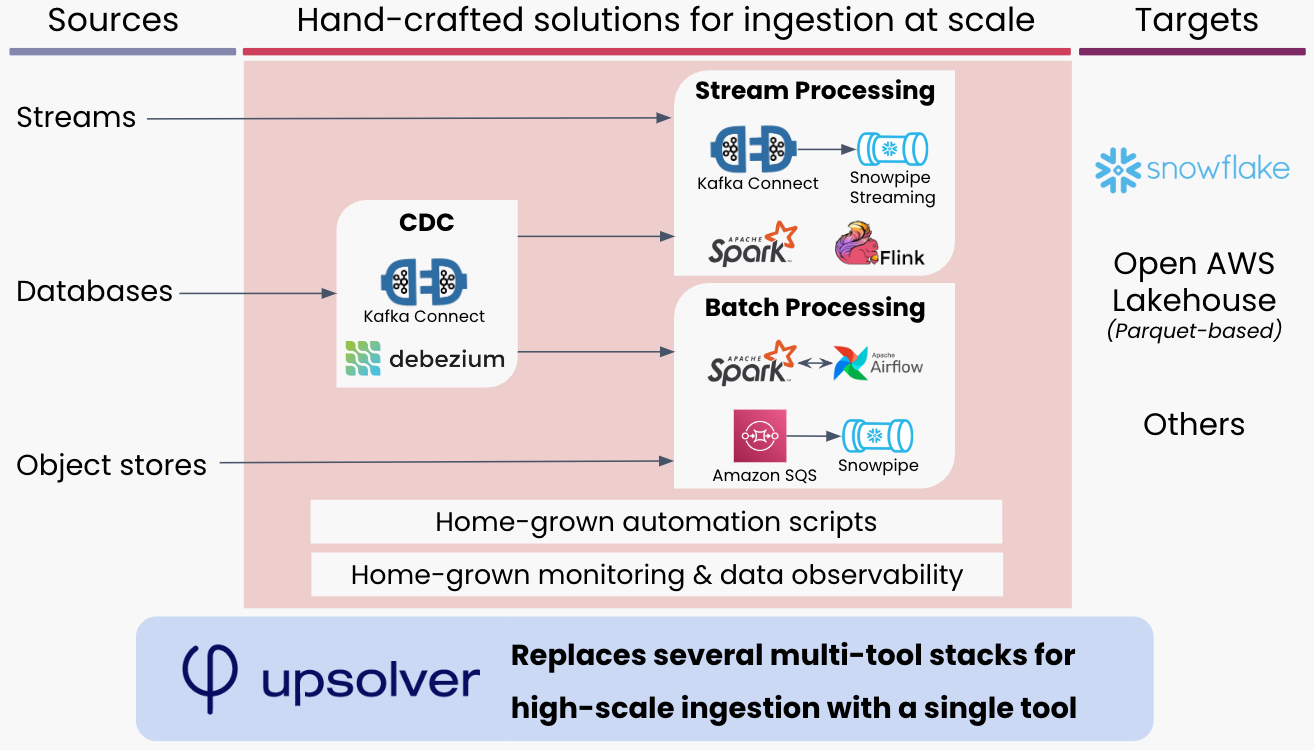
Extract and load at any scale, without DIY complexity
High-effort, low-value data engineering work is keeping your moat data from generating value. Upsolver replaces that work with a single tool that extracts data from prod and loads it into analytics environments, without developer intervention.
Choose-your-own-code pipelines
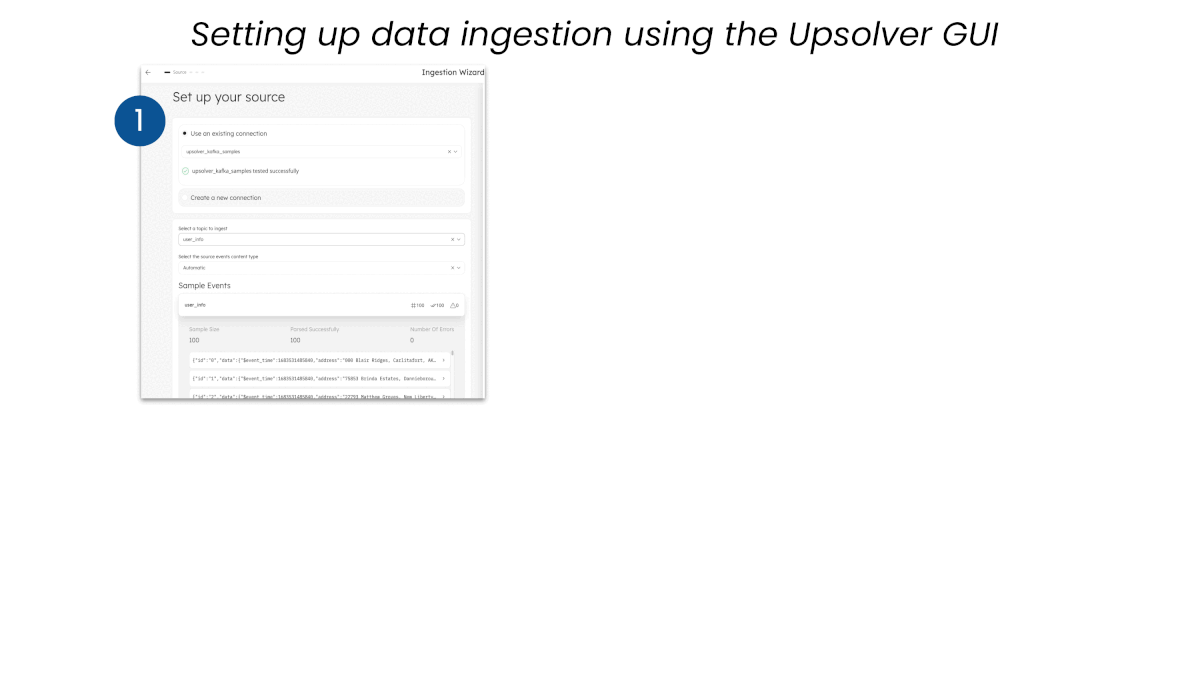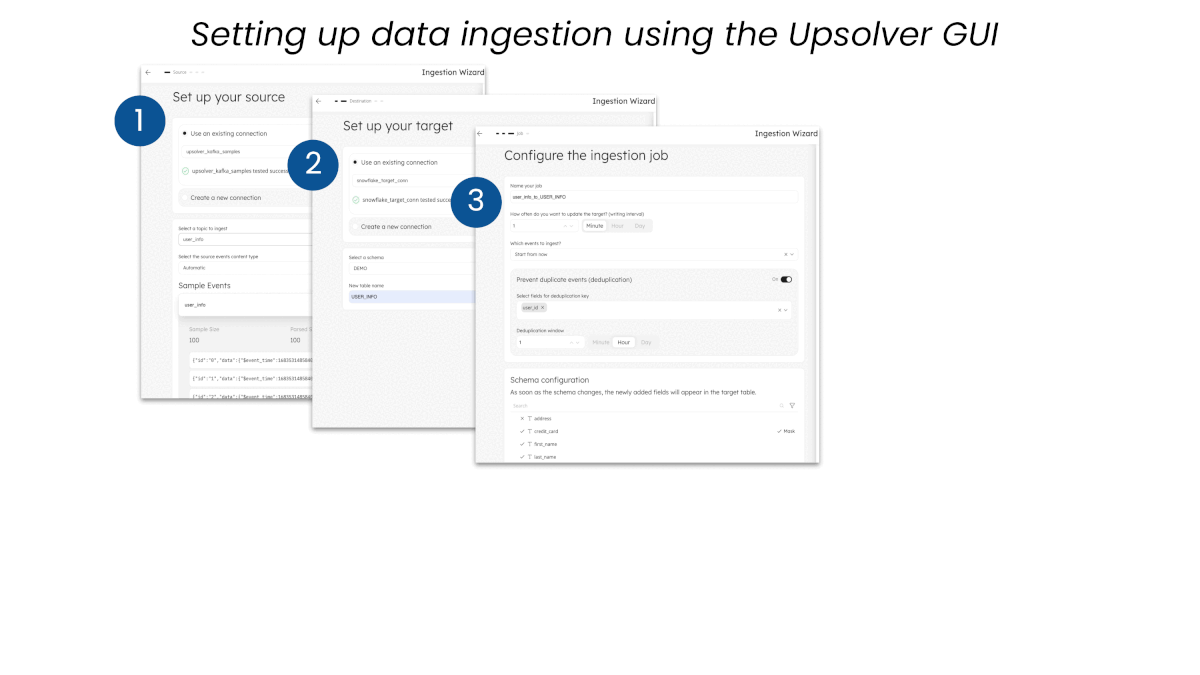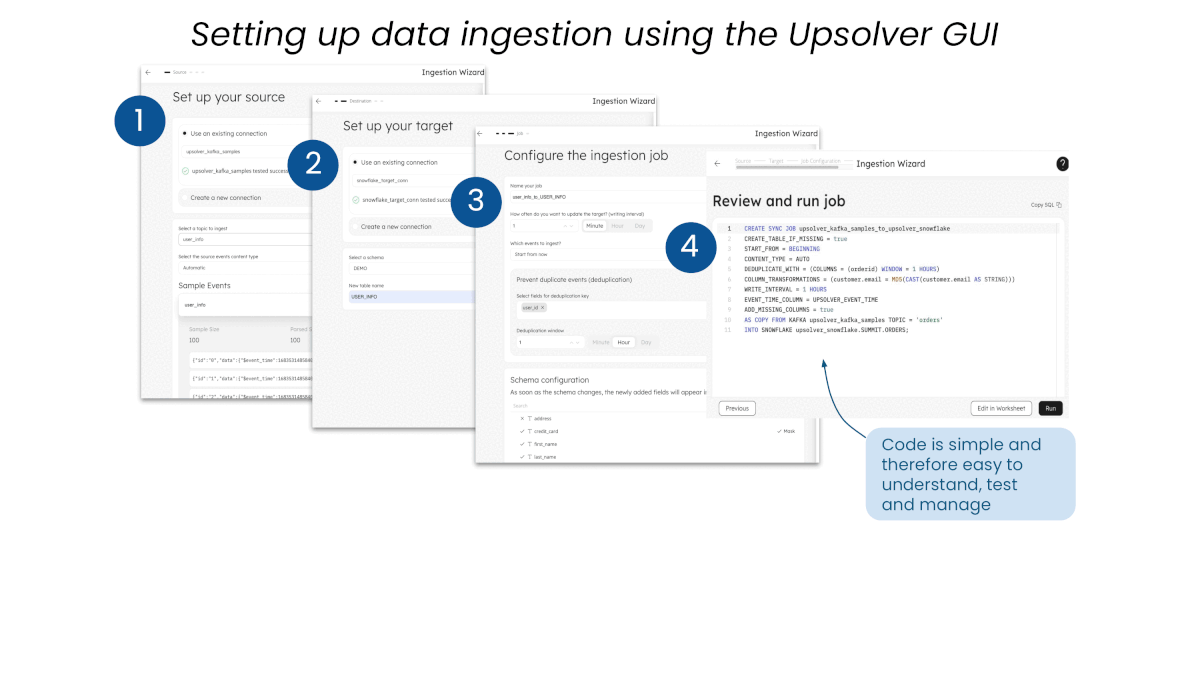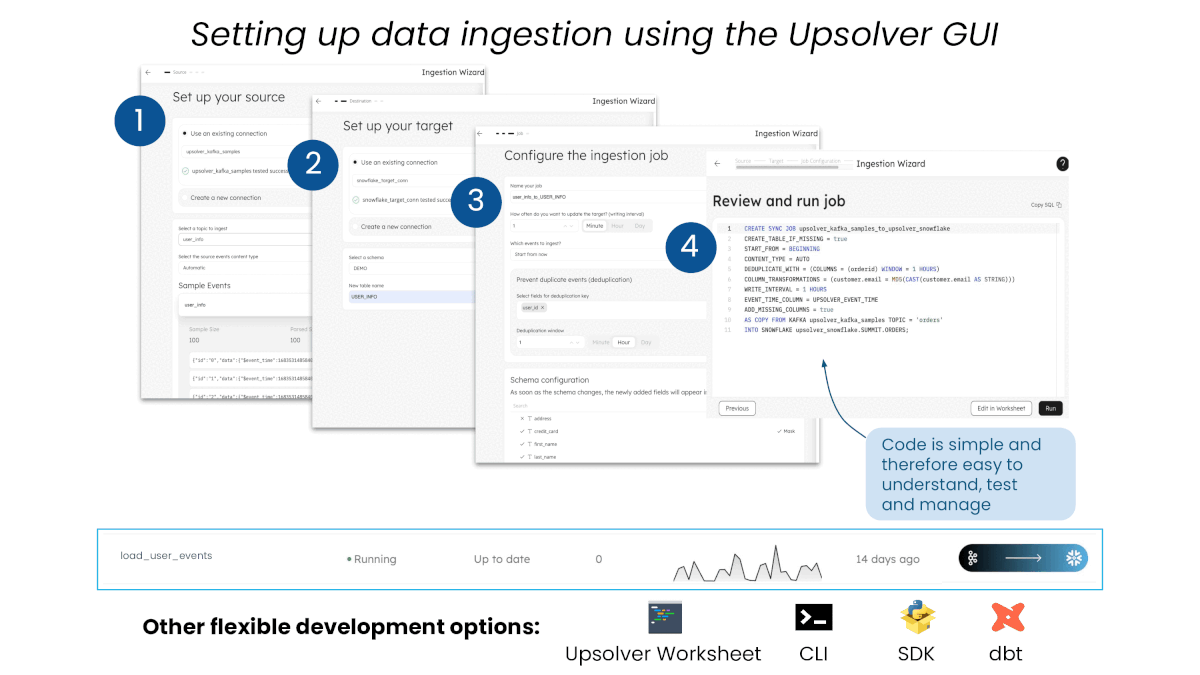
For no-code data ingestion, simply configure the desired source, target, and in-flight pre-processing steps, then launch the job—all from the UI.
Simple Upsolver SQL is automatically generated and ready for CI/CD. Edit the SQL in an Upsolver worksheet before launching the job, or write and execute dbt models using the dbt-connector, for a low-code experience.
For the full development experience, build your pipeline in an Upsolver worksheet or using the Upsolver CLI or Python SDK.
Built-in data quality and observability
Upsolver makes working with data easy by automatically mapping columns and data types between sources and targets, evolving the schema at pace with data even for nested data structures, and parsing and flattening arrays and JSON structs.
For everything else, there’s Upsolver Observability UI.
- Set quality expectations at row and column levels and decide how you want violations to be handled in any Upsolver pipeline.
- Detect data quality and pipeline issues in near real-time and set up alerting based on fully up-to-date systems tables.
Engineers ❤️ Upsolver



Designed for simplicity.
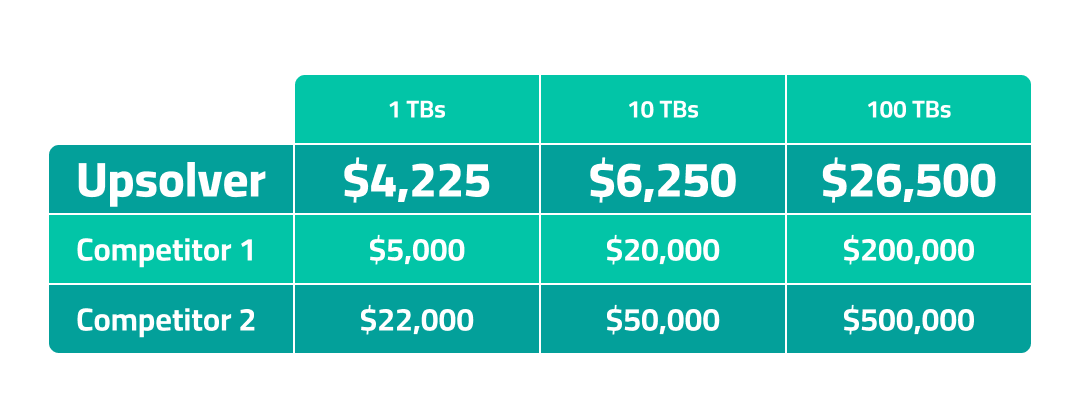
Priced for scale.
We don’t charge based on monthly active rows. Upsolver pricing is composed of a fixed software fee and a data volume rate that’s 1/10th the cost of other solutions.