
Explore our expert-made templates & start with the right one for you.
Upsolver November 2023 Feature Summary
-
Rachel Horder
- Release Notes
- November 9, 2023
Welcome to the November 2023 update. This release is packed full of new features, enhancements, and bug fixes. Read on to find out how these improvements will make ingesting your data even easier.
This update covers the following releases:
Contents
- UI
- Jobs
- SQL Queries
- Enhancements
UI
Ingestion Wizard Supports Confluent Cloud as a Source
Here at Upsolver we are committed to connecting to the industry’s most popular data sources and targets, and continue to build upon our list of supported platforms. We are delighted to announce that this release includes support for Confluent Cloud, following our recent participation in the Connect with Confluent (CwC) programme.
Use our Wizard to take the fast and easy route to building your pipelines from Confluent. Login to your Upsolver account and click on the New Job button to open the Wizard. Then select Confluent Cloud as your source, choose your target, and the Wizard will walk you through the steps to build your pipeline:
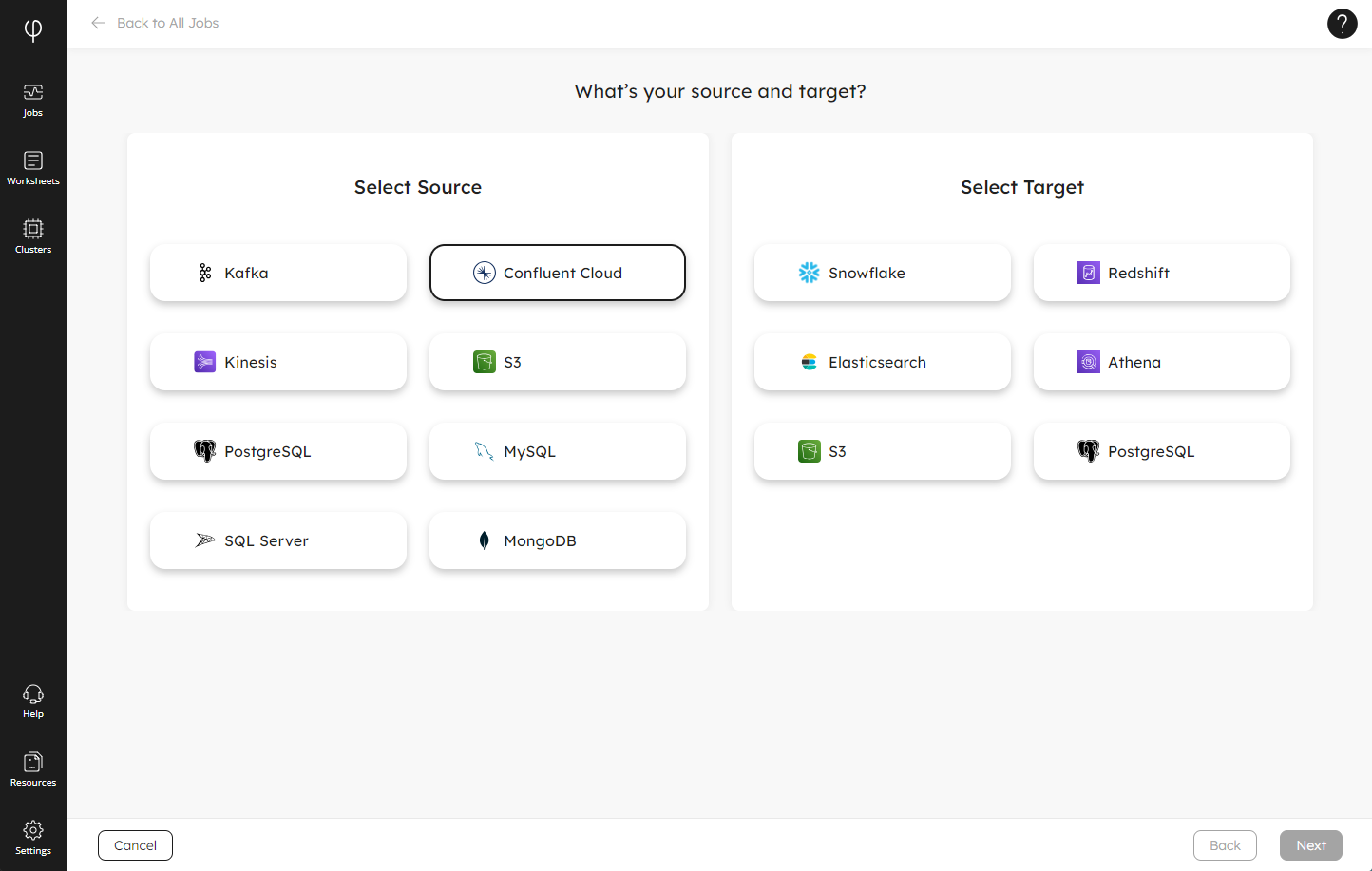
Alternatively, if you prefer to roll your own jobs, you can use our low-code option to create ingestion jobs using familiar SQL to copy your data from Confluent Cloud. Here’s an example of how to create your connection, staging table, and job to ingest your data into the staging table:
// 1. Create a connection to your Confluent Cloud account
CREATE CONFLUENT CONNECTION confluent_connection
HOSTS = ('bootstrap_server:port')
CONSUMER_PROPERTIES = '
bootstrap.servers=bootstrap_server:port
security.protocol=SASL_SSL sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule
required username="your_username"
password="your_password";
ssl.endpoint.identification.algorithm=https
sasl.mechanism=PLAIN';
// 2. Create a staging table
CREATE TABLE default_glue_catalog.upsolver_demo.confluent_raw_data()
PARTITIONED BY $event_date;
// 3. Create a streaming job to ingest data from your topic into the staging table
CREATE SYNC JOB load_data_from_confluent
START_FROM = BEGINNING
CONTENT_TYPE = JSON
AS COPY FROM CONFLUENT confluent_connection TOPIC = 'your_topic_name'
INTO default_glue_catalog.upsolver_demo.confluent_raw_data;Cancel Button Added to Stop Running Queries
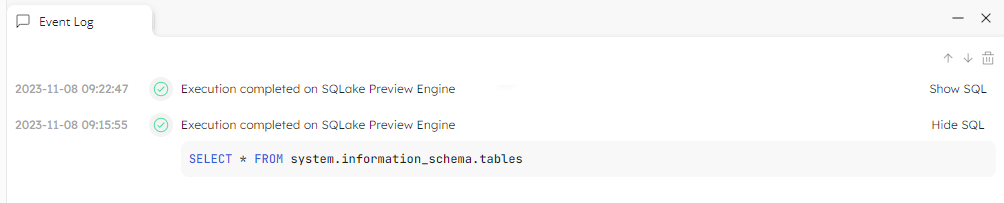
Running queries can now be stopped via the UI with a new Cancel button. You will find the Cancel button next to a running query in the Event Log tab at the bottom of your query window:

This is essential if your query is taking a lot longer to run than expected… and yes, we’ve all been there!
Jobs
SASL Support for Apache Kafka & Confluent Kafka Connections
We have added support for using the Simple Authentication and Security Layer (SASL) protocol when creating your Apache Kafka and Confluent Kafka connections in Upsolver. The connection supports setting the SASL username and password with the dedicated parameters SASL_USERNAME and SASL_PASSWORD:
CREATE CONFLUENT CONNECTION my_confluent_connection
HOSTS = ('foo:9092', 'bar:9092')
SASL_USERNAME = 'API_KEY'
SASL_PASSWORD = 'SECRET'
COMMENT = 'My new Confluent Cloud connection';Here are a couple of articles to help you get started with using this protocol: Wikipedia has an article on Simple Authentication and Security Layer, and the Confluent Developer site has a guide to Kafka Authentication with SSL and SASL_SSL.
Our documentation provides instructions and examples for creating your Apache Kafka and Confluent Cloud connections in Upsolver.
Ingestion Jobs Support Amazon S3 via SQS
You can now specify that Upsolver uses the SQS notifications sent by your S3 bucket to discover new files to be ingested. This is particularly useful when the data in the directory being read doesn’t have a predictable pattern that can be used to discover files, making the process inefficient. The following new options can be included in your jobs reading from Amazon S3:
USE_SQS_NOTIFICATIONS: Set this option toTRUE, so that Upsolver uses SQS notifications.SQS_QUEUE_NAME: Optionally specify the queue name to use, otherwise Upsolver creates an SQS queue and sets up bucket notifications to send messages to the queue.SQS_KMS_KEY: Optionally include the KMS key for reading from the SQS queue. This is only required if the SQS queue is set up with encryption.FILE_SUFFIX: Controls which file suffixes Amazon S3 will publish notifications for.
Check out the Upsolver documentation to see how to create an Amazon S3 job to ingest your data via SQS.
New Function REGEXP_EXTRACT
We have added a new function that finds the first match of the regular expression pattern in a string and returns the capturing group number as requested:
REGEXP_EXTRACT(string, pattern, group)If you exclude the group argument, this function returns the first substring matched by the regular expression pattern in the string. However, if the group argument is included, the function finds the first occurrence of the regular expression pattern in the string and returns the capturing group number group. So, for example:
REGEXP_EXTRACT('document.pdf', '.([^.]+)$')Returns ‘.pdf’
REGEXP_EXTRACT('1a 2b 14m', '(\d+)([a-z]+)','2')Returns ‘a’
For more examples, check out the REGEXP_EXTRACT reference in our documentation.
Fixed Apache Kafka Edit Number of Shards
When editing the number of shards in an Apache Kafka output job, Upsolver waits until the previous shards are completed before running the new shards.
SQL Queries
New System Table to View Running Queries
We’ve added another system table so you can see what queries are running in Upsolver’s query engine. The system.monitoring.running_queries table returns the SQL statement, start time, duration in milliseconds, the number of bytes scanned, and number of items scanned. To view running queries, open a worksheet in the Upsolver query editor and execute the following statement:
SELECT * FROM system.monitoring.running_queries;A quick tip… you can also use the Show SQL button in the Event Log tab in the query editor window to view a SQL statement for completed queries… however, this doesn’t provide the additional information you will discover in the running_queries table:
New ABORT QUERY Command
An alternative to using the Cancel button in the Event Log tab to stop running queries is to run our new ABORT QUERY command:
ABORT QUERY <query_id>;To find the query id that you will need to pass in to the command, you can run the following statement, using our new running_queries system table:
SELECT * FROM system.monitoring.running_queries; Copy and paste the query id from the results into the ABORT QUERY command, and execute the command to stop the query from running.
Query Engine Request Timeout Fixed
We fixed an issue in the query engine with requests timing out, so you should no longer encounter this problem.
Fixed Casting Issue Causing NULLs
Another bug that’s been fixed is the issue that was creating NULL values to appear when casting raw columns to multiple different types in the same query.
FLATTEN_PATH Case Sensitivity Issue Fixed
If you have utilized the FLATTEN_PATH function in your jobs and experienced a problem with columns not matching correctly due to case sensitivity between your source and target tables, then I’m pleased to tell you that our engineers have now fixed this. The problem was occurring with columns in a SELECT * statement, as per the basic example below:
CREATE SYNC JOB my_flatten_paths_job
FLATTEN_PATHS = (path1, path2, path3, ...)
AS INSERT INTO my_target_table
SELECT *
FROM my_source_table;From now on, column case-sensitivity should no longer be an issue. To learn more, please read the Flatten Arrays article in our documentation, which includes detailed examples.
Enhancements
New Monitoring Integration with Amazon CloudWatch & Datadog
I’m super excited to announce that we now support integration with Amazon CloudWatch and Datadog – a feature I know that many of you have been waiting patiently for. Both platforms support the monitoring of distributed applications, resources, and data, enabling you to observe your operations from a centralized place.
Within Upsolver, you can easily connect to your monitoring target and then create jobs to integrate your metrics, helping you to ensure the reliability and performance of your data pipelines.
Let’s take a look at an example. The following script creates a connection to Amazon CloudWatch:
CREATE CLOUDWATCH CONNECTION my_cloudwatch_connection
AWS_ROLE = 'arn:aws:iam::123456789012:role/upsolver-sqlake-role'
REGION = 'us-east-1'
COMMENT = 'CloudWatch connection for Upsolver metrics';We can then create a job to send our metrics to CloudWatch for monitoring, where we can visualize logs, create alerts, and automated actions:
CREATE JOB send_monitoring_data_cloudwatch
START_FROM = NOW
AS INSERT INTO my_cloudwatch_connection
NAMESPACE = 'upsolver'
MAP_COLUMNS_BY_NAME
SELECT utilization_percent AS utilization_percent,
tasks_in_queue AS tasks_in_queue,
memory_load_percent AS memory_load_percent,
cluster_id AS tags.cluster_id,
cluster_name AS tags.cluster_name,
RUN_START_TIME() AS time
FROM system.monitoring.clusters;Read more about Job Monitoring in our documentation, and learn how to create your connection and monitoring jobs for Amazon CloudWatch or Datadog.
If you’re not using either of these systems but want to find out more, the official Amazon CloudWatch page includes an introductory video, and the Datadog website shows you how to gain complete visibility into any dynamic environment.
New System Tables for Profiling Written Columns
The only thing more exciting than data is metadata and our engineers know how to keep us happy when it comes to profiling our pipelines! We have added two new system tables for viewing written column statistics:
- system.insights.dataset_column_stats provides detailed statistics about the columns in your datasets that you ingest to your targets. Use for data profiling, query optimization, and monitoring schema changes.
- system.insights.job_output_column_stats displays insights on columns in your Upsolver output jobs. Understand your outputs, and the transformations applied to columns and data, and troubleshoot issues.
To view your written columns, open a blank worksheet in the Upsolver query editor and run the following:
SELECT * FROM system.insights.dataset_column_stats;
SELECT * FROM system.insights.job_output_column_stats;Each system table includes the column type, density, count, minimum and maximum distinct values, value distribution, and first and last seen, and a whole lot more. You may wish to limit or filter the results if you have hundreds of columns across numerous datasets. For example, restrict the number of rows returned using LIMIT, specifying the count of rows you want returned without filtering:
SELECT * FROM system.insights.dataset_column_stats LIMIT 25;
SELECT * FROM system.insights.job_output_column_stats LIMIT 50;Alternatively, return the insights from the dataset_column_stats table for a single dataset:
SELECT * FROM system.insights.dataset_column_stats
WHERE dataset = 'upsolver_samples.orders_raw_data';Or return the insights from the job_output_column_stats table for a job – you can use either the job name or id in the WHERE clause:
SELECT * FROM system.insights.job_output_column_stats
WHERE job_name = 'load_orders_to_target';
SELECT * FROM system.insights.job_output_column_stats
WHERE job_id = 'd6f1bd65-a6bb-44d0-a0a8-3bd6cd058295';We also fixed… If you have already queried these tables to view stats on your Snowflake data and encountered a problem with inconsistent catalog names, you will be pleased to know that this is now fixed.
Cloud Integration in Your New Organization
To improve the onboarding experience when you create your trial account we now run your pipelines in our Upsolver cloud by default. There is no difficult configuration to battle with when you sign up for your trial account, simply use our sample data to create pipelines in our cloud and explore the features and benefits of using Upsolver.
If you want to deploy Upsolver to your VPC, you can do this from the UI. From the main menu, click Settings, then select Cloud Integration. Read the requirements and FAQs, then click Start Integration when you’re ready to begin deployment:
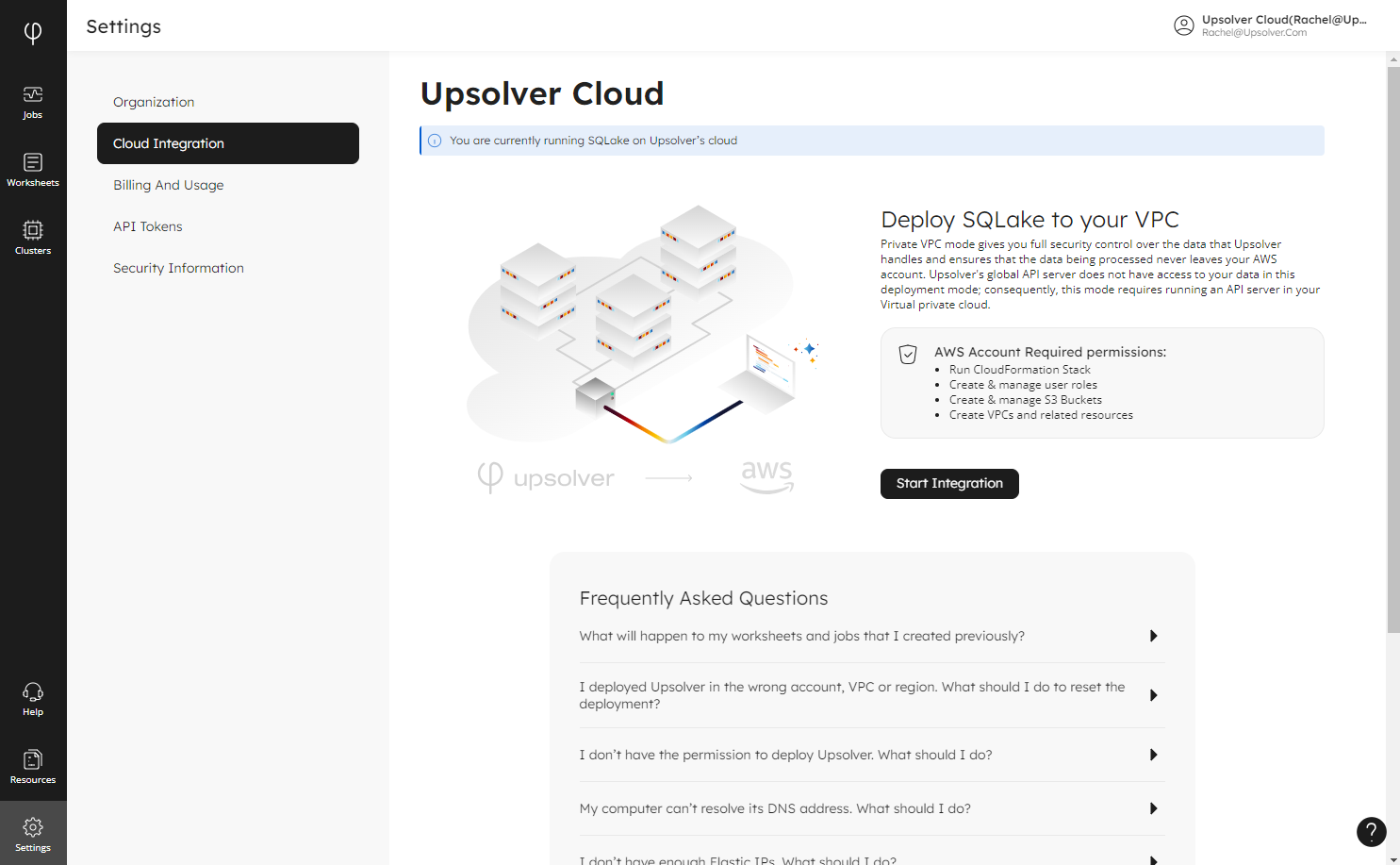
The deployment wizard will take you through the steps to integrate Upsolver with your AWS account:
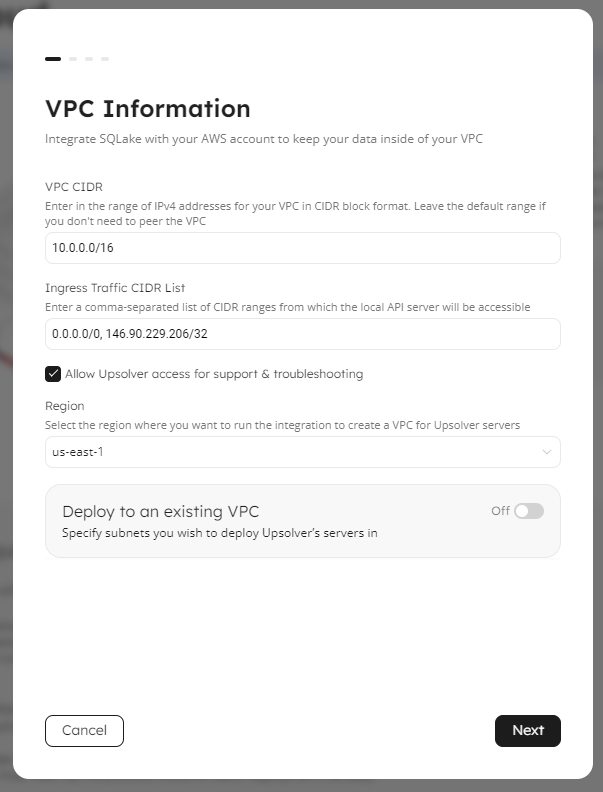
If you run into problems, click the Help icon on the main menu and select Chat with support and we will be happy to help.
Improved Redshift Replay Performance
For customers who experienced performance problems when conducting either the initial processing or replay of outputs to Amazon Redshift, we have now made great efforts to improve performance.
Improved system.monitoring.jobs Table Performance
On the subject of performance issues, we have also improved query performance when selecting from the system.monitoring.jobs table, so you should now notice a difference when querying this table.
That’s it for November. I hope you found this useful for discovering the new features and enhancements. We’re working super hard to continually add value and I’ll see you again next month with another update on what we’ve released.
If you’re new to Upsolver, why not start your free trial, or schedule a no-obligation demo with one of our in-house solutions architects who will be happy to show you around.
Published in:
Blog
,
Release Notes